打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
在做综合实验文本识别 OCR-EAST时,在重新编译时遇到一些问题,来分享一波!
问题一:
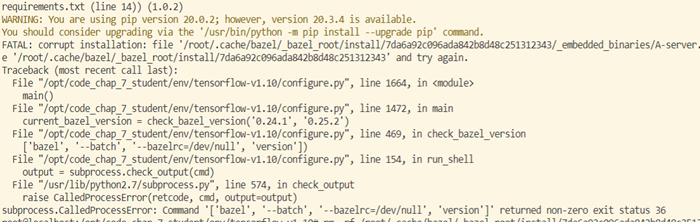
提示关于bazel的错误:
解决方案:可根据终端输出信息提示找到install文件夹下的文件存在问题,根据括号内的操作提示删除,执行命令:
rm -rf /root/.cache/bazel/_bazel_root/install/7da6a92c096ada842b8d48c251312343
问题二:

关于keras的错误问题
解决方案:添加依赖keras
pip install keras_applications==1.0.4 --no-deps
pip install keras_preprocessing==1.0.2 --no-deps
pip install h5py==2.8.0
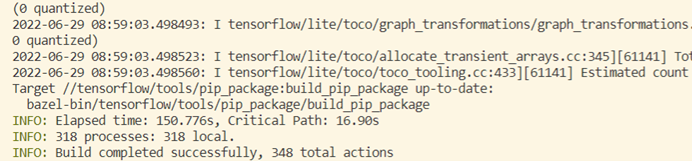
问题三:Executing genrule //tensorflow:tf_python_api_gen_v1 failed,
解决方案:尝试过网上的解答,似乎并没有解决问题,后在终端找到出现错误的文件libcnplugin.so,对其重新编译,替换原文件,执行脚本后成功!
将tensorflow重新编译成功大概需要30~40分钟,耐心等待! (笔者花了一下午
(笔者花了一下午 )
)
热门帖子
精华帖子





 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读