打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
知乎链接:https://zhuanlan.zhihu.com/p/621812747
视频:https://space.bilibili.com/555233120
博文:https://www.zhihu.com/column/c_1531055529060831232
代码:https://gitee.com/yifanrensheng/deep_learning_for_cv
文章概述:主要介绍 CNN 网络发展,重点讲述了搭建 CNN 网络的组件:卷积层,池化层,激活层和全连接层。
卷积神经网络(Convolutional Neural Networks,CNN)属于神经网络的一个重要分支。应用于CV,NLP等的各个方面。
1962年,Hubel和Wiesel对猫大脑中的视觉系统的研究。
1980年,日本科学家福岛邦彦在论文 NeoCognitron 中提出了包含卷积和池化的神经网络结构。
1998年,Lecun发明了LeNet,网络结构比较完整,包括卷积层、pooling层、全连接层,这些都是现代CNN网络的基本组件。
2012年AlexNet由Hinton的学生Alex Krizhevsky提出,并在当年取得了Imagenet比赛冠军。AlexNet可以算是LeNet的一种更深更宽的版本,证明了卷积神经网络在复杂模型下的有效性,算是神经网络在低谷期的第一次发声,确立了深度学习,或者说卷积神经网络在计算机视觉中的统治地位。
2014年,VGGNet是牛津大学计算机视觉组和Google DeepMind公司一起研发的深度卷积神经网络,在2014年的 ILSVRC localization and classification 两个问题上分别取得了第一名和第二名,常用的是VGG16,VGG19网络。
2014年GoogLeNet,提出的Inception结构是主要的创新点,性能比AlexNet要好;2014年ILSVRC冠军。
2015年,ResNet(残差神经网络)由微软研究院的何凯明,孙健等4名华人提出,成功训练了152层超级深的卷积神经网络,效果非常突出,而且容易结合到其他网络结构中。对应的论文应用量极大,且后续的网络大多基于残差的思想构造而来。
2017 SENet,ILSVRC竞赛2017年第一名;后面还有MobileNet,ShuffleNet,EfficientNet等。
1)传统神经网络参数巨大 VS CNN的参数共享机制
① 参数更少
比如1920*1080图片采用1000的隐层连接,需要参数量为:1920*1080*1000 ≈ 207360 万个参数;
而使用卷积神经网络,同样输出1000,使用卷积核 3*3大小,一共3*3*1000 = 0.9 万个参数。
② 平移不变性:由于filter的参数共享,即使图片进行了一定的平移操作,我们照样可以识别出特征。因此,模型就更加稳健了。
2)局部感受野
局部范围内的像素之间联系较为紧密,而距离较远的像素则相关性较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。而且每一个区域都有自己的专属特征,我们不希望它受到其他区域的影响。
一般而言,CNN主要由以下层构造而成:
卷积层:Convolutional (CONV)
池化层:Pooling (POOL)
激活层:Activation
全连接层:Fully Connected (FC)
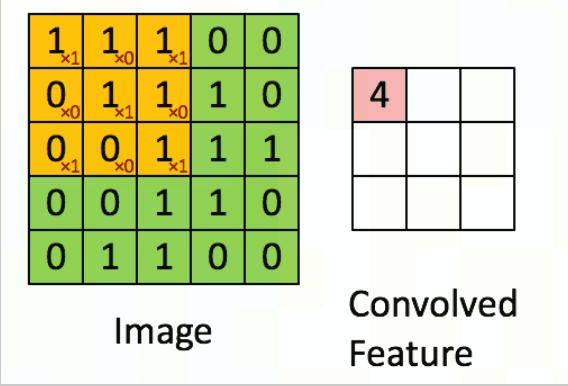
CNN 中最为重要的部分,而卷积其实主要的就是用对应的卷积核(下图左侧黄色)在被卷积矩阵上(下图左侧绿色)移动做乘法和加法得到提取后的特征(如下图右侧)。
常用的卷积(Conv2d)在pytorch中对应的函数是:
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
in_channels (int) – 参数代表输入特征矩阵的深度即channel,比如输入一张RGB彩色图像,那in_channels=3
out_channels (int) – 参数代表卷积核的个数,使用n个卷积核输出的特征矩阵深度即channel就是n
kernel_size (int or tuple) – 参数代表卷积核的尺寸,输入可以是int类型如3 代表卷积核的height=width=3,也可以是tuple类型如(5, 3)代表卷积核的height=5,width=3
stride (int or tuple, optional) – 参数代表卷积核的步距默认为1,和kernel_size一样输入可以是int类型,也可以是tuple类型
padding (int, tuple or str, optional) – 参数代表在输入特征矩阵四周补零的情况默认为0,同样输入可以为int型如1 代表上下左右补一圈0,如果输入为tuple型如(2, 1) 代表在上方补两行下方补两行,左边补一列,右边补一列。padding[0]是在H高度方向两侧填充的,padding[1]是在W宽度方向两侧填充的。如果要实现更灵活的padding方式,可使用nn.ZeroPad2d方法。
dilation (int or tuple, optional)– 空洞卷积,参数代表kernel内的点(卷积核点)的间距,默认为1,取值方式类似padding。
bias (bool, optional) – 参数表示是否使用偏置(默认使用)
groups (int, optional) – 分组卷积的组数,能减少参数和正则化效果。默认为1,也即都在1个组内。
以上很多参数会影响对应的输出特征大小。

【图片截取自pytorch官网】
注意:pytorch的图片载入tensor的顺序:[ Batch,Channel,Height,Width ]
实际应用中,dilation相对较少,因此特征图的边长公式一般可以简化如下:
其中:
W是输入的图像的宽度
F是卷积核大小,一般是 F × F
P是填充值
S是步长
说明:当所得N为非整数时,我们采用向下取整(等于小于自己的最大整数)的方式进行。
1)通道影响
一般卷积过程如下图所示,其中:
输入的图像的宽度 W = 5
卷积核 F = 3
填充值 P = 1
步长 S = 2
输出的特征 N = 3
初始通道数 3;输出通道数:2
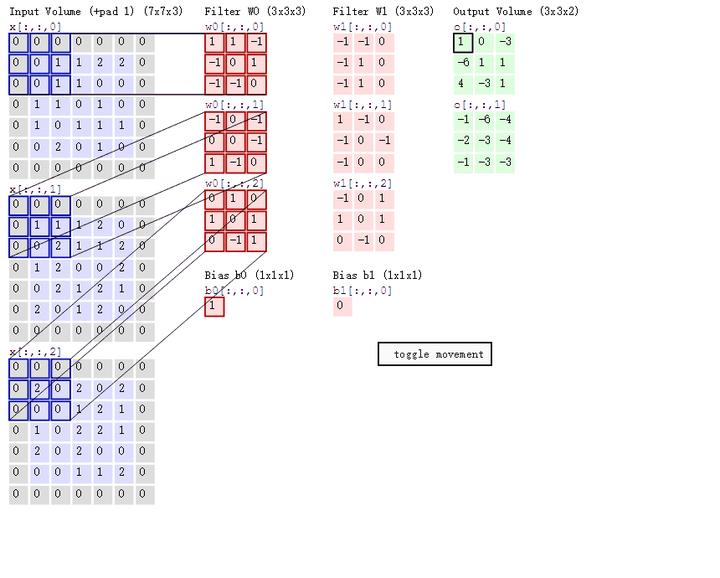
① 对于输出宽度,再校验一次上述公式:
② 对于最终的特征值的数量为2个,这个根据卷积核的组数决定的,也即中间红色部分是两列。若是想得到更多特征数量,可以增加卷积核的组数来控制。
2)训练中参数计算
假设卷积核大小为 n*m,输入时有C个通道(channels)/维度,而选用的"卷积核/filter"有K个,再加上1个bias,可以得到引进的参数有:
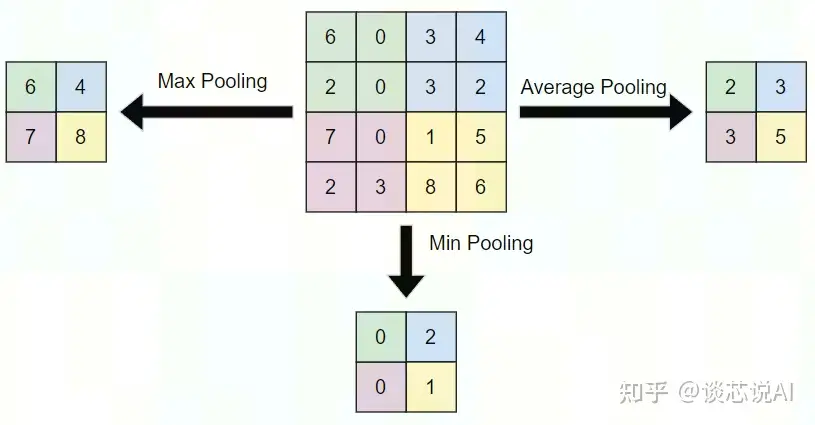
池化层不改变三维矩阵的深度,可以缩小矩阵的大小。池化操作可以认为是将一张分辨率高的图片转化为分辨率较低的图片。通过池化层,可以进一步缩小最后全连接层中节点的个数,从而到达减少整个神经网络参数的目的。池化层本身没有可以训练的参数。一般有三种池化策略:
最大池化:把卷积后函数区域内元素的最大值作为函数输出的结果,对输入图像提取局部最大响应,选取最显著的特征。
平均池化:把卷积后函数区域内元素的算法平均值作为函数输出结果,对输入图像提取局部响应的均值。
最小池化:把卷积后函数区域内元素的最小值作为函数输出的结果,对输入图像提取局部最小响应,选取最小的特征(一般不用,因为现在使用大多是 relu激活,使用最小池化,会导致无意义)。如下图。
1)PyTorch 接口和公式
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
kernel_size (int or tuple) – 参数代表移动的窗口尺寸
stride (int or tuple, optional) – 参数代表窗口移动的步距默认为 kernel_size
padding (int, tuple or str, optional) – 参数代表在输入特征矩阵四周补零的情况默认为0,同样输入可以为int型如1 代表上下左右补一圈0,如果输入为tuple型如(2, 1) 代表在上方补两行下方补两行,左边补一列,右边补一列。可见下图,padding[0]是在H高度方向两侧填充的,padding[1]是在W宽度方向两侧填充的。如果要实现更灵活的padding方式,可使用nn.ZeroPad2d方法。
dilation (int or tuple, optional)– a parameter that controls the stride of elements in the window类似卷积中的空洞数量,默认为1 。
return_indices (bool) – if True, will return the max indices along with the outputs. Useful for torch.nn.MaxUnpool2d later。
ceil_mode (bool) – when True, will use ceil instead of floor to compute the output shape,ceil向上取整数(即不小于该值的最大整数),否则向下取整(默认为该形式)。

实际应用中,dilation相对较少,因此特征图的边长公式一般可以简化如下:
热门帖子
精华帖子





 Ashelly
13 回复
Ashelly
13 回复
 fengyunkai
1 回复
fengyunkai
1 回复
 三叶虫
3 回复
三叶虫
3 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读