打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
本文是作者在调试caffe模型精度中总结的一些方法,供大家参考。
拿到一个模型,先看一下int16的精度有没有问题。
如果int16精度异常了,那先查查原因吧~
首先逐层比对,那么如何逐层比对呢?
我们的caffe中增加了一个参数“debug_info”,如果在prototxt文件中设置为“true”,mlu/cpu推理运行时将会把每层输出数据自动保存到文件。
编译caffe后,我们可以使用caffe/tools下的test_forward_online工具来推理并dump出每层数据,输入是随机的。
>>> 使用方式:
./caffe/tools/test_forward_online proto_file model_file mlu_option mcore output_file
其中:
- proto_file为模型结构.prototxt所在路径;
- model_file为模型权值.caffemodel所在路径;
- mlu_option选择推理运行模式,0为cpu运行模式,1为mlu逐层运行模式,2为mlu融合运行模式;
- mcore为调试板卡型号,一般为MLU270;
- output_file为输出数据保存文件路径。
使用:
① 可以先运行cpu模式,dump cpu逐层数据:
./caffe/tools/test_forward_online ./model.prototxt ./weights.caffemodel 0 MLU270 outcpu
运行后,在当前路径下会得到多个 "tmp_layer_000" 开头的cpu逐层数据,为了方便对比,我们可以将这些数据批量 mv 到同一个目录下:
mkdir cpu_layers mv tmp_layer_000* ./cpu_layers
② 再dump mlu逐层数据:
./caffe/tools/test_forward_online ./model.prototxt ./weights.caffemodel 1 MLU270 outmlu
运行后,在当前路径下会得到多个 "tmp_layer_000" 开头的mlu逐层数据,为了方便对比,我们可以将这些数据批量 mv 到同一个目录下:
mkdir mlu_layers mv tmp_layer_000* ./mlu_layers
除了test_forward_online工具,我们也可以使用caffe/tools下的caffe test来推理运行,该方式输入是真实数据
>>> 使用方式:
首先,量化时将配置文件中的use_firstconv设置为1,量化后prototxt中首层conv层会增加“mean_value”和“std”信息;
其次,将首层data层按如下方式修改:
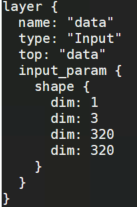
改成:
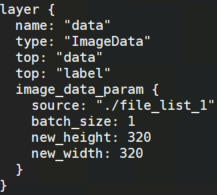
其中,source为真实数据所在路径list。
使用:
① 先运行cpu模式,dump cpu逐层数据:
./caffe/tools/caffe test --model ./model.prototxt --weights ./weights.caffemodel --iterations 1
运行后,在当前路径下会得到多个 "tmp_layer_000" 开头的cpu逐层数据,为了方便对比,我们可以将这些数据批量 mv 到同一个目录下:
mkdir cpu_layers mv tmp_layer_000* ./cpu_layers
② 再dump mlu逐层数据:
./caffe/tools/caffe test --model ./model.prototxt --weights ./weights.caffemodel --iterations 1 --mmode MLU --mcore MLU270
运行后,在当前路径下会得到多个 "tmp_layer_000" 开头的mlu逐层数据,为了方便对比,我们可以将这些数据批量 mv 到同一个目录下:
mkdir mlu_layers mv tmp_layer_000* ./mlu_layers
分别获得cpu和mlu的逐层数据信息后,可通过提供的mse算法来逐层比对,如下所示:

>>> 使用方式:
python ./caffe/src/caffe/test/cmpDirData.py ./cpu_layers ./mlu_layers
也可以根据实际需求增加比对算法,如下所示是通过余弦相似度算法比对的信息:

上图所示精度正常,如果遇到某层精度明显下降,可以看看是量化还是算子问题导致。
那么如何判断是量化还是算子问题?我们有cpu模拟量化工具去判定,当然我们也可以通过将量化算子放到cpu上运行,来判定是否是量化问题导致的精度异常。
如何将量化算子放到cpu上运行?有两种方式:
- 第一种方式,在prototxt指定层中增加“engine:CAFFE”,表示该层在cpu运行,这个方式适合算子比较少的情况,如果算子多了,一层一层地去添加太麻烦了;
- 第二种方式,修改 _factory.cpp,让mlu运行的算子实际走的是cpu的实现,这种方式可以把某类算子都先用cpu算子实现,快速定位是哪一类算子的问题,如下所示(注意:修改 _factory.cpp后需重新编译caffe):
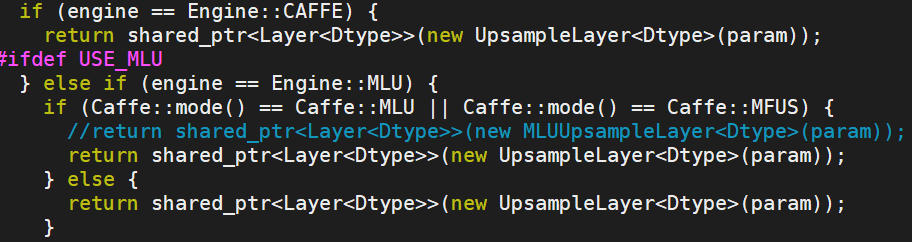
比如,通过第二种方式,将量化层放到cpu上运行,精度正常了,可以考虑是由于量化方式导致的精度异常,通过使用我们提供的其他量化方式重新量化并推理,看精度是否达标。如果是非量化层放到cpu上运行,精度正常了,可以考虑是算子的问题,可及时与我们联系沟通解决。
大家可以根据实际需求去选择方式。
通过以上的方式可以定位到int16量化精度异常问题的原因了。
如果int16精度正常,而int8精度异常呢?其实int8精度问题定位和int16的方式一致。先根据逐层dump数据比对,定位到哪层精度开始下降,再去确定是量化导致还是算子实现问题。
以上就是这次分享的全部内容了,后续如有新方式或改动会及时更新。
热门帖子
精华帖子





 Ashelly
14 回复
Ashelly
14 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读