打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
本文是作者在适配LPRNet过程中遇到的性能问题,以部分代码为引导,介绍如何做模型等价替换性能提升,有将的不到位的地方还请见谅。
首先LPRNet是一个轻量级的车牌识别网络,下面是论文和代码链接。
附上论文地址:https://arxiv.org/abs/1806.10447?context=cs
代码链接:https://github.com/sirius-ai/LPRNet_Pytorch
由于LPRNet模型较为简单,适配起来不难,此文写在适配过LPRNet的基础上,并对性能做一定的优化。
如果模型适配完后在mlu上的性能较差,我们是可以利用cnperf工具来分析性能的瓶颈,下面是一张cnperf出来的图。
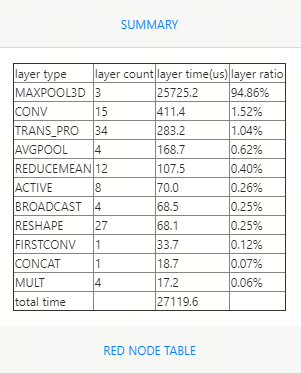
可以看到整个网络的性能被MAXPOOL3D所占用。
这个时候我想能不能用maxpool2d来代替目前版本性能不佳的maxpool3d。于是有了下面的测试代码,
import torch import torch.nn as nn class Pool3d(nn.Module): def __init__(self): super(Pool3d, self).__init__() self.pool3d = nn.MaxPool3d(kernel_size=(1, 3, 3), stride=(1, 1, 1)) def forward(self, x): return self.pool3d(x) class Pool2d(nn.Module): def __init__(self): super(Pool2d, self).__init__() self.pool2d = nn.MaxPool2d(kernel_size=(3, 3), stride=(1, 1)) def forward(self, x): return self.pool2d(x) net_3d = Pool3d() net_2d = Pool2d() input_data = torch.randn(1, 64, 24, 92,dtype=torch.float) output_3d = net_3d(input_data) output_2d = net_2d(input_data) print(torch.equal(output_3d, output_2d))
LPRNet中有3个maxpool3d,这是第一个maxpool3d,并且第一个kernel_size 和stride都是1,所以对channel方向来说,输入输出是一样的,所以该操作理应可以用maxpool2d来代替。
于是测试net_3d和net_2d在cpu上运行的结果,并通过torch.equal来比较,发现两个结果是一模一样,所以第一个maxpool3d就这样被替换了。替换之前我们也需要测试一下mlu上的性能,
import torch
import torch.nn as nn
import torch_mlu
import torch_mlu.core.mlu_model as ct
import torch_mlu.core.mlu_quantize as mlu_quantize
torch.set_grad_enabled(False)
class Pool3d(nn.Module):
def __init__(self):
super(Pool3d, self).__init__()
#self.pool3d = nn.MaxPool3d(kernel_size=(1, 3, 3), stride=(1, 1, 1))
self.pool3d = nn.MaxPool2d(kernel_size=(3, 3), stride=(1, 1))
def forward(self, x):
return self.pool3d(x)
net = Pool3d()
input_data = torch.randn(1, 64, 24, 92,dtype=torch.float)
input_data_mlu = input_data.type(torch.HalfTensor).to(ct.mlu_device())
ct.set_core_number(4)
quantized_net = torch_mlu.core.mlu_quantize.quantize_dynamic_mlu(net)
quantized_net.eval()
quantized_net.to(ct.mlu_device())
ct.save_as_cambricon("pool3d")
quantized_net = torch.jit.trace(quantized_net, input_data_mlu, check_trace = False)
output = quantized_net(input_data_mlu)在Pool3d中self.pool3d分别用maxpool3d和maxpool2d来运行,测试mlu上的性能可以发现,maxpool2d的性能是us级别,而maxpool3d的性能是15ms级别。
下面我们考虑第二个maxpool3d,nn.MaxPool3d(kernel_size=(1, 3, 3), stride=(4, 1, 2))
可以发现stride第一个值不是1了,所以我们不能把maxpool3d直接改成maxpool2d,但是第二个stride是1,所以我考虑通过两次maxpool2d来达到一次maxpool3d的效果。
下面同样附上相关的测试代码:
import torch import torch.nn as nn class maxpool_3d(nn.Module): def __init__(self, kernel_size1, kernel_size2, stride1, stride2): super(maxpool_3d, self).__init__() self.maxpool1 = nn.MaxPool2d(kernel_size=kernel_size1, stride=stride1) self.maxpool2 = nn.MaxPool2d(kernel_size=kernel_size2, stride=stride2) def forward(self, x): x = self.maxpool1(x) x = x.transpose(1,3) x = self.maxpool2(x) x = x.transpose(1,3) return x class Pool3d(nn.Module): def __init__(self): super(Pool3d, self).__init__() self.pool3d = nn.MaxPool3d(kernel_size=(1, 3, 3), stride=(4, 1, 2)) def forward(self, x): return self.pool3d(x) net = Pool3d() net_3d = Pool3d() net_2d = maxpool_3d(kernel_size1=(3,3), stride1=(1,2), kernel_size2=(1,1), stride2=(1,4)) input_data = torch.randn(1, 64, 24, 92,dtype=torch.float) output_3d = net_3d(input_data) output_2d = net_2d(input_data) print(torch.equal(output_3d, output_2d))
上面的做法主要是先将后两维做maxpool2d,作完一次maxpool2d后通过transpose将后两维中的某一位transpose到channel的维度上,继而可以继续将channel维度做maxpool2d,运行后同样输出True,说明替换是等价的。同样测试mlu上的性能maxpool2d的收益较大。
下面将这种方法应用到网络中,再输出cnperf后的结果,发现提升真的非常大。
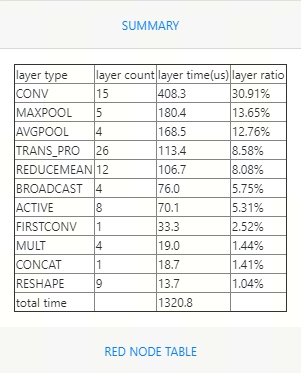
好了,本次分享到此结束。
热门帖子
精华帖子






 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复


 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读