打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
2019年即将过去一半,剑桥大学的两位研究人员近日推出了本年度的State AI 2019全景报告。
本报告基本沿袭去年的大体框架,从产业、人才、政策、预测等方面对过去一年来AI领域的技术的新进步、产业格局的新变化、政府政策的新特点等方面进行了总结,并作出关于未来的预测。

报告地址:
https://www.slideshare.net/StateofAIReport/state-of-ai-report-2019-151804430
值得一提的是,与去年不同的是,2019年的报告为中国单列一章,介绍中国AI技术在日常消费、机器人、半导体等领域的进步。

本文重点对报告中的AI研究、AI人才以及中国三部分内容作出介绍。
AI研究与技术突破:游戏、NLP、医疗全面开花
强化学习开疆扩土:在多项竞技性游戏中击败人类
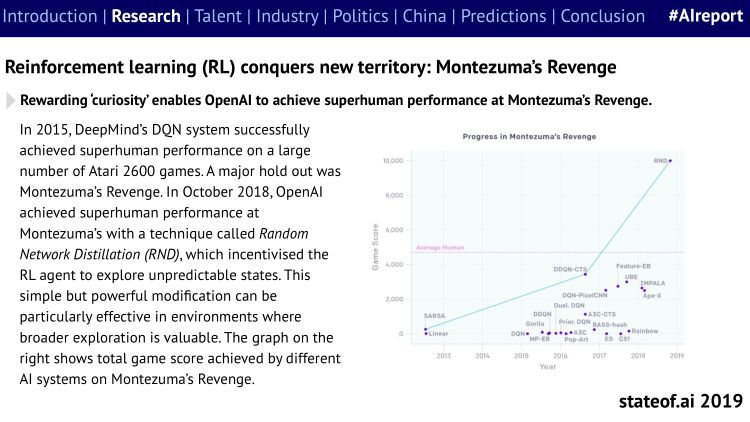
目前已经被AI统治的游戏包括《蒙特祖玛的复仇》、《星际争霸2》、《雷神之锤3》,在DOTA2上游戏水平实现大幅进步。未来的游戏AI可能让人类更加遥不可及了。

未来,研究人员有望利用强化学习训练单个机器人来完成多个复杂任务,无需针对每个任务进行专门的再学习。

基于好奇心机制的探索:在奖励稀疏或无奖励机制的条件下,智能体可以依赖“好奇心”解决问题。

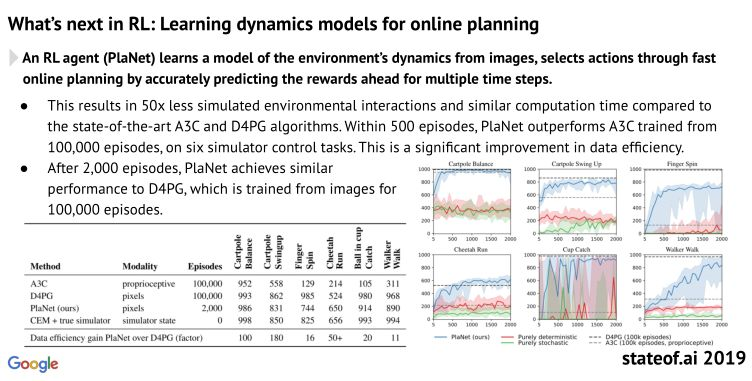
面向在线计划学习动态模型:模型可从图像中快速学习环境动态信息,准确预测数个时间段后的奖励。
研究成果逐步进入实际生产环境:在众多机器学习框架和工具的支持下,Facebook发布的开源端对端平台Horizon,推进大规模生产环境下的系统优化,如信息联想、视频流质量、通知服务优化等。

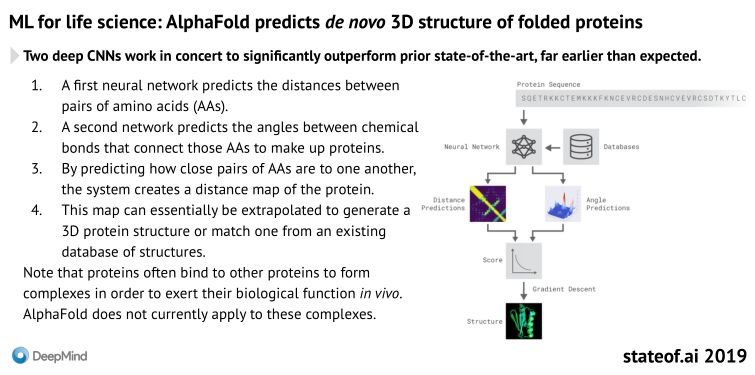
生命科学中的新突破:AlphaFold精准预测蛋白质的折叠结构
NLP大丰收:预训练语言模型大展身手
新的预训练模型不断涌现,各大数据集新纪录常看常新。Google AI的BERT, 、Transformer,艾伦研究所的ELMo、OpenAI的Transformer、 Ruder和Howard的 ULMFiT、微软的MT-DNN等争奇斗艳。

神经机器翻译:无需双向文本

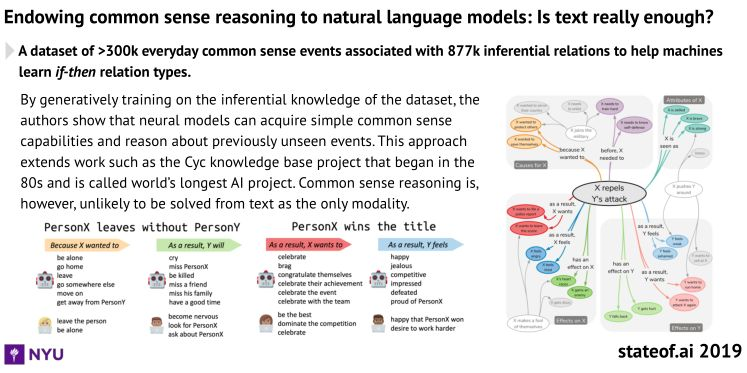
自然语言模型学会常识推理
对机器学习领域的数据隐私和保护越来越重视

医学领域大展身手,诊断堪比人类专家
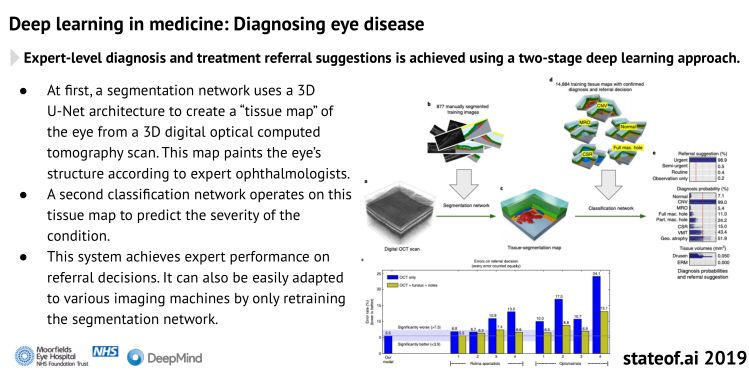
诊断眼疾
使用两个阶段机器学习方法,AI模型给出了专家级的眼疾诊断和治疗参考建议
利用心电图检测心律不齐,达到人类医生水平
超过60万的X光片数据集已经被分享出来,但远远不够
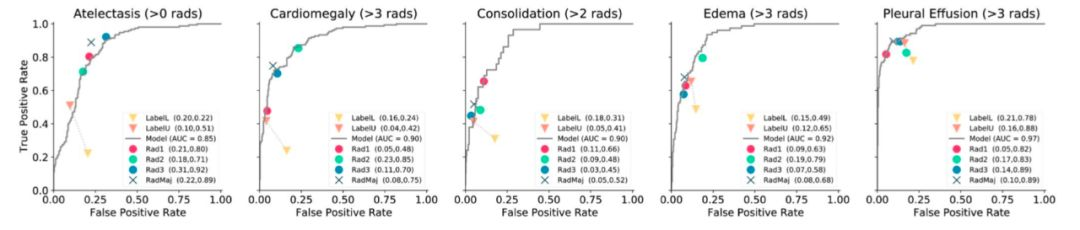
用于成像诊断的深度学习模型可以很好地拟合数据集,但是它们难以推广到新的数据分布。尽管改进了这个新数据集的文档,但标签定义很浅
使用医生笔记中的NLP提取标签存在挑战:容易出错且容易受到影响。放射学报告中包含的信息不足,大多数标签类别的错误率为5-15%
大量重复扫描,其中70%的扫描来自30%的患者。这减少了数据集的有效大小及其多样性,影响训练模型的普适性
研究人员从听觉皮层的神经活动中重建语音
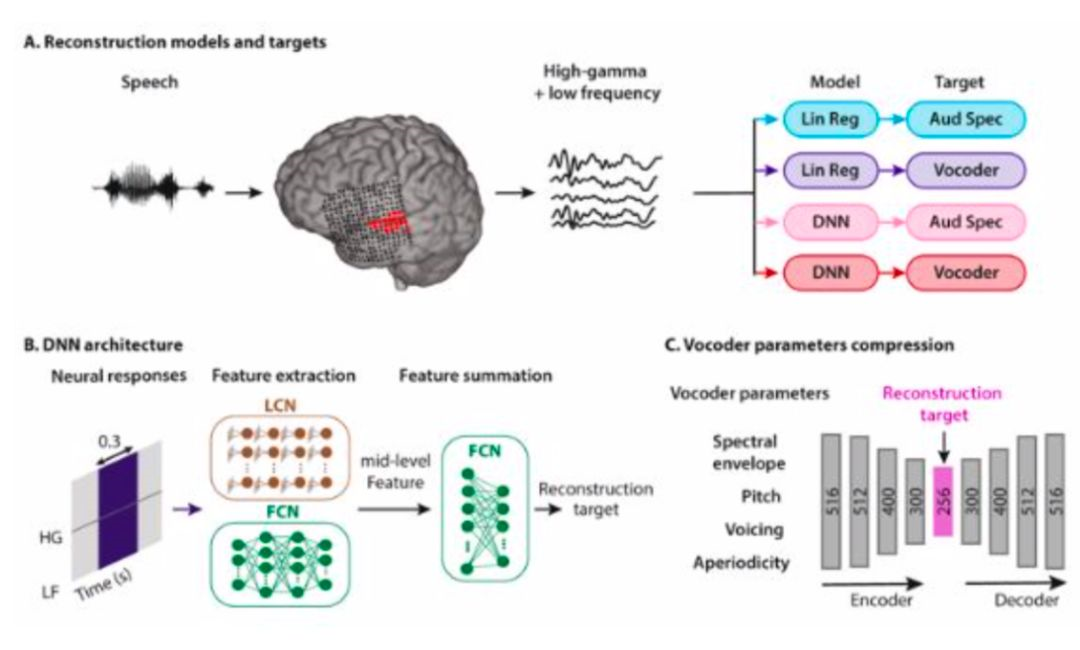
哥伦比亚大学的研究人员使用侵入性脑电图来测量5名接受癫痫治疗的患者在连续收听语音时的神经活动
反过来使研究人员能够通过大脑活动的声码器合成语音。通过声码器测试单个数字“口语”时,系统的准确度达到75%。与基线线性回归方法相比,深度方法将语音的可懂度提高了65%
该研究表明,大脑计算机界面有可能恢复瘫痪患者的沟通
使用蒙特卡罗树搜索神经网络通过训练1240万个反应来解决逆向合成
一个由三个NN(3N-MCTS)构建的系统:
通过提出有限数量的自动提取转换来指导向有希望的方向搜索
预测拟议的反应是否实际可行
估计位置值并迭代
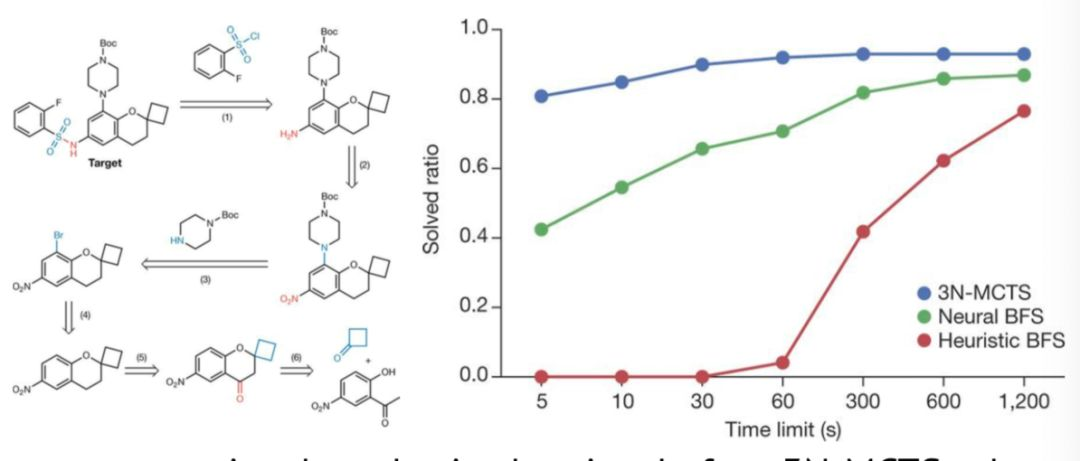
这种方法比最先进的计算机辅助综合计划快得多。实际上,3N-MCTS解决了超过80%的分子测试集,每个目标分子的时间限制为5秒。
相比之下,一种称为最佳第一搜索的方法,其中通过神经网络学习函数可以解决40%的测试集。使用手动编码启发式功能设计的最佳首次搜索执行最差:它在5秒内解决了0%。
AutoML:神经网络架构和超参数的进化算法
共同优化超参数,最大化网络性能,同时最小化复杂性和大小
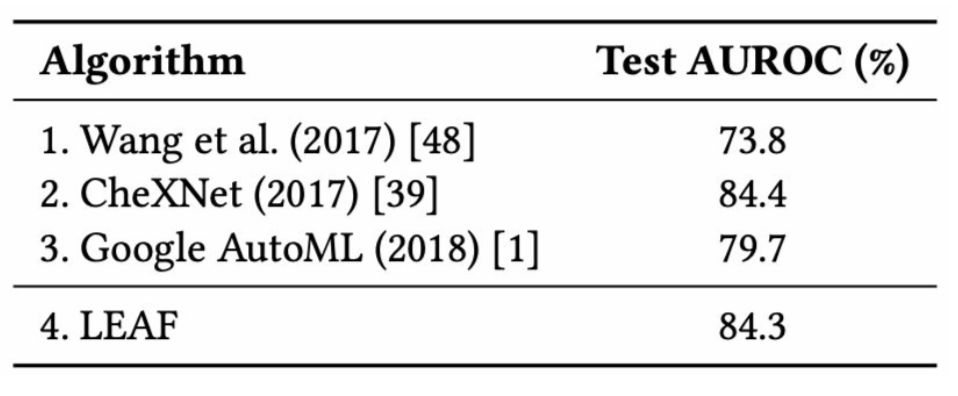
之前的AutoML工作使用RL单独优化超参数或网络架构。遗憾的是,RL系统要求用户事先为算法定义适当的搜索空间以用作起点,可以针对每个层优化的超参数的数量也是有限的
此外,计算非常繁重。为了生成最终的最佳网络,必须对数千个候选架构进行评估和训练,这需要大约100k GPU小时
另一种选择(Learning Evolutionary AI work:LEAF)是使用进化算法进行超参数和网络架构优化,最终产生更小,更有效的网络
例如,LEAF与手工制作的数据集特定网络(CheXNet)的性能相匹配,用于胸部X射线诊断分类,并且优于Google的AutoML
AutoML:使用真实的设备性能反馈设计资源受限的网络
基于CNN的自动化架构搜索的步伐正在加快:Facebook与谷歌的竞争加剧
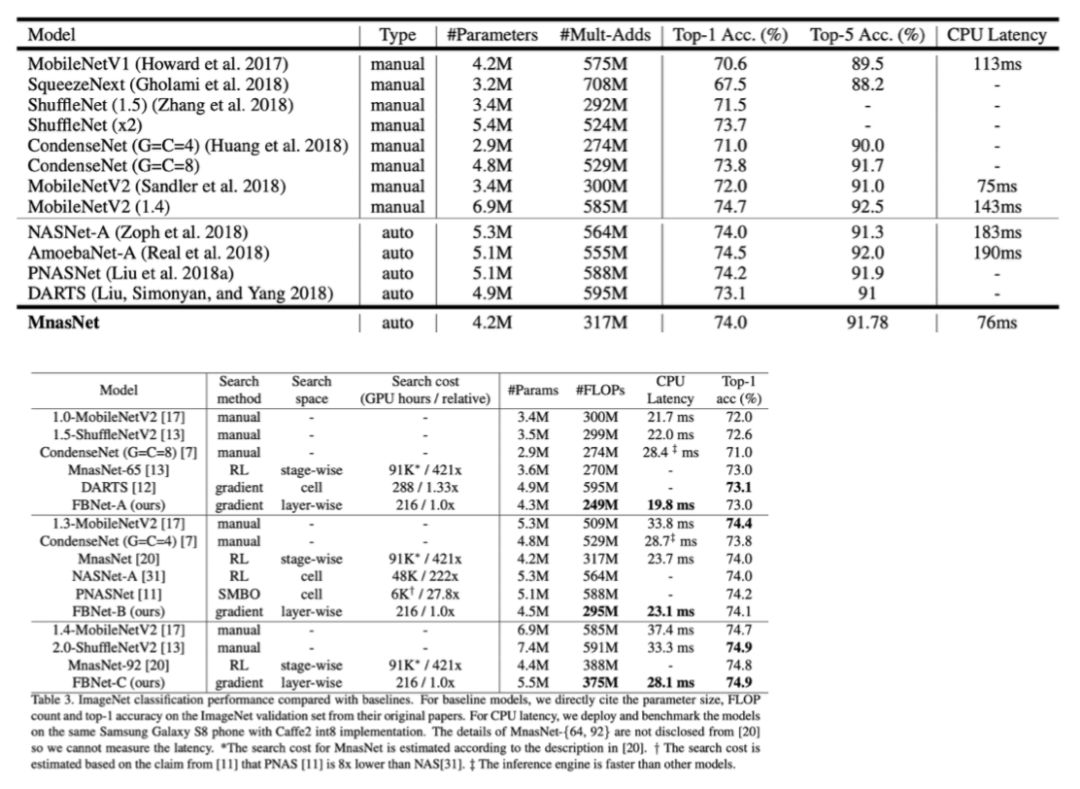
谷歌展示了一种基于RL的多目标方法(MnasNet),可以在Google Pixel平台上测量具有低实际推理延迟的高精度CNN模型。该系统在Pixel手机上达到74.0%的Top-1精度,延迟为76ms,比MobileNetV2快1.5倍
Facebook提出了一种可区分的神经架构搜索(DNAS)框架,该框架使用基于梯度的方法在分层搜索空间上优化CNN架构。FBNet-B实现了与MnasNet相同的Top-1精度,但延迟仅为23.1ms,搜索成本降低了420倍
GAN的最新技术水平在不断发展:从颗粒到GANgsta
较大的模型和大批量训练进一步提高了使用GAN生成的图像的质量
GAN中的最新技术水平在不断发展:从面部到全身
通过将面部与口语相匹配(左),电影只需设置一次,即可以不同语言生成相同的视频。下一步是从头到脚生成整个身体,目前用于零售目的(右)
在图像和视频操作之后出现逼真的语音合成
从单个图像中学习对象的3D形状
模型输出10个不同类别(如汽车、摩托车、行人、交通锥等)的3D边界框,类特定属性(如汽车是否正在行驶或停车)并提供当前速度矢量。
人才方面,以研究论文的产出衡量,谷歌是最具生产力的一个组织。上图为在人工智能顶会NeurIPS 2018上,谷歌发表的论文最多,其次是MIT、斯坦福、CMU和加州大学伯克利分校。
在NeurIPS、ICML或ICLR上发表论文的4000名研究人员中,88%是男性。
大型科技公司高级工程师的年薪接近100万美元。
另一方面,数据标签工作也有了巨大的增长,尤其是在中国。这类工作的最低工资可低至每小时10元人民币。
神经网络的先驱、Yann LeCun、Geoffrey Hinton和Yoshua Bengio获得了图灵奖,这是计算机科学的最高奖项。
欧洲发表的AI论文最多,但在平均引文率这个指标上,只有中国是增长的。
该领域论文的数量整体是增长的,不同地区论文的平均被引量表明,只有来自中国的论文变得更有影响力了。美国作者发表的论文被引用的次数比全球平均水平高出83%。
MIT在计算与人工智能领域新增10亿美元投资。在3.5亿美元捐赠的支持下,MIT新的计算学院将把MIT重新定位为向所有研究领域注入AI教育,提供了50个新的教职,使MIT在该领域的学术能力翻了一番。
大学里人工智能相关课程的注册人数也在增长,中国的增长尤其快。
热门帖子
精华帖子




 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读