打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
在知乎上看到一篇非常详实的MLU270使用教程,分享给大家!感谢原作者授权~~
原文地址:寒武纪显卡MLU270驱动包安装,Cambricon Pytorch模型移植,量化,生成离线模型教程 - 知乎 (zhihu.com)
以下为正文(还未完结,期待作者更新):
寒武纪的介绍可以看看它们的官网,更加详细,可以类比英伟达,但是英伟达做的是通用的图形加速器,而寒武纪的MLU是专用领域的图形加速器。
Ubuntu 18.04
MLU 270
从你的供应商拿到驱动包,名字如:neuware-mlu270-driver-dkms_xxx_all.deb。
然后在该文件目录下直接执行:
sudo dpkg -i neuware-mlu270-driver-dkms_xxx_all.deb
其实可以看到,其用DKMS来管理驱动,和安装N卡驱动非常类似。 要注意:就是内核版本一定要在其文档说明支持的范围内。
当安装成功后,执行:cnmon,可以看到一个类似nvidia-smi的信息,包含了加速卡的一些基本信息。

在寒武纪官网 寒武纪官网。下载cntoolkit,解压,然后选择自己的系统的deb包
按照官网的安装步骤:
#官网的安装步骤,先执行sudo dpkg -i cntoolkit_XXXXXX.deb#然后更新源sudo apt update#再安装cntoolkit中的所有文件sudo apt-get install cnas cncc cncodec cndev cndrv cnlicense cnpapi cnperf cnrt cnrtc cnstudio cngdb
也可进行下面的方法:
解压cntoolkit_xxx.deb。 目录在cntoolkit_1.7.3XXX/data/var/cntoolkit-1.7.3/ 找到里面的所有deb文件,选择自己需要的,直接解压安装
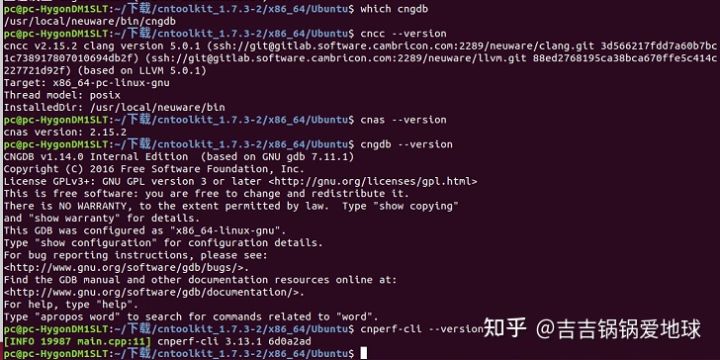
查询是否成功安装
$ cat /usr/local/neuware/version.txt $ dpkg -l | grep cncc $ dpkg -l | grep cnas $ dpkg -l | grep cncodec $ dpkg -l | grep cndev $ dpkg -l | grep cndrv $ dpkg -l | grep cngdb $ dpkg -l | grep cnpapi $ dpkg -l | grep cnperf $ dpkg -l | grep cnrt $ dpkg -l | grep cnrtc $ dpkg -l | grep cnstudio
会出现图示的内容。

然后配置环境变量
export NEUWARE_HOME="/usr/local/neuware"export PATH="${NEUWARE_HOME}/bin:${PATH}"export LD_LIBRARY_PATH="${NEUWARE_HOME}/lib64:${LD_LIBRARY_PATH}"#下面会出现对应包的路径which cncc
which cnas
which cngdb
which cnperf-cli查询cncc是否安装成功
cncc --version cnas --version cngdb --version cnperf-cli --version
在寒武纪官网下载好这些文件,包含cnnl,cnml,cncl,cnplugin,cntoolkit 然后挨个解压,选择自己当前的系统,比如Ubuntu,执行命令
#安装好cntoolkit后,先执行sudo apt update#XXXX换成对应的自己系统,每个文件都在对应的目录,跳转到该目录下执行这些命令。#最好是这个顺序,不然可能会有问题sudo dpkg -i cnml_XXXXXX.deb sudo dpkg -i cncl_XXXXXX.deb sudo dpkg -i cnplugin_XXXXXXX.deb sudo dpkg -i cnnl_XXXXX.deb #这个可能要慢一些
安装好后执行命令:
/usr/local/neuware/bin/cncc --version
出现下面这个,表示安装成功了

为了避免编译复杂的文件复制的环境配置,推荐使用寒武纪官方的Docker镜像。有关docker常用的命令,可以参考
拉取网址:
需要提前登录到寒武纪,需要登录到habor,账号密码从供应商拿到。
将拉取命令复制到终端(加不加sudo取决于自己的Docker安装方式):
sudo docker pull cair.cambricon.com/cambricon/cambricon_pytorch:ubuntu18.04_sdk_v1.7.0_pytorch_v0.15.0-2
查看当前所有的Docker的Image镜像
sudo docker images -a
创建容器,-it表示以交互式的终端创建容器,--net如果不使用远程docker就不用管它,-v指定将docker的容器创建到宿主机的目录,--privileged指定使用主机上的寒武纪显卡。
sudo docker run -it --privileged --net=host [--name xxx] [-v hostPath:containerPath] cair.cambricon.com/cambricon/cambricon_pytorch:ubuntu16.04_sdk_v1.7.0_pytorch_v0.15.0-2 /bin/bash
注:cambricon pytorch的Docker上的python解释器是1.3版本的
由于pytorch需要的权重文件格式是pth,而darknet生成的权重文件格式是weights,因此还需要将其转换成pth格式,如果本身是pth就不用转换了。
这里由于各个任务的不同,所以量化的.py文件里的内容也有所不同,这里我以分类模型的ResNet为例。量化文件是quantize.py。
这个量化模型的quantize.py要进行部分的修改
⚠️注意:高,宽 以及num_classes都要对应修改
修改对应的数据,如图。

然后执行
python quantize.py
生成量化模型
这里解释下关于量化函数参数的意义。
torch_mlu.core.mlu_quantize.quantize_dynamic_mlu(model,qconfig_spec=None,dtype=None,mapping=None,inplace=False,gen_quant=False)
model:待量化的model。在生成量化模型的时候,model必须是加载了pth的model。在运行量化模型时,model不必加载pth,仅仅是原先网络的定义即可 qconfig_spec:配置的量化字典 dtype:设置的量化模型。支持int8,int16。字符串
mapping:设置量化的层
inplace:是否是深复制,(深复制节约内存)
gen_quant:是否生成量化。默认为=False。在要生成量化模型时,设置gen_quant=True。在要运行量化模型时设置gen_quant=False.
下面介绍qconfig_spec的字典含义:{'iteration':1,'use_avg':False,'data_scle':1.0,'mean':[0,0,0],'std':[1,1,1],'firstconv':True,'per_channel':False}
iteration:设置用于量化的图片数量。默认=1。(现在的版本已经被丢弃了)
use_avg:设置是否使用最值的平均值用于量化。默认=False。
data_sacle:设置是否对图片进行最值的缩放。默认=1.0.即不缩放
mean:设置对数据的图片的均值。默认为[0,0,0]。即 减去均值 0
std:设置对数据集的图片的方差。默认为[1,1,1].即 除以方差1.
firstconv:设置是否使用firstconv。默认为True,即使用firstconv。如果设置为False,则上述的mean和std参数失效,不会参与第一个卷积的数据预处理计算。
per_channel:设置是否使用分通道进行量化。默认=False
离线模型的生成也是和量化模型的文件是类似的,还是以ResNet的分类模型为例,gen_offiline.py文件里,主要修改输入图的shape和输出num_classes,修改为对应的数据。如图
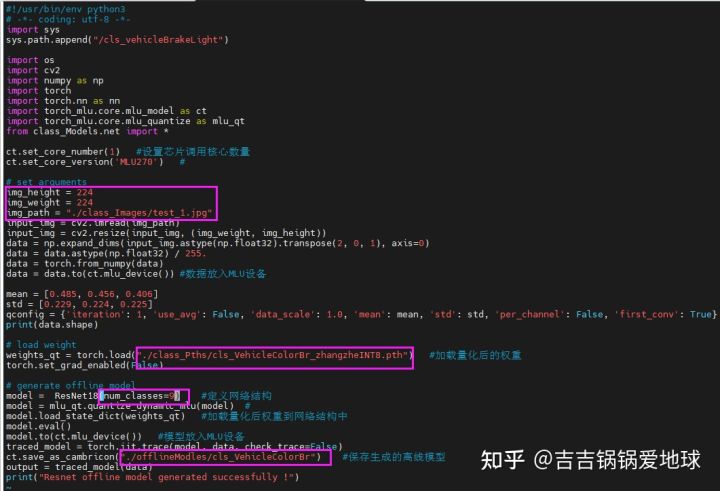
然后执行python gen_offline_model.py生成离线模型
⚠️注意:
⚠️代码ct.save_as_cambricon("./offlineModels/cls_VehicleColorBr")的这个路径的
⚠️文件夹必须是已经存在的。否则会报错,而且错误很难找。
关于测试,由于我没有测试数据,这里暂时省略了
地址如下,需要登陆过后才能pull。
界面如图

这里我们下载cambricon_caffe。依次点击cambricon_caffe->历史版本->选择自己的系统版本->ubuntu18.04XXXXX->复制提取命令。然后打开终端进行pull(拉取前还要进行Docker的账户和密匙配对)。

下载后如图使用sudo docker image -a 查看刚刚拉取的镜像。

通过命令sudo docker run -it XXX镜像IDXXX /bin/bash创建对应镜像的容器实例,然后进入交互式终端。

为了方便我们下载一些工具,主要有ssh,vim。直接使用apt-get install XXX就可以了。
到这里,基本的东西就解决完了。
不管是yolov4还是yolov3,都会包含两个文件,一个是XXX.cfg,一个是XXX.weights。前者是配置网络模型的各个参数,后者是训练生成的权重。没有这两个文件的也可以去寒武纪官网下一个。

使用cambricon_caffe的docker里的caffe/python/darknet2caffe-yoloV4.py。将cfg和weights转换成prototxt和caffemodel。执行
python darknet2caffe-yoloV4.py XXXcfg的文件路径XXX XXXweights权重文件路径XXX XXX保存的prototxt文件路径XXX XXX保存的caffemodel文件路径XXXX
比如。
python darknet2caffe-yoloV4.py yolov4.cfg yolv4.weights ./yolov4.prototxt ./yolov4.caffemodel
注意:V3V2系列和V4有一点不同,那就是使用darknet2caffe-yoloV23.py。比如(下面的3和2,表示指定使用的是v2模型还是v3模型)
python darknet2caffe-yoloV23.py 3 yolov3.cfg yolov3.weights ./yolov3.prototxt ./yolov3.caffemodel
转换成功后,就能够生成对应的prototxt和caffemodel。
然后使用命令修改刚刚生成的prototxt文件
vim yolov4.prototxt
分别修改输入部分,添加输出部分。#部分表示注释,记得删除
#添加输入,dim维度需要和输出的维度保持一致,要么都是608,要么都是416
input: "data"
input_shape {
dim: 1
dim: 3
dim: 416 #按需修改
dim: 416 #按需修改
}
#修改最后输出
{
bottom: " 82-conv" #可以通过可视化,判读需要连接的层
bottom: " 94-conv" #可以通过可视化,判读需要连接的层
bottom: " 106-conv" #可以通过可视化,判读需要连接的层
top: "yolo_1"
name: "yolo- "
type: "Yolov3Detection" #v3和v4都需要改成v3,这里我目前还不知道怎么回事
yolov3_param { #v3和v4都需要改成v3,这里我目前还不知道怎么回事
im_w:416 #按需修改
im_h:416 #按需修改
num_box:1024
confidence_threshold:0.005
nms_threshold:0.45
biases:[116,90,156,198,373,326,30,61,62,45,59,119,10,13,16,30,33,23]
}
}我们可以使用如下工具帮助我们可视化。caffe的prototxt的可视化工具有
热门帖子
精华帖子






 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读