打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
1. Milvus简介
Milvus 是一款开源的向量相似度搜索引擎,支持向量的增删改操作和近实时查询。可以广泛应用于向量搜索相关的各个领域:
l 图像、视频、音频等音视频搜索领域
l 文本搜索、推荐和交互式问答系统等文本搜索领域
l 新药搜索、基因筛选等生物医药领域
Milvus 集成了 Faiss、NMSLIB、Annoy 等广泛应用的向量索引库,可以针对不同场景选择不同的索引类型。
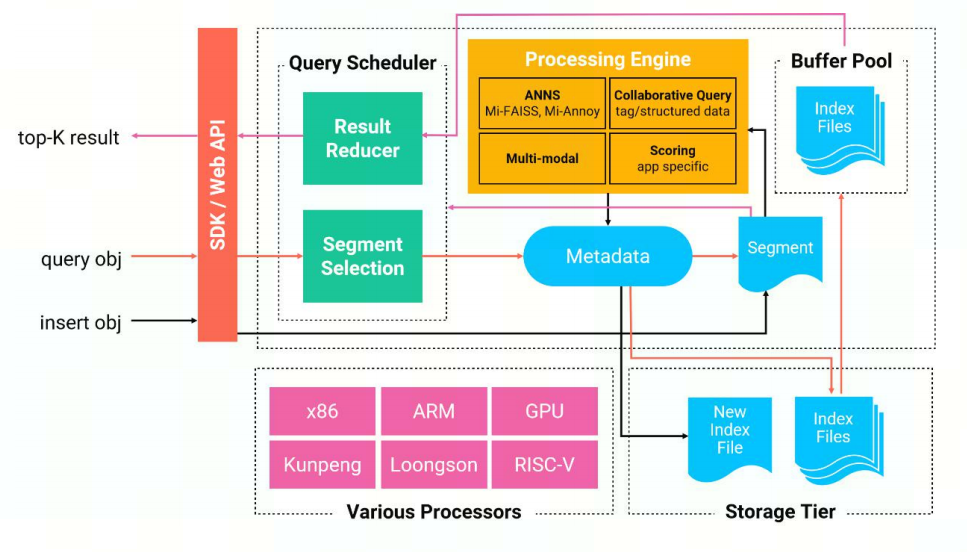
Milvus 服务器采用主从式架构 (Client-server model)。
l 在服务端,Milvus 由 Milvus Core 和 Store 两部分组成:
Milvus Core 存储与管理向量和标量数据。
Store 存储与管理 SQLite 和 MySQL 中的元数据,分别用于测试和生产。
l 在客户端,Milvus 还提供了基于 Python、Java、Go、C++ 的 SDK 和 RESTful API。
下图是 milvus 整体结构图:
图 1.1 Milvus整体架构图
2. Milvus基本概念
2.1 向量索引
向量索引(vector index)是指通过某种数学模型,对向量构建的一种时间和空间上更高效的数据结构。
Milvus 目前支持的向量索引类型大都属于 ANNS(Approximate Nearest Neighbors Search,近似最近邻搜索)。ANNS 的核心思想是不再局限于只返回最精确的结果项,而是仅搜索可能是近邻的数据项,即以牺牲可接受范围内的精度的方式提高检索效率。
Milvus目前主要支持FLAT/IVF_FLAT/IVF_SQ8/IVF_SQ8H/IVF_PQ/RNSG/HNSW/ANNOY 等 索引类型。
下表将目前 Milvus 支持的索引进行了归类:
表 2.1 Milvus支持的索引类型
Milvus 支持的索引 | 索引分类 | 适用场景 |
N/A | 查询数据规模小,对查询速度要求不高。 需要 100% 的召回率。 | |
基于量化的索引 | 高速查询, 要求尽可能高的召回率。 | |
基于量化的索引 | 高速查询, 磁盘和内存资源有限, 仅有 CPU 资源。 | |
基于量化的索引 | 高速查询, 磁盘、内存、显存有限。 | |
基于量化的索引 | ||
基于图的索引 | ||
基于图的索引 | ||
基于树的索引 | ||
2.2 距离计算方式
Milvus 基于不同的距离计算方式比较向量间的距离。选择合适的距离计算方式能极大地提高数据分类和聚类性能。
Milvus 目前主要支持欧式距离(L2)和内积(IP)的距离计算方式:

2.3 存储相关概念
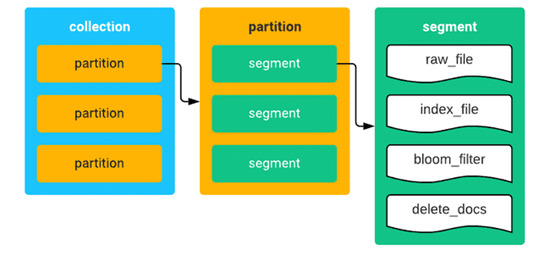
Milvus 提供分区功能,你可以根据需要将数据划分为多个分区。对数据的合理组织和划分可以有效提高查询性能。为了能处理海量的数据,Milvus 会将数据分段,每段数据拥有数万甚至数十万个实体。每个数据段的数据又按照字段(field)分开,每个字段的数据单独存为一个数据文件。目前的版本中,集合中的每条 Entity 包含一个 ID 字段、一个向量字段,以及多个标量字段。当一个集合累积了大量数据之后,查询性能会逐渐下降。而某些场景只需查询集合中的部分数据,这时就要考虑把集合中的数据根据一定规则在物理存储上分成多个部分。这种对集合数据的划分就叫分区。每个分区可包含多个数据段。集合、分区以及数据段的关系如下所示:
图 2.2 Milvus 存储概念图
3. MLU移植情况
MLU 移植基于 milvus 最新 0.11.1 版本。在服务端,目前 MLU 适配了 PQ 向量索引类型。由于原生 Milvus 未支持单独的 PQ 索引类型,将 MLU PQ 作为原生 Milvus 中 IVFPQ 索引的 special case 进行集成适配(基于 L2 距离)。
PQ 乘积量化的核心思想是聚类,通过将一个完整的向量空间用其中的一个有限子集来进行编码达到压缩的目的,算法关键在于码本的建立和码字搜索算法。PQ 乘积量化生成码本和量化的过程可以用如下图示来说明:
图 3.1 PQ 训练生成码本和量化的过程
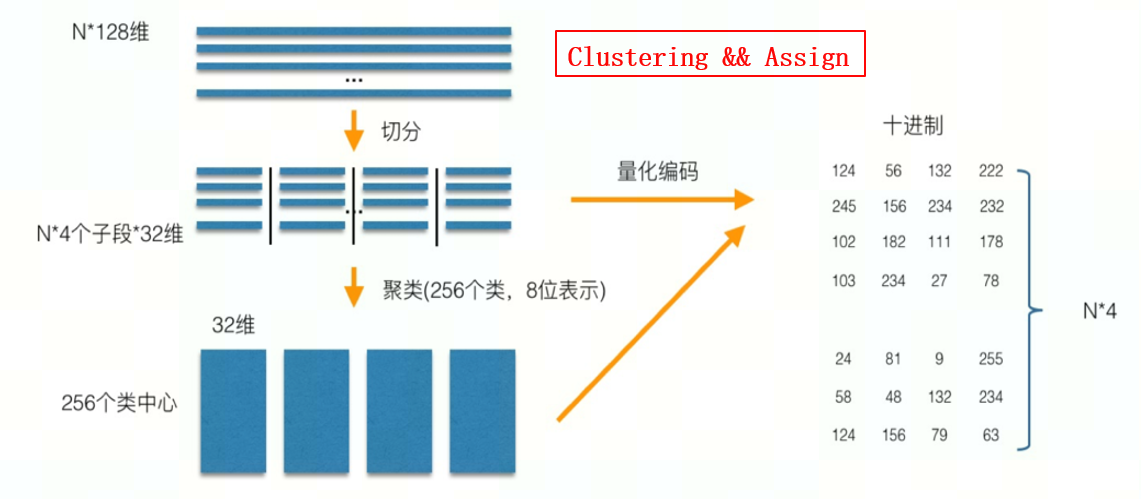
在训练阶段,针对 N * 128 的向量空间,将其切分为 4 个子空间,每一个子空间的维度为 32 维。在每一个子空间中,对子向量采用 K-Means 对其进行聚类(图中示意聚成 256 类),每一个子空间都会得到一个 256*32 维的码本(聚类中心)。这样训练样本的每个子段,都可以用子空间的聚类中心来近似,对应的编码即为类中心的 ID。。对于待编码的样本,同样将它进行相同的切分,然后在各个子空间里逐一找到距离它们最近的类中心,然后用类中心的 id 来表示它们,即完成了待编码样本的编码。在查询阶段,一般采用损失较小的非对称距离作为距离计算方式,PQ 乘积量化生查询过程可以用如下图示来说明:
图 3.2 PQ 查询搜索的过程
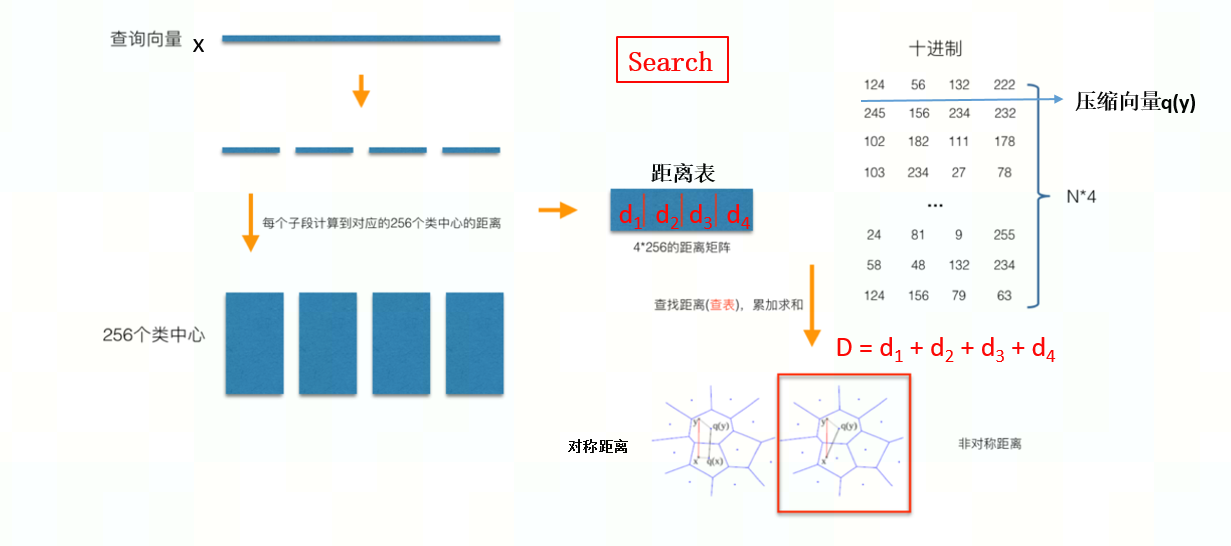
按训练样本生成码本的过程,将其同样分成相同的子段,然后在每个子空间中,计算子段到该子空间中所有聚类中心得距离,如图中所示,可以得到 4*256 个距离,把这些算好的距离称作距离池。在计算库中某个样本到查询向量的距离时,比如编码为(124, 56, 132, 222)这个样本到查询向量的距离时,分别到距离池中取各个子段对应的距离,比如编码为124这个子段,在第 1 个算出的 256 个距离里面把编号为 124 的那个距离取出,所有子段对应的距离取出来后,将这些子段的距离求和相加,即得到该样本到查询样本间的非对称距离。所有距离算好后,排序得到最终结果。在目前的适配条件下,对于数据的存储、插入、删除,PQ 索引的创建,码本训练等操作,使用 CPU 完成。MLU270 通过 bangc 实现了 PQ 和 TOPK 的核心算法,以支持向量的搜索查询。可以在同一时间内使用 CPU 建立、训练索引,使用 MLU 搜索查询向量。也可以同时使用 CPU 和 MLU 进行查询,支持 MLU 多卡进行查询任务,SearchTask 会均匀分发到不同的设备,可在 milvus.yaml 配置文件中配置资源。在客户端,完成 Python、C++ 的 SDK API 的适配和集成,对应 c++ sdk 对应 milvus 0.11.1
版本,python sdk 对应 pymilvus 0.4.0 版本。支持在 Ubuntu LTS 18.04 Docker 启动 Milvus 服务。
4. MLU移植情况
Benchmark 测评采用 SIFT1B 数据集,包含超过 10 亿条不同种类的数据和不同大小的特 征向量,是已知用于评估 ann 算法的最大集合。使用该数据集的子集 ANN_SIFT1M(包含 100 万条特征向量),ANN_SIFT10M(包含 1000 万条特征向量)进行测评。 准确率测试从 10,000 条查询向量中随机取出 300 条向量,查询这 300 条向量在数据集 中各自的 top1, top10,top50, top100,得到的召回率统计。 性能测试从 10,000 条查询向量中随机取出 500 条向量,通过 python api 召回的总时间, 得到 500 条查询平均时间。 以下是召回准确率和 CPU/MLU 对比性能数据的概要 MLU 使用单卡 MLU270 S-4,CPU 使 用 8 核 Intel(R) Xeon(R) Gold 5218 CPU @ 2.30GHz,基于 MLU PQ 索引(原 IVFPQ 的 special case, L2 距离计算方式):
表 4.1 Benchmark召回准确率
| nlist=1, nprobe=1, m = 32, nbits=8, dim=128, segment_row_limit = 100w/1000w ,nq = 300 | ||||
| accuracy | topk=1 | topk=10 | topk=50 | topk=100 |
| ANN_SIFT1M | 68.7% | 74.5% | 79.2% | 81.4% |
| ANN_SIFT10M | 59.0% | 70.6% | 75.0% | 77.2% |
表 4.2 Benchmark MLU270 单卡性能(python api e2e)
| nlist=1, nprobe=1, m = 32, nbits=8, dim=128, segment_row_limit = 100w/1000w | |||||
| Time(ms) | topk=1 | topk=10 | topk=50 | topk=100 | cpu占用率 |
| ANN_SIFT1M | 2.182 | 2.259 | 2.318 | 2.363 | 5busy |
| ANN_SIFT10M | 16.537 | 17.296 | 18.314 | 19.711 | |
表 4.3 Benchmark CPU 性能(python api e2e)
| nlist=1, nprobe=1, m = 32, nbits=8, dim=128, segment_row_limit = 100w/1000w | |||||
| Time(ms) | topk=1 | topk=10 | topk=50 | topk=100 | cpu占用率 |
| ANN_SIFT1M | 3.181 | 3.230 | 3.188 | 3.293 | 5busy |
| ANN_SIFT10M | 15.532 | 15.641 | 16.120 | 16.848 | |
热门帖子
精华帖子





 Ashelly
13 回复
Ashelly
13 回复
 fengyunkai
1 回复
fengyunkai
1 回复
 三叶虫
3 回复
三叶虫
3 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读