打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
导读
本文章主要介绍如何利用NVIDIA推出的Triton推理引擎与寒武纪推出的面向MLU的推理引擎MagicMind相结合的方式在MLU上实现推理模型服务化的功能。
项目Github地址:https://github.com/xiaoqi25478/triton_python_backend_with_magicmind
项目包含了yolov5 bert和resnet50三个网络的triton+magicmind的部署demo。
基本介绍
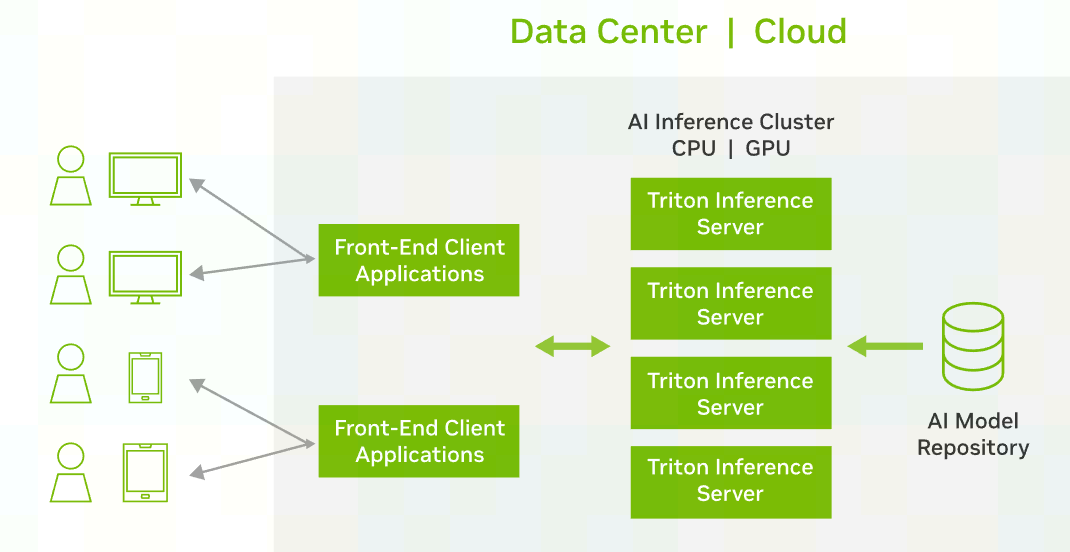
Triton
Triton是NVIDIA推出的以服务端-客户端方式工作的推理引擎,用于实现推理模型的服务化,其中:
1.客户端主要任务是加载/管理数据,发送推理请求到服务端,等到服务端传回推理结果,主要形式为个人计算设备等,有AI推理需求。
2.服务端主要任务是加载/管理模型,接受推理请求,计算推理结果,发送到到客户端,主要形式为AI数据中心和集群,可以提供AI推理计算服务。
3.图1所示为NVIDIA Triton官方网站的图片,容易理解Triton的工作方式和应用场景。
4.支持CPU/GPUs,模型并发运行,模型管理、加载与模型更新。
5.Triton支持后端(backend): TensorRT/TensorFlow/Pytorch Python/ONNX Runtime/OpenVino。
Triton 使团队能够部署来自多个深度学习和机器学习框架的任何AI模型,包括 TensorRT、TensorFlow、PyTorch、ONNX、OpenVINO、Python、RAPIDS FIL 等。 Triton支持在NVIDIA GPU、x86 和 ARM CPU 或 AWS Inferentia 上跨云、数据中心、边缘和嵌入式设备进行推理。Triton为许多查询类型提供优化性能,包括实时、批处理、集成和音频/视频流。
MagicMind
MagicMind是⾯向寒武纪MLU(Machine Learning Unit,机器学习单元)的推理加速引擎。MagicMind能将机器学习框架(Tensorflow,Pytorch 等)训练好的算法模型转换成 MagicMind 统⼀计算图表⽰,并提供端到端的模型优化、代码⽣成以及推理业务部署能⼒。MagicMind 致⼒于为⽤⼾提供⾼性能、灵活、易⽤的编程接⼝以及配套⼯具,让⽤⼾能够专注于推理业务开发和部署本⾝,⽽⽆需过多关注底层硬件细节。
Triton Python Backend + MagicMind Python
1.Triton支持采用Python作为后端的方式来实现推理模型的部署,同时MagicMind也为模型在MLU上的推理提供了Python编程接口,方便用户高效地部署模型。
2.因此可以采用Python编程语言实现Triton+MagicMind共用的方式来实现推理模型在MLU上的服务化。
Triton+MagicMind Bert模型部署实战
Triton Python Backend规定了客户端和服务端模型编程代码的框架(model_repository),用户只需要编写特定的文件来支持部署自己的模型,其中:
服务端主要编写model.py(模型推理实现)和config.pbxt(模型配置参数)来引导Triton Server服务的启动与运行。
客户端主要编写client.py来实现数据的加载与发送推理请求。
首先将项目代码git clone到本地,进入bert目录,该目录下主要包含magicmind_codes和triton_codes,其中magicmind_codes代码主要是在magicmind docker环境下将主流框架下的模型文件转换为MLU上支持的模型文件,便于后续的模型在MLU上进行推理部署。triton_codes代码主要则是实现推理模型在MLU上的服务化。
MagicMind代码
1.启动MagicMind Docker环境
bash run_docker_magicmind_bert.sh
2.准备环境
bash prepare_mm_env.sh
3.生成不同精度的MagicMind Model
bash magicmind_build.sh
4.MagicMind推理Demo
bash magicmind_infer.sh
Triton代码
Triton Python Backend主要通过model_repository进行server端和client端代码的编写,Triton规定Python Backend的model_repository目录结构如下:
 其中triton_python_backend_stub为需要自行定制生成,triton_codes已包含。
其中triton_python_backend_stub为需要自行定制生成,triton_codes已包含。
serve端model.py(triton_codes/mm_models/bert_case/1/mode.py)
model.py内部已经严格规定好只有一个类(TritonPythonModel)和四个成员函数(auto_complete_config,initialize,execute,finalize),我们只需要在该代码内部完成MLU设备的初始化和推理计算即可。
client端client.py(triton_codes/mm_models/bert_case/client.py)
client端代码主要完成数据的加载,在每一次从数据集中获取到数据集,便会向server端发起推理请求,得到server返回的推理结果后可用于精度计算,具体代码如下:
server端config.pbxt(triton_codes/mm_models/bert_case/config.pbxt)
启动Triton推理服务,利用Triton实现推理服务化
Server端
在mm_model/xx/1/model.py文件内可以指定特定精度的MagicMind模型
#运行Server Docker
bash run_docker_triton_server.sh
Server端环境安装
bash prepare_server_env.sh
Server端启动
bash start_triton_server.sh
Client端
在mm_model/xx/client.py文件内可以指定特定batch_size
Client Docker
bash run_docker_triton_client.sh
Client端环境安装
bash prepare_client_env.sh
Client端启动
bash start_triton_client.sh
Client端可开启perf_client进行性能测试 bs从1到32
bash start_triton_client_pref.s
热门帖子
精华帖子








 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复

 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读