打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
前言:这篇论文旨在以极低的计算成本解决性能大幅下降的问题。提出了微分解卷积,将卷积矩阵分解为低秩矩阵,将稀疏连接整合到卷积中。提出了一个新的动态激活函数-- Dynamic Shift Max,通过最大化输入特征图与其循环通道移位之间的多个动态融合来改善非线性。
在这两个新操作的基础上,得到了一个名为 MicroNet 的网络系列,它在低 FLOP 机制中实现了比现有技术显着的性能提升。在 12M FLOPs 的约束下,MicroNet 在 ImageNet 分类上达到了 59.4% 的 top-1 准确率,比 MobileNetV3 高 9.6%。

欢迎关注公众号 CV技术指南 ,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读。
论文出发点
高效 CNN 架构的最新进展成功地将 ImageNet 分类的计算成本从 3.8G FLOPs (ResNet-50) 降低了两个数量级到大约 40M FLOPs(例如 MobileNet、ShuffleNet),性能下降合理。
然而,当进一步降低计算成本时,它们会遭受显着的性能下降。例如,当计算成本分别从 44M 下降到 21M 和 12M MAdds 时,MobileNetV3 的 top-1 准确率从 65.4% 大幅下降到 58.0% 和 49.8%。
这篇论文的目标是将极低 FLOP 机制下的精度从 21M 降到 4M MAdds,这标志着计算成本降低到另一个数量级。
处理极低计算成本(4M-21M FLOPs)的问题非常具有挑战性,考虑到输入数据大小为 224×224x3,在第一层 3 × 3 卷积、输出通道8的操作上就消耗了 2.7M MAdds。 剩余的资源太有限,无法设计有效分类所需的卷积层和 1,000 类分类器。
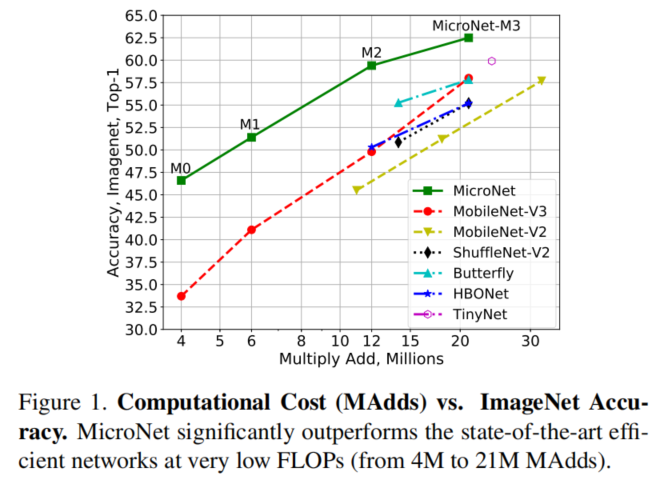
如上图所示,减少现有高效 CNN(例如 MobileNet 和 ShuffleNet)的宽度或深度的常见策略会导致严重的性能下降。
这篇论文专注于新的算子设计,同时将输入分辨率固定为 224×224,预算成本为 4M FLOPs。
创新思路
这篇论文从两个角度处理极低的 FLOPs:节点连接性(node connectivity)和非线性(non-linearity),这与网络宽度和深度有关。
首先,降低节点连接以扩大网络宽度为给定的计算预算提供了一个很好的权衡。其次,依靠改进的层非线性来补偿减少的网络深度,这决定了网络的非线性。这两个因素促使设计更有效的卷积和激活函数。
Methods
Micro-Factorized Convolution
分为两部分:Micro-Factorized Pointwise Convolution和 Micro-Factorized Depthwise Convolution,两者再以不同方式组合。
Micro-Factorized Pointwise Convolution
论文提出了微分解卷积 (MF-Conv) 将逐点卷积分解为两个组卷积层,其中组数 G 适应通道数 C 为:G = sqrt(C/R)。其中 R 是两者之间的通道缩减比。
对于给定的计算成本,该等式在通道数量和节点连接之间实现了良好的折衷。
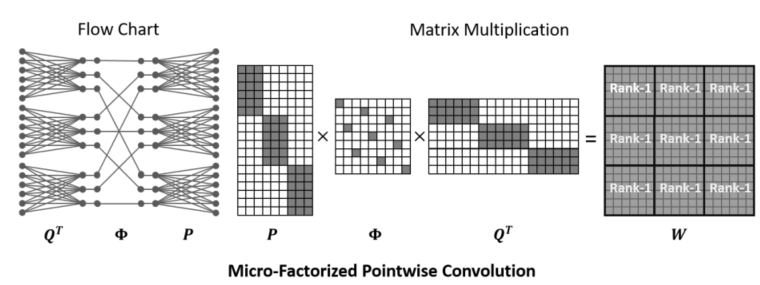
如上图所示,输入通道数C分为G组,G组再通过中间一个 (C/R × C/R )的置换矩阵Φ 降低通道数,这个置换矩阵类似于shufflenet中的打乱通道顺序的操作。
Micro-Factorized Depthwise Convolution
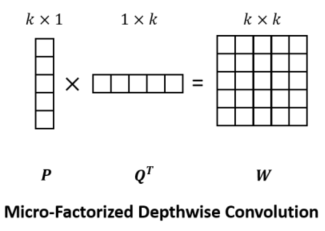
这个部分是引用Inception_v2中的分解卷积,在使用Depthwise的基础上,将KxK卷积核分为Kx1和1xK两部分。
Micro-Factorized pointwise 和 depthwise 卷积可以以两种不同的方式组合:(a) 常规组合,和 (b) lite 组合。
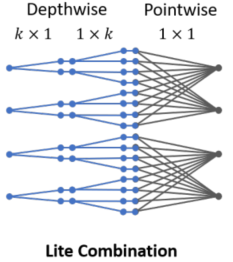
前者只是将两个卷积连接起来。 上图所示的 lite 组合使用微分解深度卷积来扩展通道数量,通过为每个通道应用多个空间滤波器。 然后应用一组自适应卷积来融合和压缩通道数。 与其常规组合方式相比,它通过节省通道融合(pointwise)计算在学习空间过滤器(depthwise)上花费更多资源,经验证明这对于实现较低的网络层更有效。
Dynamic Shift-Max
考虑到Micro-Factorized pointwise 卷积更注重组内的连接,因此提出Dynamic Shift-Max,这是一种新的动态非线性,用于加强由Micro-Factorized创建的组之间的联系。
Dynamic Shift-Max 输出 K 个融合的最大值,每个融合组合多个 (J) 组位移为
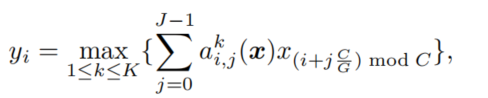
其中J表示组数,i表示通道数,K表示融合后的输出数量。当J=K=2时,可以在准确率和复杂度之间取得较好的折衷。
这个公式用一句话来解释就是,每J个组,对每组的x进行加权求和,共K个融合,然后取K个中的最大值作为第i个通道上的激活函数值。
这样,DY-Shift-Max 实现了两种形式的非线性: (a) 输出 J 组的 K 个融合的最大值,以及 (b) 通过动态参数。
第一个非线性是对 Micro-Factorized pointwise 卷积的补充,它侧重于每个组内的连接,加强组之间的连接。第二个使网络能够根据输入 x 调整这种强化。这两个操作增加了网络的表示能力,补偿了减少层数所带来的损失。
MicroNet
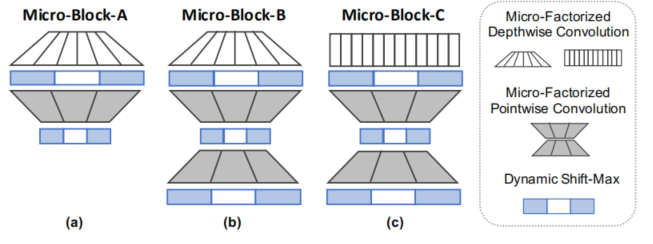
Conclusion
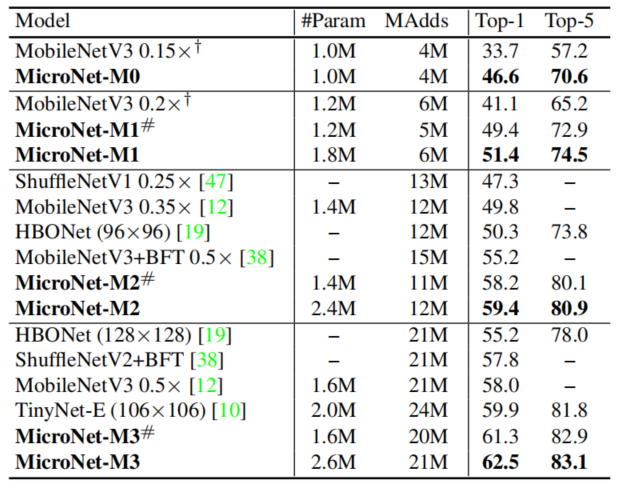
在 12M FLOPs 的约束下,MicroNet 在 ImageNet 分类上达到了 59.4% 的 top-1 准确率,比 MobileNetV3 高 9.6%。
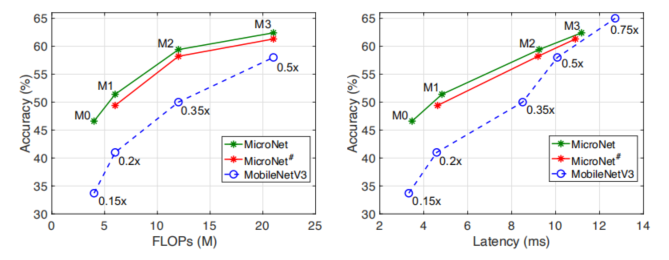
对 ImageNet 分类的评估。左:top-1 准确率与 FLOPs。右图:top-1 准确率与延迟。注意添加了 Mo bileNetV3 ×0.75 以方便比较。MicroNet 优于 MobileNetV3,尤其是在计算成本极低的情况下(当 FLOPs 小于 15M 或延迟小于 9ms 时,top-1 精度提高 5% 以上)。
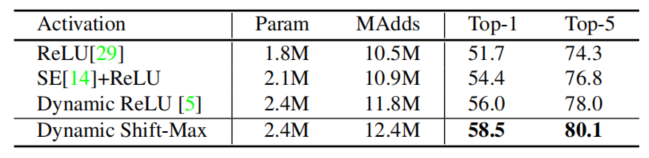
动态 Shift-Max 与 ImageNet 上的其他激活函数的比较。
本文来源于公众号 CV技术指南 的论文分享系列。
热门帖子
精华帖子





 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读