打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
【寒武纪硬件产品型号】:MLU220
问题描述:
将一个语义分割的模型移植到mlu220上,模型在GPU达到75fps,但在mlu220上却达不到实时,NPU利用率也只有30%,请问可以做些什么改进从而提高速度?
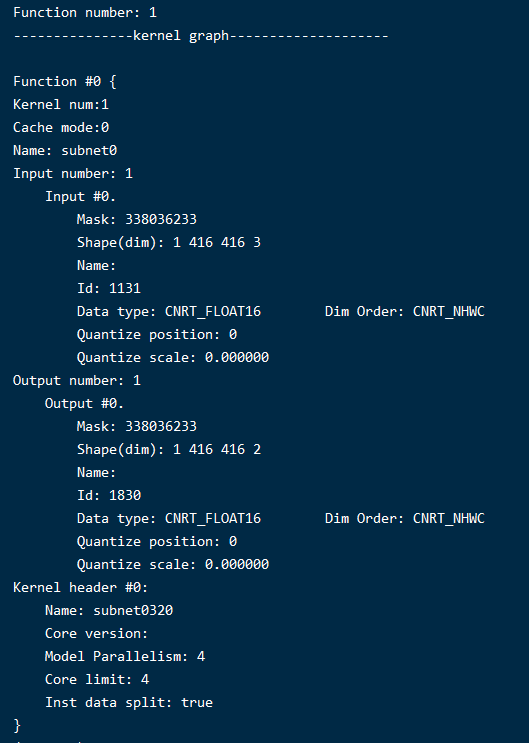
离线模型生成如下:
ct.set_core_number(4)
ct.set_core_version("MLU270")
torch.set_grad_enabled(False)
self.net = Model(num_classes=self.num_classes, backbone=self.backbone, downsample_factor=self.downsample_factor, pretrained=False)
self.net = torch_mlu.core.mlu_quantize.quantize_dynamic_mlu(self.net)
self.net.load_state_dict(torch.load(self.model_path))
self.net = self.net.to(ct.mlu_device())
self.net = self.net.eval()
example = torch.randn(1,3,416,416).float()
trace_input = torch.randn(1,3,416,416, dtype=torch.float)
if self.half_input:
example = example.type(torch.HalfTensor)
trace_input = trace_input.type(torch.HalfTensor)
self.net = torch.jit.trace(self.net, trace_input.to(ct.mlu_device()), check_trace=False)
torch_mlu.core.mlu_model.save_as_cambricon('deeplabv3_mbnetv2_270_int8_f16_offline_bs1')
for i in range(10):
self.net(example.to(ct.mlu_device()))
torch_mlu.core.mlu_model.save_as_cambricon('')
热门帖子
精华帖子





 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读