打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
知乎链接:https://zhuanlan.zhihu.com/p/614071148
若是初学者,建议先初级部分,本次的主要内容:
主要内容:CNStream 概述,框架,内置模块以及工具。
主要目的:对 CNStream 整体框架,内部模块功能及其自定义参数,以及工具有初步的了解。
依赖的知识点:了解寒武纪硬件平台,对寒武纪基础软件CNToolkit,CNCV,MagicMind有概念,了解基础的图像和人工智能相关知识。
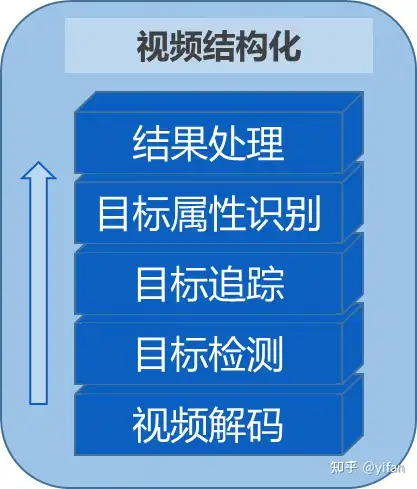
CNStream 是面向寒武纪开发平台的数据流处理 SDK。用于快速搭建基于寒武纪硬件平台的人工智能应用。比如目标检测,视频结构化等等。图片所示为一个典型的视频结构化应用,包括解码,目标检测,目标追踪,目标属性识别以及结果处理。
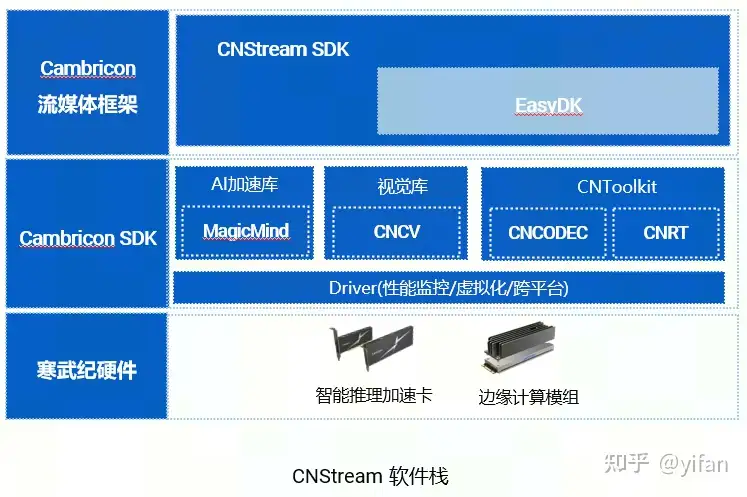
1)cnstream的软件栈
在cnstream之上的是用户应用。cnstream依赖于easydk(Easy development kit),easydk是基于寒武纪基础软件包开发的一套工具包,以子仓的形式存在于CNStream仓库中。同时,cnstream依赖于MagicMind,CNCV,CNCodec,CNRT等寒武纪基础软件包。最底层则是driver,kernel。
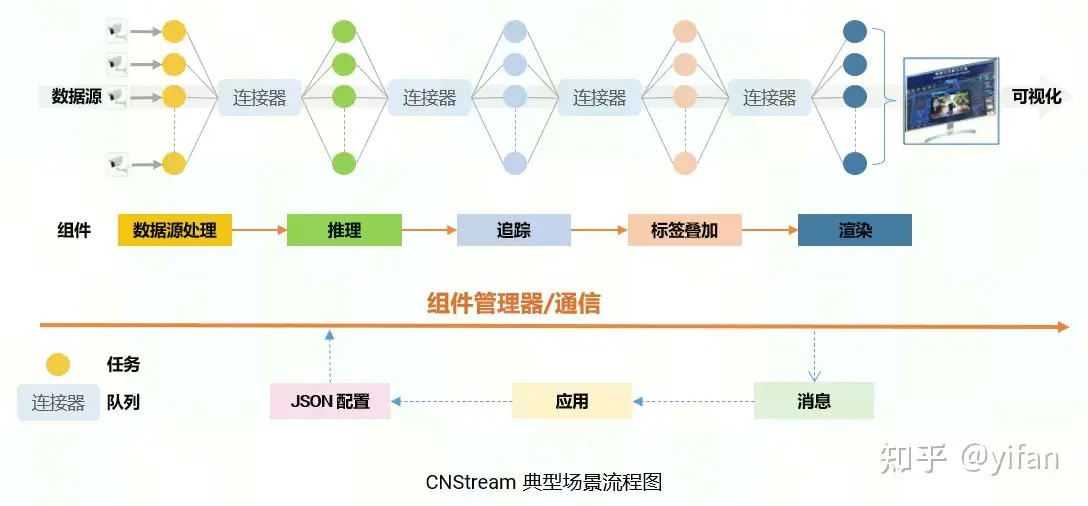
2)典型场景流程图
对数据流依次进行解码,推理,追踪,编码和渲染。首先通过json配置文件,构建一条如上所述的pipeline。数据流解码后,数据帧被推到下游队列中,随后,推理插件从上游队列中拿取到解码后的数据,进行推理,推理结束后再将数据推入下游队列,依此类推。数据帧在pipeline中流动,依次被每个插件处理。当视频流处理结束后,或发生异常时,应用将拿到pipeline发给应用的消息,并进行相应的处理。
3)配置文件
CNStream支持通过配置文件搭建pipeline。
例如一个目标检测业务的Json配置,通过profiler_config配置是否对pipeline进行profile或trace,主要用于性能统计及调优。
{
"profiler_config" : {
"enable_profiling" : true,
"enable_tracing" : true
},
"source" : {
"class_name" : "cnstream::DataSource",
"next_modules" : ["detector"],
"custom_params" : {
"bufpool_size" : 16,
"interval" : 1,
"device_id" : 0
}
},
"detector" : {
"class_name" : "cnstream::Inferencer",
"next_modules" : ["osd"],
"parallelism" : 1,
"max_input_queue_size" : 10,
"custom_params" : {
"model_path" : "../../../data/models/yolov3_v0.13.0_4b_rgb_uint8.magicmind",
"preproc" : "name=PreprocYolov3;use_cpu=false",
"postproc" : "name=PostprocYolov3;threshold=0.5",
"batch_timeout" : 200,
"engine_num" : 4,
"model_input_pixel_format" : "RGB24",
"device_id" : 0
}
}
"osd" : {
"class_name" : "cnstream::Osd",
"next_modules" : ["venc"],
"parallelism" : 1,
"max_input_queue_size" : 10,
"custom_params" : {
"label_path" : "../../../../data/models/label_map_coco.txt"
}
},
"venc" : {
"class_name" : "cnstream::VEncode",
"parallelism" : 1,
"max_input_queue_size" : 10,
"custom_params" : {
"rtsp_port" : 9554,
"device_id": 0
}
}}其他四个部分为pipeline的组成模块,起始模块source,class_name为模块类名,这里用到反射机制,所以我们可以知道source是一个DataSource模块,负责获取输入流并解码。next_modules指向本模块的下游模块,即detector。custom_params则是每个模块的自定义参数,例如device_id代表设备号。
detector的class_name是Inferencer即推理,parallelism代表模块的并行度,但由于DataSource模块为起始模块不由pipeline调度,DataSource模块无需设置该参数。detector指向下游模块osd做标签叠加。osd又指向下游模块venc做编码。
使用CNStream提供的接口pipeline::BuildPipelineByJSONFile,传入这个Json配置文件,将得到一条目标检测pipeline。
CNStream 子仓 EasyDK(Cambricon Easy Development Kit)提供了一套面向寒武纪硬件设备的接口,用于面向寒武纪硬件平台快速开发和部署人工智能应用。
EasyDK支持如下特性:
BufSurface:描述及管理buffers
Decode:视频与图片的硬件解码和缩放
Encode:视频与图片的硬件编码和缩放
Transform:基于CNCV(寒武纪计算机视觉库)的图片转换,包括:
YUV420spToRGBx, Resize, ROI, (可选 MeanStd)
RGBxToYuv420sp, ROI
Yuv420spResize, ROI
MeanStd
InferServer:提供了一套类似服务器的推理接口,以及模型加载与管理,推理任务调度等功能。
支持同步异步请求推理
支持自定义前处理,后处理。可使用CnedkTransform接口加速前处理
支持加载可变模型,但对于输入可变模型,需要在加载模型时给定输入形状
不支持绑核
CNStream对EasyDK的依赖:
CNStream中的图片数据帧保存在BufSurface中
DataSource模块基于Decode
VEncode模块基于Encode
Inference模块基于InferServer
预处理示例基于Transform
CNStream 基于模块化和流水线的设计思想,模块之间相互连接形Pipeline,并使用事件总线实现事件监听。下图是一个pipeline示例,Module之间相互连接形成pipeline。支持分叉和汇聚的情况。使用离线模型,直接运行加速后的MLU机器指令。cnstream支持多种并行模式,拥有高效的数据处理能力。
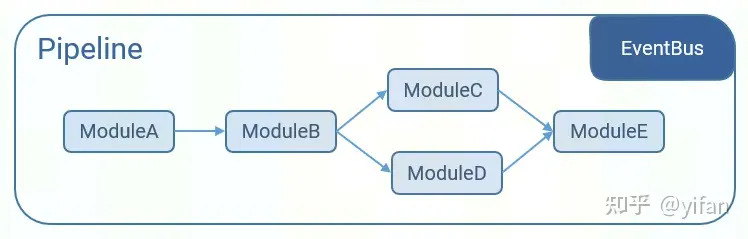
CNStream分为三个层次:应用、模块库和框架
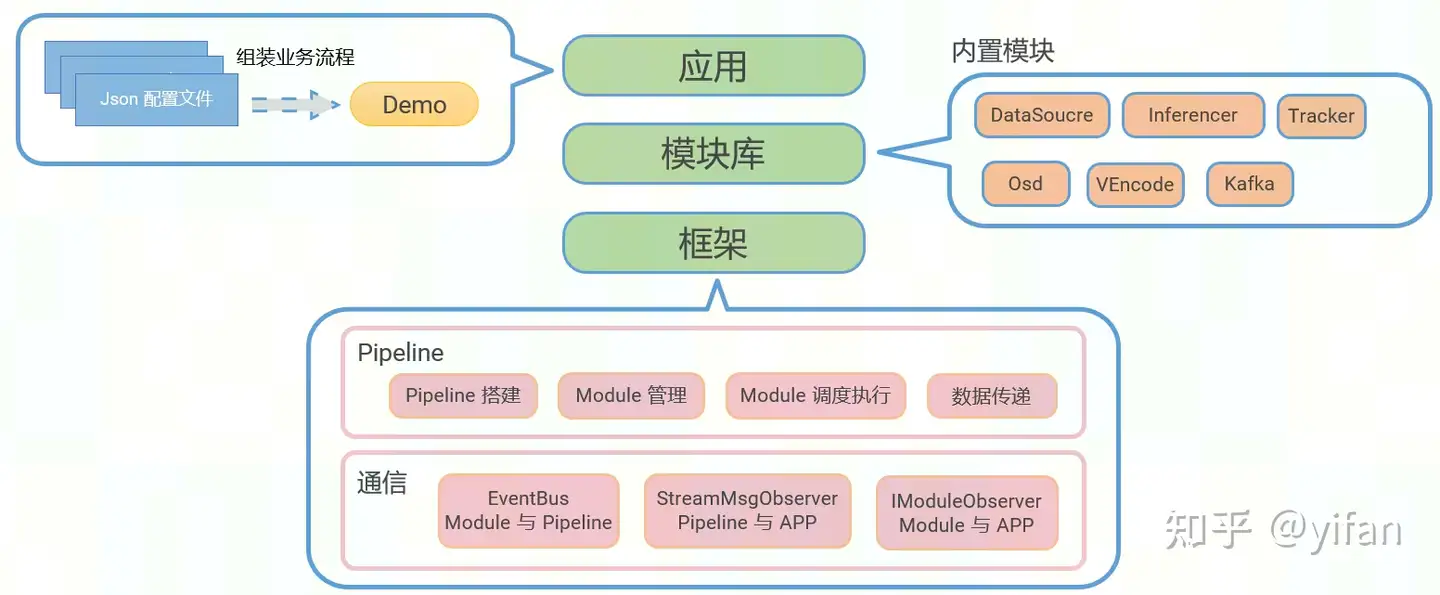
应用app主要实现了业务流程的组装。可以通过json配置文件搭建pipeline。
模块库,cnstream提供的内置模块有以下几个,我们将在后续章节详细展开。
框架层,主要有两大机制,pipeline和通信。pipeline实现了,pipeline搭建,module调度执行,模块间数据传递等。通信机制主要有,EventBus,StreamMsgObserver和IModuleObserver。分别实现了模块和pipeline,pipeline和app以及模块和app之间的通信。
模块的基类module。内置模块全部继承于module基类。
pipeline类主要功能时管理模块,调度执行任务以及模块间的数据传递。
connector连接器,是模块之间数据传递的载体。
cn info是数据基本单元,包含图像数据及结构化信息等等,模块间传递的数据,既是cn info的智能指针(shared_ptr)。
通信机制:EventBus用于module与pipeline通信; StreamMsgObserver用于pipeline与app通信以及IModuleObserver用于module与app通信。
1)Module
module的功能实现有以下三个方法,Open,Process和Close。
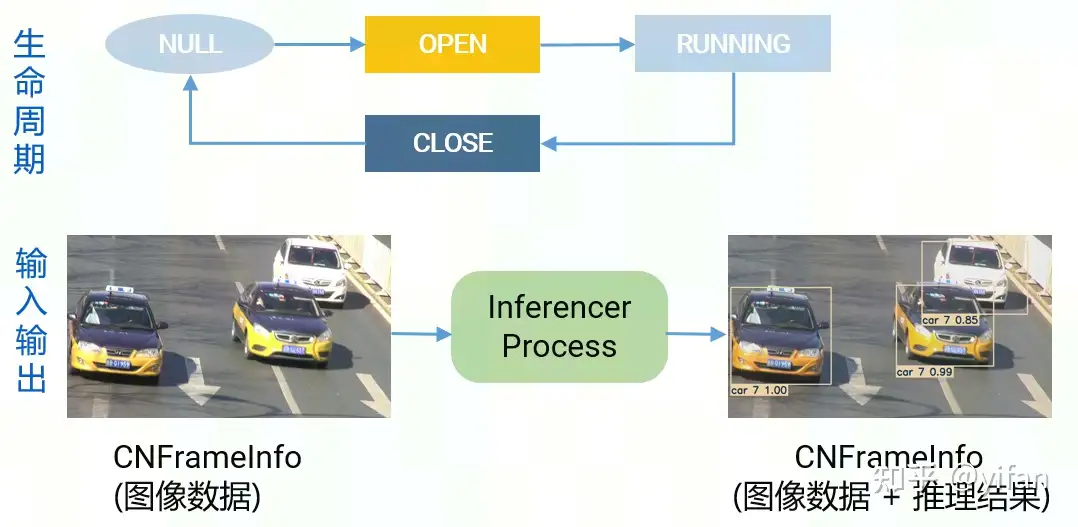
模块的生命周期:
首先实例化一个模块,然后调用Open函数,初始化模块,加载资源。
接着重复调用Process函数,处理数据CN Info,直到Close方法被调用,close方法会对加载的资源进行清理。
Process函数是模块的主要处理逻辑实现。它的输入和输出都是cn info的智能指针。以推理inferencer插件为例,输入的是一帧图像数据。经过推理模块的处理后,我们将得到的是图像图像和推理结果,包括检测框的位置,id,置信度等等。这些信息都将被保存在cn info结构体中。
2)Pipeline
pipeline的主要功能有搭建pipeline,调度执行模块和传递数据。
① 搭建
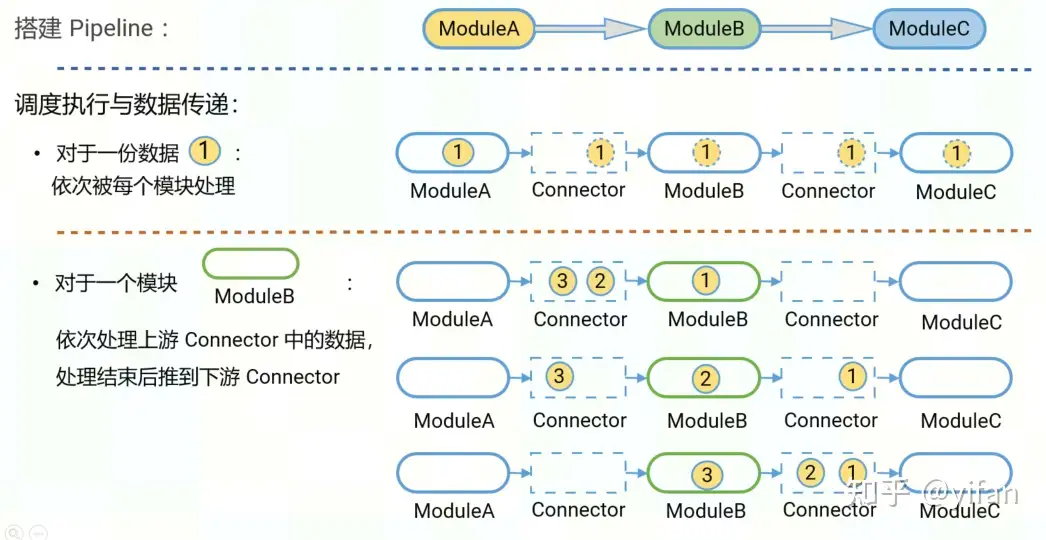
以图为例,我们搭建一条简单的pipeline,模块a,b,c依次连接。对于一份数据来说,数据将依次被每个模块处理。对于一个模块来说,模块将依次处理上有connector中的数据,处理结束后将数据推到下游connector
注意,pipeline最大支持64个模块。
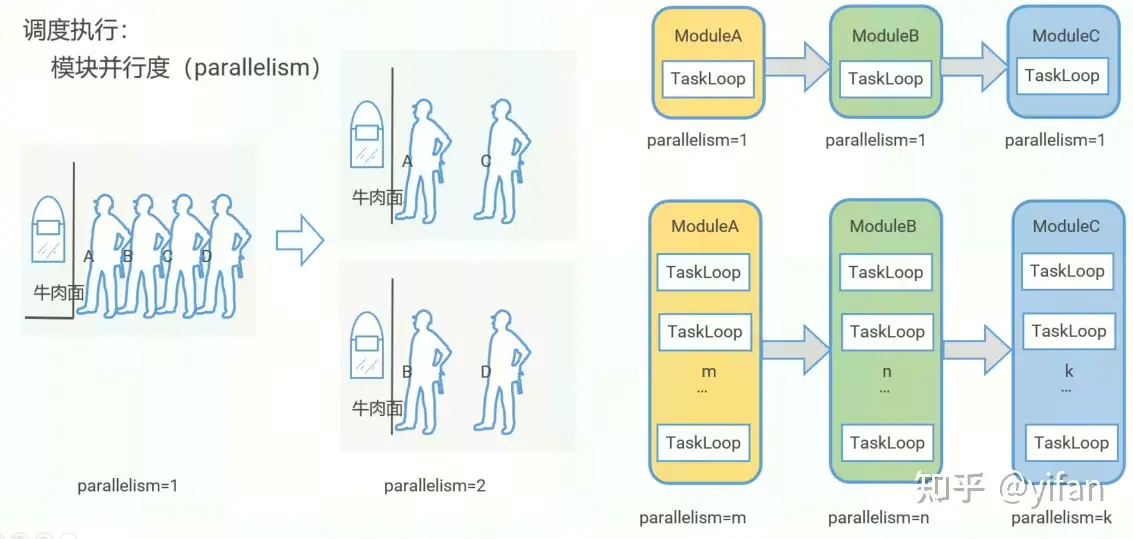
② 调度执行
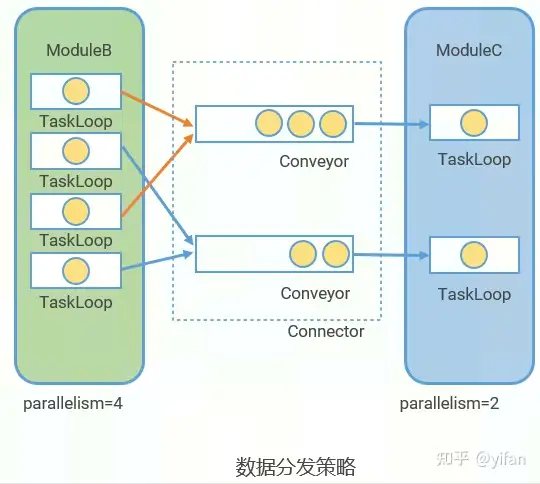
模块并行度 parallelism。以下图的小例子说明,左边只开启一个窗口,有很多人在排队。这时候如果我多开设一个窗口,那么排队的人数就会减半,大大提高了效率。所以简单的来说我们可以通过给每个模块设置并行度,启动多个TaskLoop,并行的执行任务,来提高效率。
3)Connector
各个模块之间的连接器,是传输数据的载体
Connector由Conveyor组成,Conveyor的个数等于下游模块的并行度
分配策略:conveyor_idx = stream_idx % parallelism
Conveyor 的个数等于下游模块的并行度,数据的分发策略是stream_idx % parallelism。可以理解为一个线程安全的 queue。通过设置 queue深度,可平衡 Pipeline中各模块间的数据流量。
上游插件处理速度快,queue会被推满,上游插件数据将被阻塞
下游插件处理速度快,queue会被弹空,下游插件将获得不到数据
4)CN Info
模块间传递的数据是cn info的智能指针。主要需要关注的一个字段collection,支持保存用户自定义的任意数据类型。CNStream针对智能视频分析场景专⻔定义了CNData 用于保存视频帧数据,和CNInfer 用于保存神经网络推理结果。
struct CN Info {
…
std::string stream_id;
int64_t timestamp;
Collection collection;
…};int value = 1;info.collection.Add("my_tag", value);int result = info.collection.Get<int>("my_tag");5)EventBus
模块与pipeline通信的总线EventBus,用户层不感知。
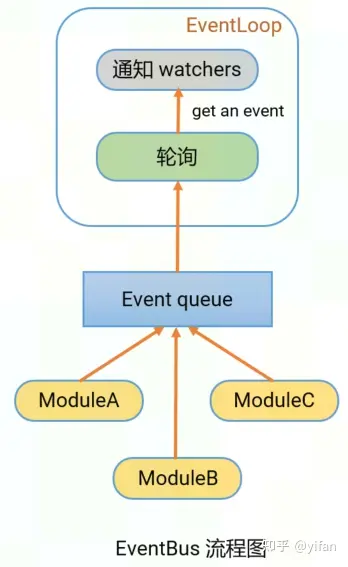
在pipeline启动时,会起一个线程EventLoop,轮询queue中的event。当有模块向queue中推event时,EventLoop会获取到event,并通知watchers。
6)StreamMsgObserver
StreamMsgObserver实现了pipeline与app的通信。
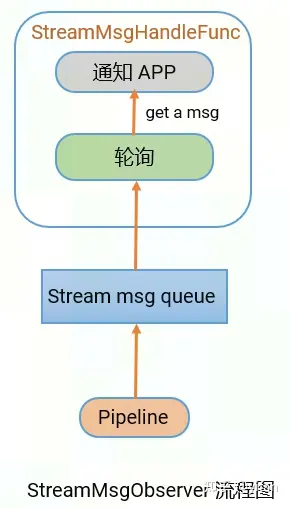
在pipeline启动时,会起一个线程StreamMsgHandleFunc,轮询queue中的message。pipeline将msg推到stream msg queue中,StreamMsgHandleFunc拿到message后,通知app。应用层需要定义类继承自 StreamMsgObserver,并重载 Update 接口,用于接收和处理 pipeline 发送给应用的信息,包括 error,eos 等。
7)IModuleObserver
IModuleObserver实现了module与app的通信。
class MyObserver : public IModuleObserver {
public:
void Notify(cnstream::CN InfoPtr data) override {
// process data ... }};Module module_a("module_a");MyObserver my_observer;module_a.SetObserver(&my_observer);首先需要定义一个 Observer,继承自 IModuleObserver,并 override 基类的 notify 函数,实现拿到数据之后的处理逻辑。然后,通过 module 的 SetObserver 接口设置 observer。
每帧数据被模块处理完后,pipeline调用模块的NotifyObserver接口,
传递cn info的智能指针给observer。
主要的使用场景是当应用层需要获取 CN InfoPtr 时,例如在推理模块后获取推理结果。
针对常规的视频结构化领域, CNStream提供了以下核心功能模块:
数据源模块 DataSource
推理模块 Inferencer
追踪模块 Tracker
叠加推理结果模块 Osd(On-Screen Display)
编码模块 VEncode
Kafka模块 Kafka
DataSource为起始模块,VEncode和kafka模块则为sink模块一般为pipeline的最后一个模块。
DataSource模块是起始模块,是数据的输入
内置decoder,支持硬解码(硬解码不占用推理性能)
解码格式: JPEG, H.264, H.265
支持获取多种形式的资源,本地文件,网络流,内存数据裸流等
支持对解码后的数据进行缩放
支持添加多路数据流到一个DataSource中
支持动态添加和移除数据流
每一路数据流需要由用户指定唯一标识stream_id (string)
模块内部会为每路数据流启动一个线程
DataSource模块没有输入队列;不由Pipeline调度执行;由模块本身负责向下游模块传递数据
1)添加输入流的方式:
创建 SourceHandler:不同形式的资源需要创建不同的 handler
调用 DataSource::AddSource接口:传入创建好的 handler
2)移除输入流的方式:
调用 DataSource::RemoveSource接口传入 handler 或 stream_id
支持快速移除,不再处理 Pipeline 中未处理完的帧
调用 DataSource::RemoveSources接口移除所有流
Pipeline pipeline("my_pipeline");// build pipeline with DataSource which name is source ...std::string source_name = "source"; cnstream::DataSource* source =
dynamic_cast<cnstream::DataSource*>(pipeline.GetModule(source_name));std::string stream_id = "stream_0";cnstream::FileSourceParam param;param.filename = "your_video_path";param. rate = 25;// resize after decoding (optional)cnstream::Resolution out_resolution;out_resolution.width = 1920;out_resolution.height = 1080;param.out_res = out_resolution;source->AddSource(cnstream::CreateSource(source, stream_id, param));// force remove sourcebool force = true;source->RemoveSource(stream_id, force);上面为添加及移除一路本地文件的流程代码。实例化一个pipeline,build pipeline,然后获取DataSource模块指针。定义一个FileSourceParam,然后通过该param设置文件url, rate输入帧率,out_resolution输出分辨率等。然后通过CreateSource接口,创建SourceHandler。并调用AddSource传入handler。完成添加。也可以调用RemoveSource接口移除。force=true代表快速移除。
当设置out_resolution参数时,解码后的图片将被缩放至该分辨率。同时,将使用内存池的方式去保存缩放后的图片数据。如未设置out_resolution参数,则在DataSource中为每一帧数据申请一份内存,并在pipeline处理完毕后释放。
3)DataSource典型配置参数
我们可以通过json文件配置source参数。
{
"source" : {
"class_name" : "cnstream::DataSource",
"custom_params" : {
"bufpool_size" : 16,
"interval" : 1,
"device_id" : 0
}
}}DataSource 的自定义参数有:bufpool_size,存放解码后的数据的内存池大小。注意仅当创建 handler时,设置 out_res 参数后生效。若未设置 out_res 则不使用内存池。
interval,例如我们设置3,则每3帧数据,只处理其中一帧。
device_id,设备号。
1) Inferencer 介绍
推理模块基于EasyDK的推理服务实现推理功能,主要包括三个部分,前处理,推理和后处理。支持常见检测网络,分类网络等神经网络推理,支持二级网络推理。另外,可自定义前处理和后处理,使用反射机制,通过json配置类名便可以使用自定义的前后处理。二级网络推理时,还支持自定义过滤条件,比如只对一级检测出的车目标进行二级推理,同样使用反射机制。
高效
并行执行前处理,推理和后处理
使用离线模型进行推理
支持batch推理
灵活
可自定义前处理和后处理
二级网络推理支持自定义过滤条件,比如只对车进行推理
2) Inferencer 配置
{
"detector" : {
"class_name" : "cnstream::Inferencer",
"parallelism" : 1,
"max_input_queue_size" : 20,
"custom_params" : {
"model_path" : "../../../data/models/yolov3_v0.10.1_4b_rgb_uint8.magicmind",
"preproc" : "name=PreprocYolov3;use_cpu=false",
"postproc" : "name=PostprocYolov3;threshold=0.5",
"batch_timeout" : 200,
"engine_num" : 4,
"model_input_pixel_format" : "RGB24",
"device_id" : 0
}
}}推理的一些自定义参数,比如离线模型路径,前处理和后处理的类名字符串,batch_timeout,推理引擎,模型输入颜色空间以及设备号。batch_timeout,拼batch时最大等待时间,也就是说,当超过batch_timeout时间还没有拼满,则不再等待,直接进行推理。当这个数值设置的过大时,可能会造成延时的增加,设置的过小时,可能会拼不满batch导致硬件资源浪费。数值的设置一般来说和batch_size,解码和推理的速度有关。
追踪模块一般连接在刚讲的推理模块之后,对检测到的目标进行追踪。
具体而言:追踪一般分两步,特征提取+特征匹配。特征提取是离线网络完成的,特征匹配的实现有两种算法,cnstream支持Feature Match 和 IOU Match 。默认使用 FeatureMatch算法
{
"tracker" : {
"class_name" : "cnstream::Tracker",
"parallelism" : 1,
"max_input_queue_size" : 20,
"custom_params" : {
"model_path" : "../../../data/models/feature_extract_v0.10.1_4b_rgb_uint8.magicmind",
"track_name": "FeatureMatch",
"max_cosine_distance": "0.06",
"engine_num" : 2,
"device_id" : 0
}
}}上面是一个tracker的json配置,使用过程中,我们使用 feature_extract_v0.10.1_4b_rgb_uint8.magicmind 该离线模型进行特征提取,FeatureMatch 进行特征匹配。 当然也可以根据自己实际场景进行替换。
将推理结果叠加在原图上显示。支持如下:
分类网络:类别,置信度
检测网络:检测框,类别,置信度
追踪 :追踪id
支持叠加次级网络结果
支持自定义OsdHandler
(可选) 可配置label大小
(可选) 可配置字体
{
"osd" : {
"class_name" : "cnstream::Osd",
"parallelism" : 1,
"max_input_queue_size" : 20,
"custom_params" : {
"label_path" : "../../../../data/models/label_map_coco.txt"
}
}}VEncode模块支持软编码和硬编码。支持的编码格式有jpeg,h264和h265。支持对输入进行缩放后编码,通过自定义参数dst_width和dst_height设置dst分辨率,默认使用原始分辨率。
对于编码后的数据,支持保存到本地文件,支持封装mp4。需要用户通过自定义参数file_name设定要保存的文件的名字,同时模块将根据文件名来区分编码格式和是否需要封装为mp4。如右侧两个json配置,一个将编码mp4视频,另一个则编码jpeg图片。
除此之外,VEncode还支持RTSP推流。需要用户设置自定义参数rtsp_port。推流url默认为rtsp://本机ip:端口号/live。
支持单图模式和拼图模式。默认单图模式。
{
"venc" : {
"class_name" : "cnstream::VEncode",
"parallelism" : 1,
"max_input_queue_size" : 10,
"custom_params" : {
"file_name" : "output/output.mp4",
"view_cols" : 3,
"view_rows" : 3,
"device_id": 0
}
}}上述第7行换成以下形式,可以使用 jpeg或推流形式。
"file_name" : "output/output.jpg", "rtsp_port" : 9554,
当我们希望使用拼图模式时,设置自定义参数view_cols和view_rows,他们代表格子的行列个数。注意格子数目一定要大于输入路数。
Kafka模块支持发送kafka消息数据到集群中供消费者消费。支持自定义 KafkaHandler ,根据业务需求将需要的数据转换为 Kafka 消息数据。例如结构化信息等。
{
"kafka_producer" : {
"class_name" : "cnstream::Kafka",
"parallelism" : 1,
"max_input_queue_size" : 20,
"custom_params" : {
"handler" : “DefaultKafkaHandler",
"topic" : "CnstreamData",
"brokers" : "localhost:9092"
}
}}
{
"StreamName": "stream_0",
" Count": 119,
" s": [
{
"Label": "2",
"Score": 0.94384765625,
"BBox": [
0.8779296875,
0.4668387770652771,
0.12060546875,
0.5147867798805237
]
},
{
"Label": "2",
"Score": 0.62890625,
"BBox": [
0.1103515625,
0.8813707232475281,
0.284423828125,
0.11862927675247193
]
}
]}inspect tool可以用来获得CNStream的版本信息,查看支持的内置模块以及查询每个模块支持的自定义参数。
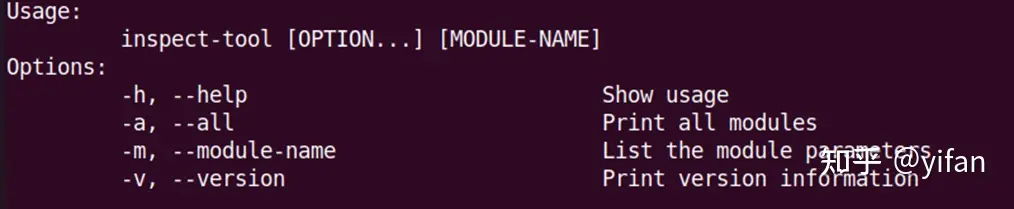
提供 Pipeline各部分的 时延和吞吐 信息
性能统计通过在 Pipeline中各个处理过程的开始和结束点上打桩,记录打桩时间点,并基于打桩时间点来计算时延、吞吐等信息。
性能统计机制以某个处理过程为对象进行性能统计。一个处理过程可以是一个函数调用、一段代码,或是 Pipeline中两个处理节点之间的过程。在 CNStream的性能统计机制中,每个处理过程通过字符串进行映射。
对于每个 Pipeline实例,通过创建一个 PipelineProfiler实例来管理该 Pipeline 中性能统计的运作。通过 PipelineProfiler实例为 Pipeline中的每个模块创建一个 ModuleProfiler实例来管理模块中性能统计。并通过 ModuleProfiler的 RegisterProcessName接口注册需要进行性能统计的处理过程,使用 ModuleProfiler::RecordProcessStart和 ModuleProfiler::RecordProcessEnd在各处理过程的开始和结束时间点打桩,供 CNStream进行性能统计。
| 字段名称 | 描述 |
| completed | 表示已经处理完毕的数据总量,不包括丢弃的数据帧。 |
| dropped | 表示被丢弃的数据总量。当某一个数据被记录开始后,较之更晚记录开始的16个数据已记录到结束,则视为该数据帧已经丢弃。 |
| counter | 表示统计到的对应处理过程已经处理完毕的数据的总量。被丢弃的数据也视为处理完毕的数据,会被累加在到counter上。 counter = completed + dropped |
| ongoing | 表示正在处理,但是未被处理完毕的数据总量。即已经记录到开始时间 但是未记录到结束时间的数据总量。 |
| latency | 平均时延,单位为毫秒。 |
| maximum_latency | 最大处理时延,单位为毫秒。 |
| minimum_latency | 最小处理时延,单位为毫秒。 |
| fps | 平均吞吐速度,单位为帧/秒。 |
CNStream 提供的示例中,可通过设置 perf_level 参数,控制性能打印的详细程度。0到3,打印的数据越来越详细,默认值为0:
当 perf_level为0时,只打印各处理过程的 counter统计值与 fps(吞吐)统计值。
当 perf_level为1时,在0的基础上加上 latency、maximum_latency、 minimum_latency三个统计值的打印。
当 perf_level为2时,打印 ProcessProfile结构中的所有性能统计值。
当 perf_level为3时,在2的基础上打印每路数据流的性能统计数据。
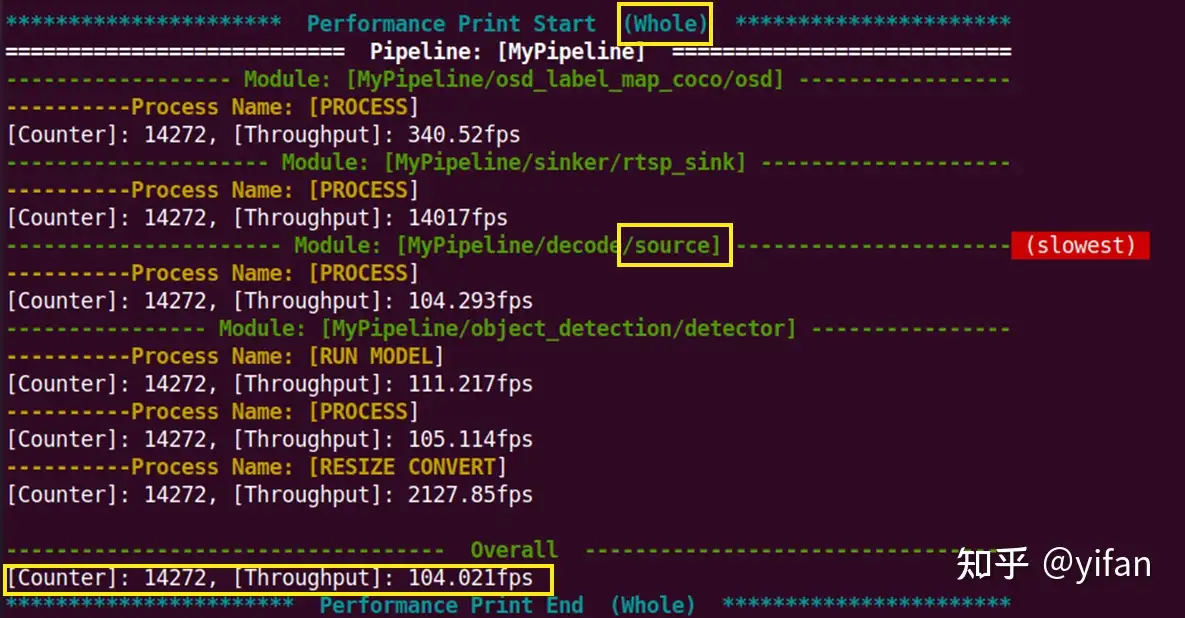
平均性能
当我们执行示例时,将在终端上打印性能数据,如图。Whole代表从程序启动以来的平均性能。提供各模块的性能和pipeline的整体性能。
SyntaxHighlighter.all();
热门帖子
精华帖子





 Ashelly
13 回复
Ashelly
13 回复
 fengyunkai
1 回复
fengyunkai
1 回复
 三叶虫
3 回复
三叶虫
3 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读