打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
【CN-TF4】基于 Cambricon TensorFlow2 的horovod分布式训练
https://zhuanlan.zhihu.com/p/610695398
若是初学者,建议先看前面的,尤其是其中 TensorFlow2 相关的模块。
该课程主要专业术语:
| 本文简称 | 标准名词 | 解释 |
| TensorFlow2 | TensorFlow2 | 谷歌开源的 AI 框架 |
| CambriconTensorFlow2 | CambriconTensorFlow2 | 为支持寒武纪 MLU,寒武纪对 TensorFlow2进行了定制 |
| CNCL | CambriconCommunicationsLibrary | 寒武纪通信库,是一个基于 MLU 设计的高性能通信库 |
| CambriconHorovod | CambriconHorovod | 适配了 CambriconTensorFlow2与 MLU 的 Horovod框架 |
单机训练现状:随着模型结构越来越复杂或者数据量越来越大,单机训练所需时间不断增加,甚至可能出现模型或数据无法在单机上一次性加载的问题。
分布式训练:分布式架构将训练任务按照某种策略拆分到多个计算节点(机器)进行计算,再遵循一定的规则将上一步计算得到的结果进行聚合,从而高效地完成训练任务。
分布式架构
参数服务器架构(Parameter Server, PS)
集合通信架构(Collective Communication, CC)
分类
数据并行
模型并行
流水线并行
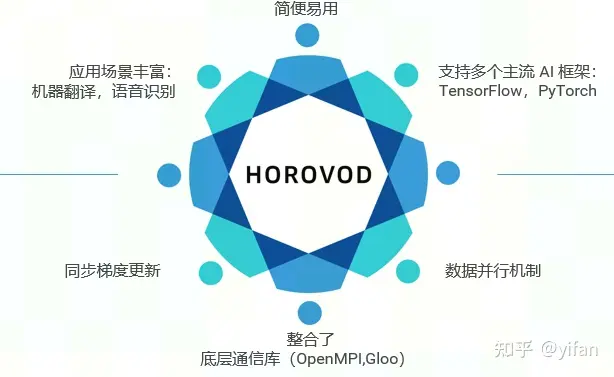
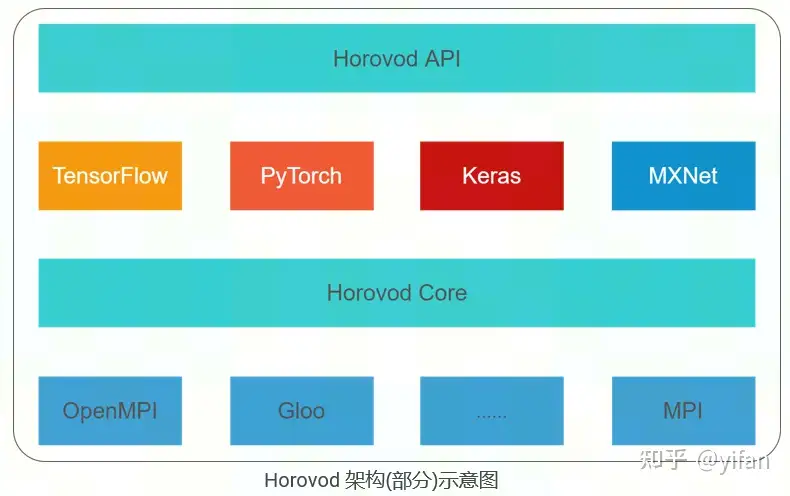
Horovod是 Uber 在2017年发布的一个简便易用的高性能分布式训练框架,整合了底层集合通信库(Openmpi, Gloo等),简化了多节点分布式训练开发流程,支持 TensorFlow, PyTorch, Keras和MXNet, 使得上层框架无需关心底层通信。
1)MPI概述
MPI(MessagePassingInterface)是一个定义了多个通信原语的消息传递接口,常用于多进程间的通信,常见的通信原语包括:点对点通信(SEND, RECV等),集合通信(BROADCAST, GATHER, SCATTER,REDUCE, ALLREDUCE 等)
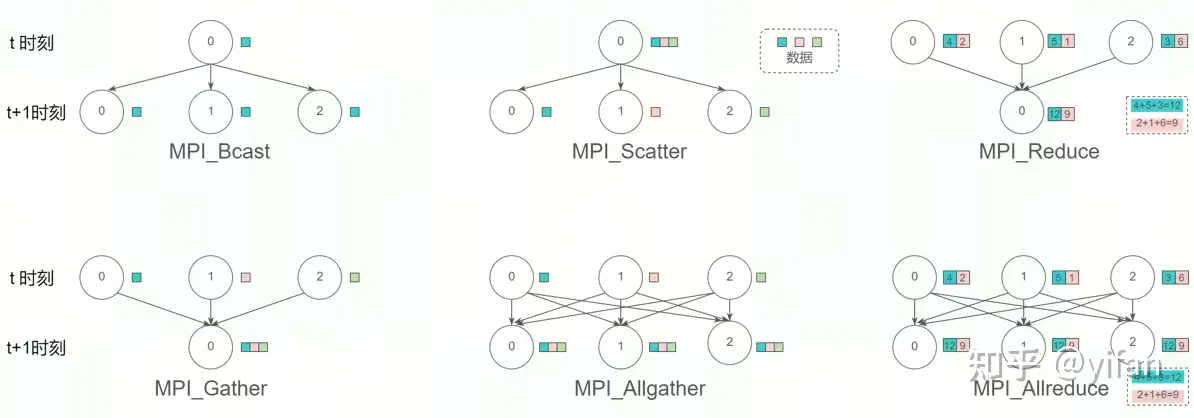
OpenMPI和 Gloo等通信库是 MPI 的常用实现,实现了 BROADCAST, GATHER, REDUCE, ALLREDUCE 等相关接口。
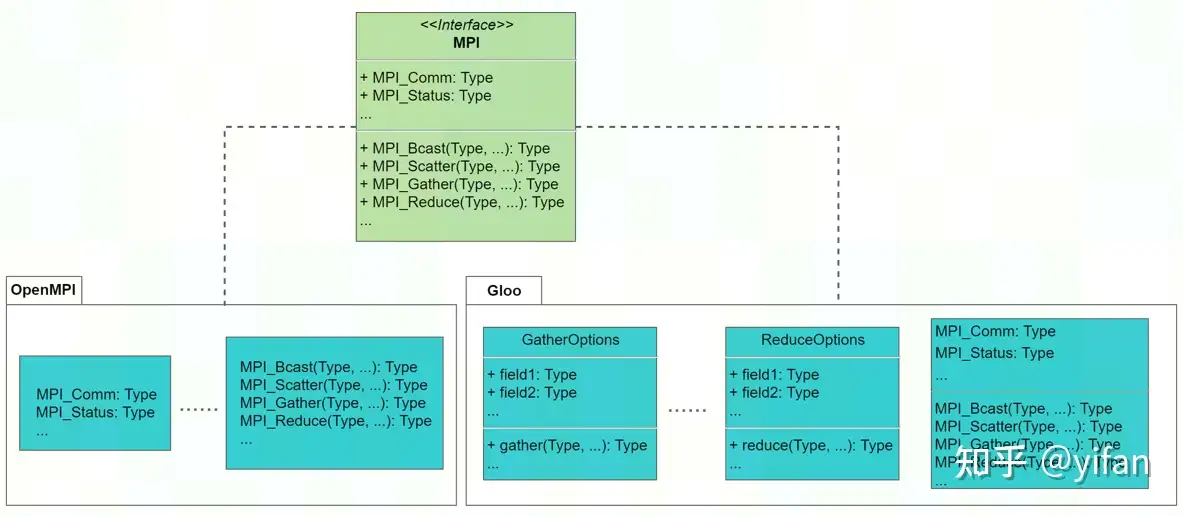
2)Horovod与 MPI的关系
Horovod底层整合了 OpenMPI和 Gloo等通信库,并借助它们实现了 TensorFlow, PyTorch框架训练过程中节点之间的分布式通信,例如节点之间的梯度同步。
3)Ring-Allreduce算法简介
使用 Horovod 进行分布式训练时,设备(节点)之间的梯度同步通常使用 Ring-Allreduce 算法,
该算法底层依赖 Allreduce通信算法。
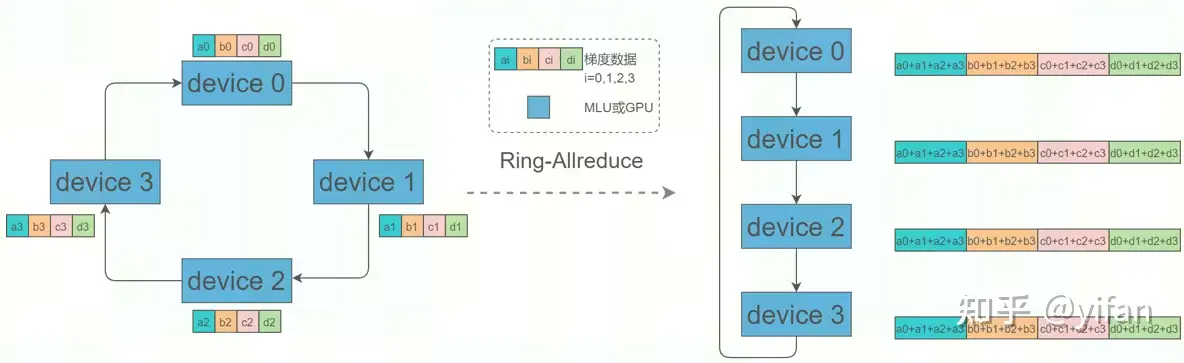
使用Horovod进行分布式训练时,设备(节点)之间的梯度同步通常使用Ring-Allreduce算法。初始时,各设备上的梯度均是完整梯度的一部分,如左图所示,0号设备只有a0,b0,c0,d0梯度数据,完整的梯度数据是右图所示,经过该算法后,各设备均获得一份完整的梯度。
① Scatter-Reduce 阶段:
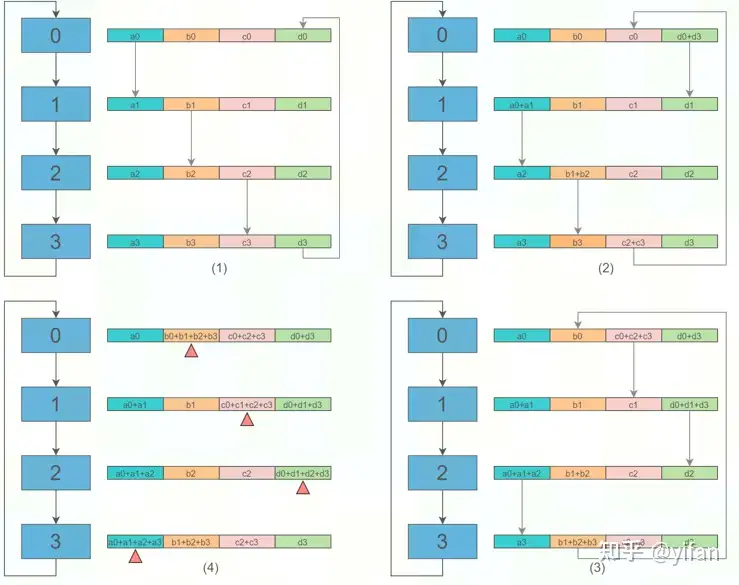
N 个设备逐步交换彼此的数据(梯度),最终每个设备都各自包含完整梯度的 1/N 部分(此处 N=4) 。
假设环中有N 个设备,每个设备有长度相同的数组,需要将设备的数组进行求和。
在 Scatter-Reduce阶段,每个设备会将数组分成 N 份数据块,然后设备之间进行 N 次数据交换。
在第k 次数据交换时,第 i个 设备会将自己的 (i - k) % N 份数据块发送给下一个设备。
接收到上一个设备的数据块后,设备会将其与自己对应的数据块求和。
② Allgather阶段
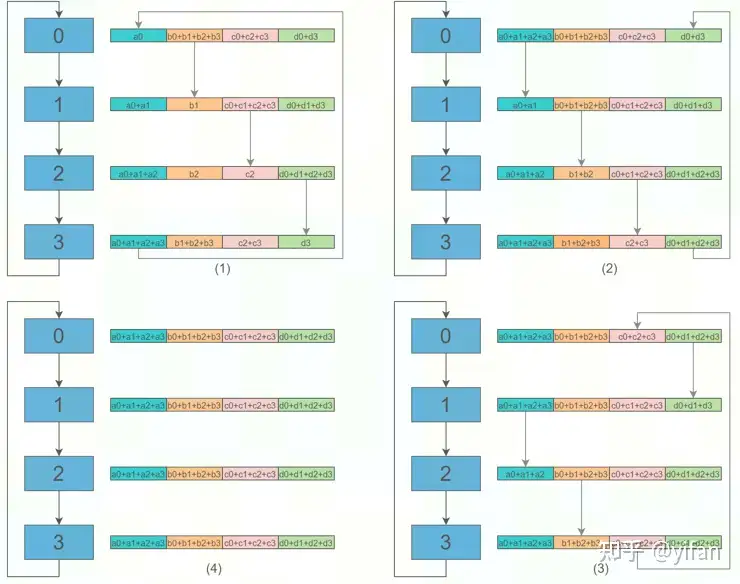
各设备会逐步交换彼此不完整的融合梯度,最后所有设备都会得到完整的最终融合梯度。
共需要 N 次循环。
在第 k 次循环时,第 i 个设备会将其第 (i+1-k)%N 个数据块发送给下一个设备。
接收到前一个设备的数据块后,设备会用接收的数据快覆盖自己对应的数据块。
进行 N 次循环后,每个设备就拥有了数组各数据块的最终求和结果。
4)与 TensorFlow的结合
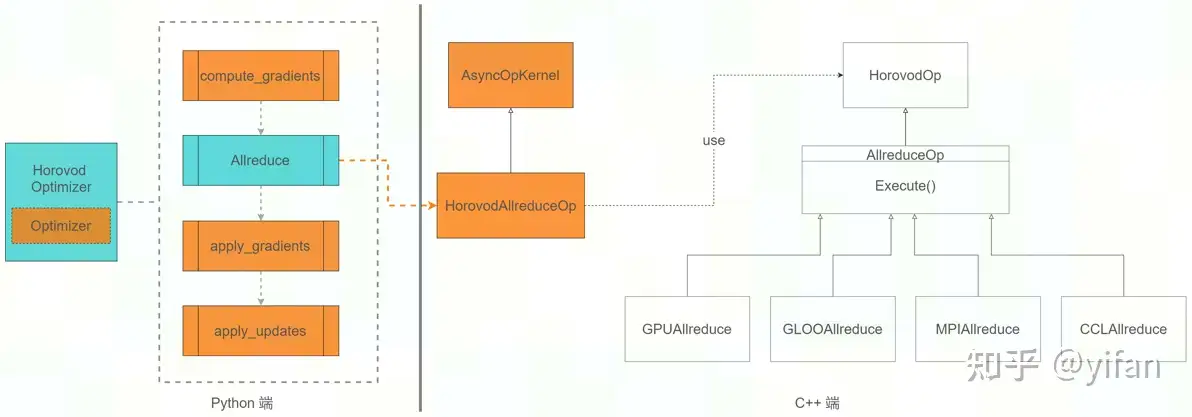
Horovod对 TensorFlow 的主要修改:使用 HorovodOptimizer 对 TensorFlowOptimizer 进行了封装,获取了梯度,并对梯度进行规约(Allreduce)。
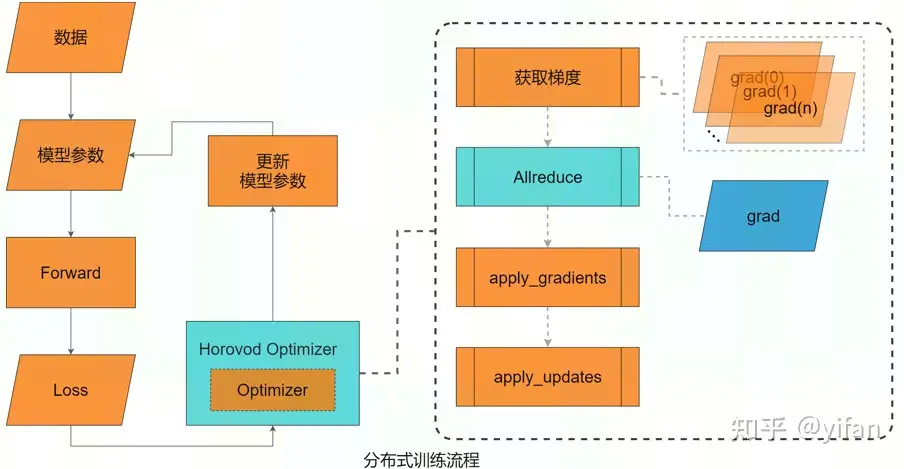
更具体而言:将 HorovodAllreduceOp 注册为 TensorFlowOP, 使其可以被 TensorFlow 执行,并在该 OP 内部调用通信库的 Allreduce 算法,实现梯度规约。具体实现:继承 TensorFlow 的 AsyncOpKernel。
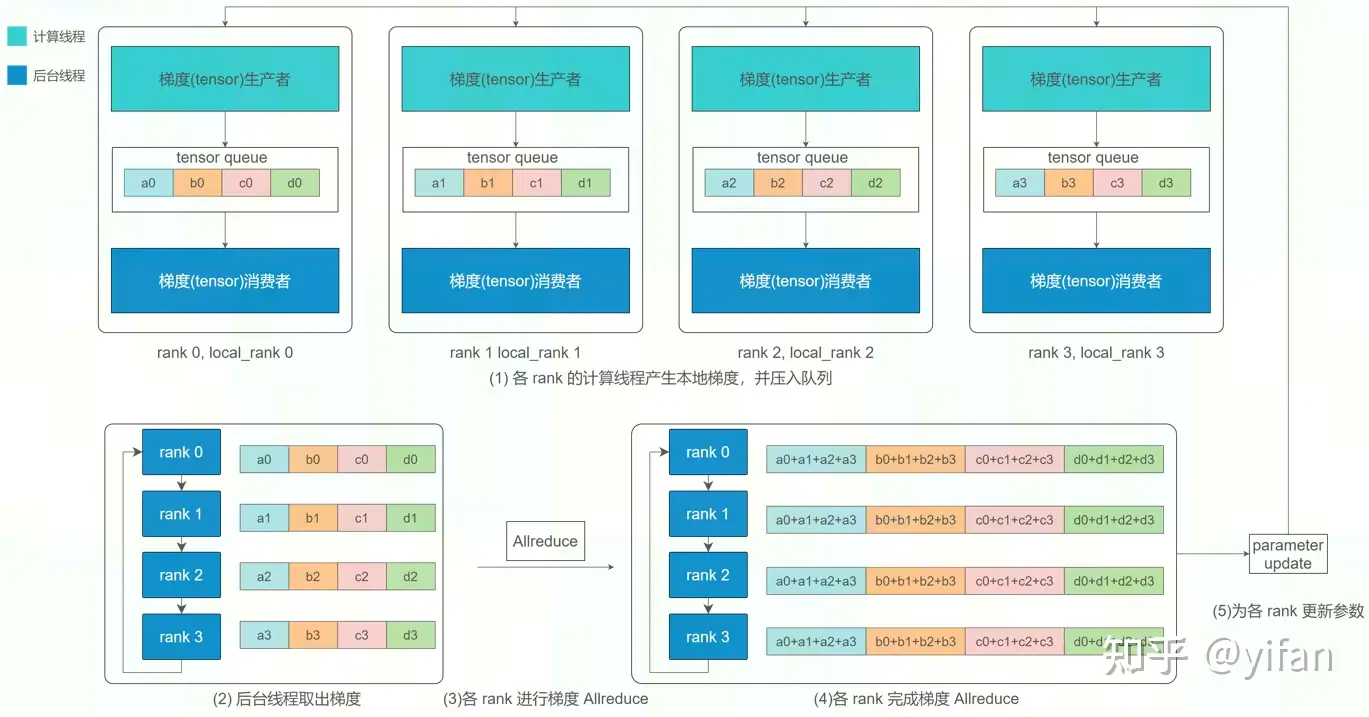
5)梯度同步
Horovod的数据传递基于 MPI,因此其涉及的术语也由 MPI 定义。以2台服务器,每台服务器4张 MLU 为例:
rank : 进程的唯一ID,0-7
local_rank: 每台服务器中的进程的本地唯一ID,0-3

每个 rank 都有计算线程与后台线程
计算线程负责 rank 本地的梯度计算
后台线程负责 rank 之间的通信与梯度 Allreduce。
两个线程之间的配合遵循生产者-消费者模式
rank 之间如何知晓是否完成了相关操作的呢 ?
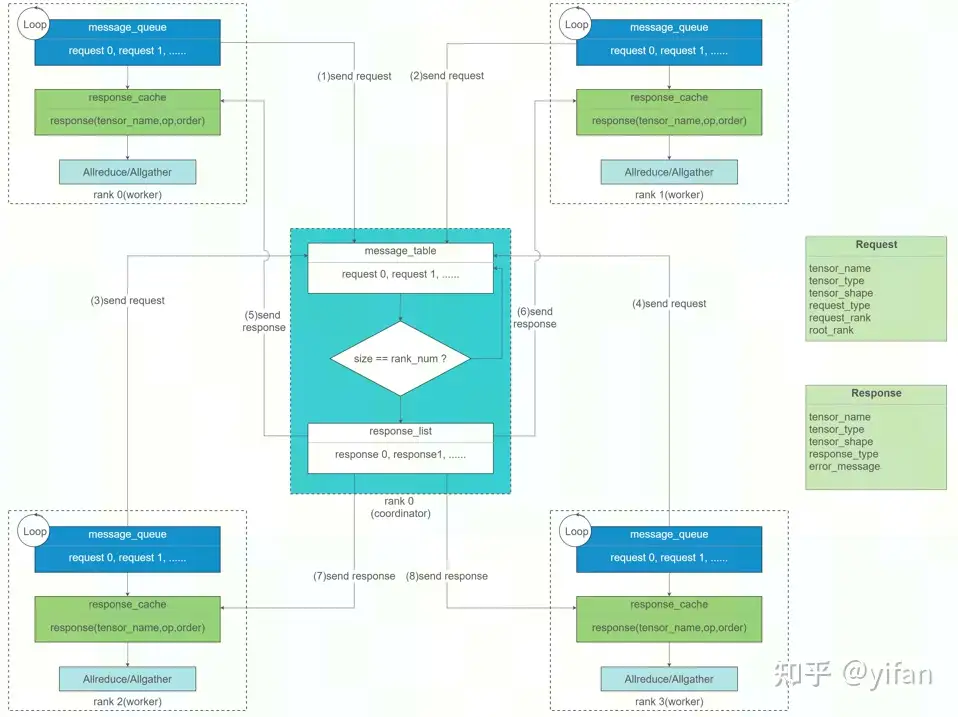
使用 rank0 作为 coordinator,协调所有 rank 的梯度同步进度。
各 rank 会将已经就绪的梯度 tensor 信息压入 message_queue,并发送给 rank0
rank0 收集到所有 rank 的 request 后,便会向所有 rank 发送 response
各 rank 收到 response 后,从各自的 message_queue 取出 tensor 信息开始进行 Allreduce 操作。
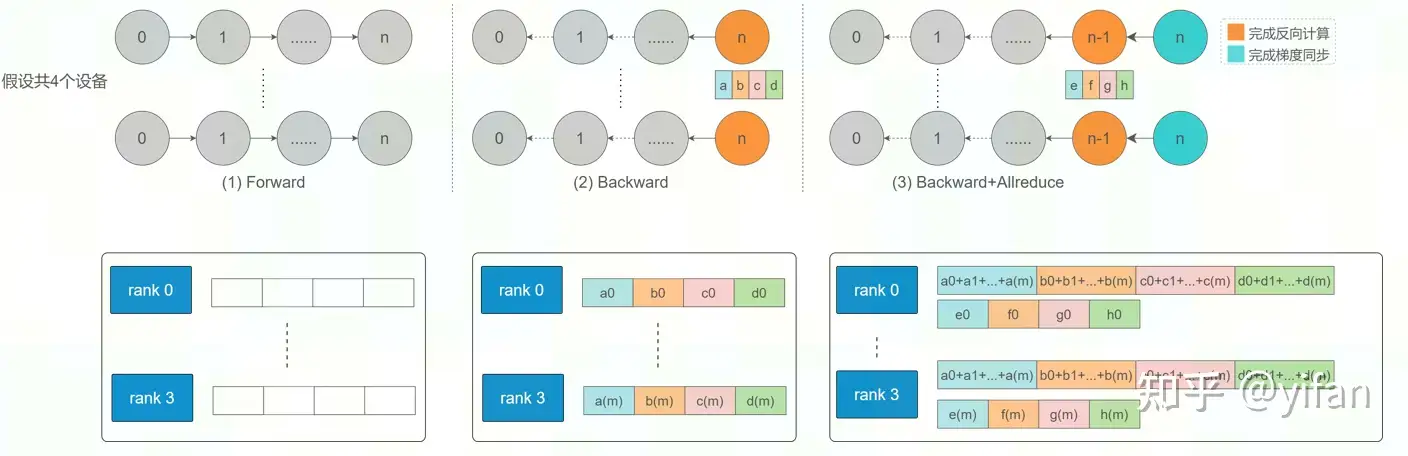
同步的其他细节:
各 rank 只针对网络同一层梯度进行同步
网络反向计算梯度与梯度同步可同时进行,即后面的层在进行梯度同步,前面的层在计算反向梯度
在寒武纪软件栈中,CambriconHorovod与 TensorFlow, PyTorch等框架位于同一位置。CambriconHorovod通常配合 CambriconTensorFlow 一起使用
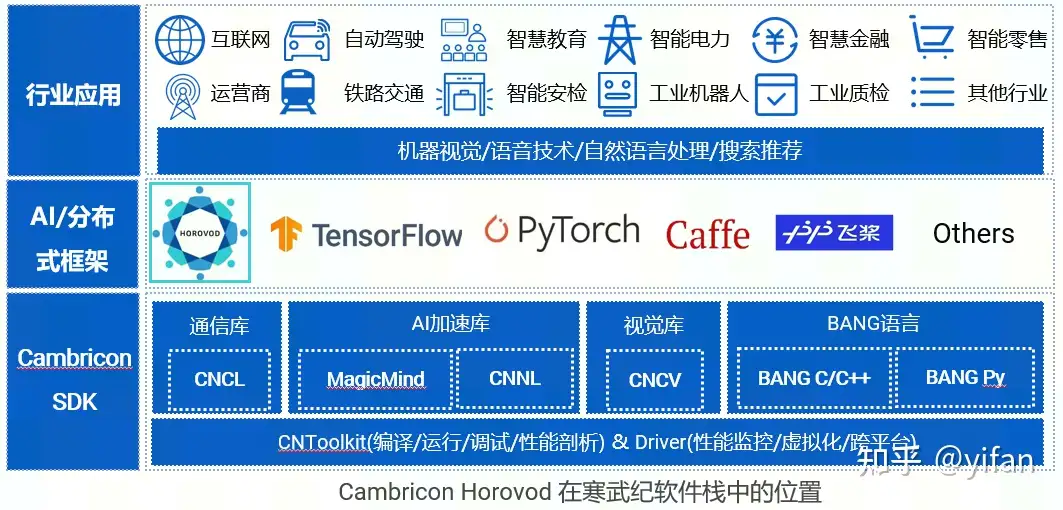
CambriconHorovod:在 Horovod的基础上,适配了 CambriconTensorFlow 与 CNCL 底层通信库,新增了对 MLU 设备的支持,使其可以在 MLU 上进行分布式训练。
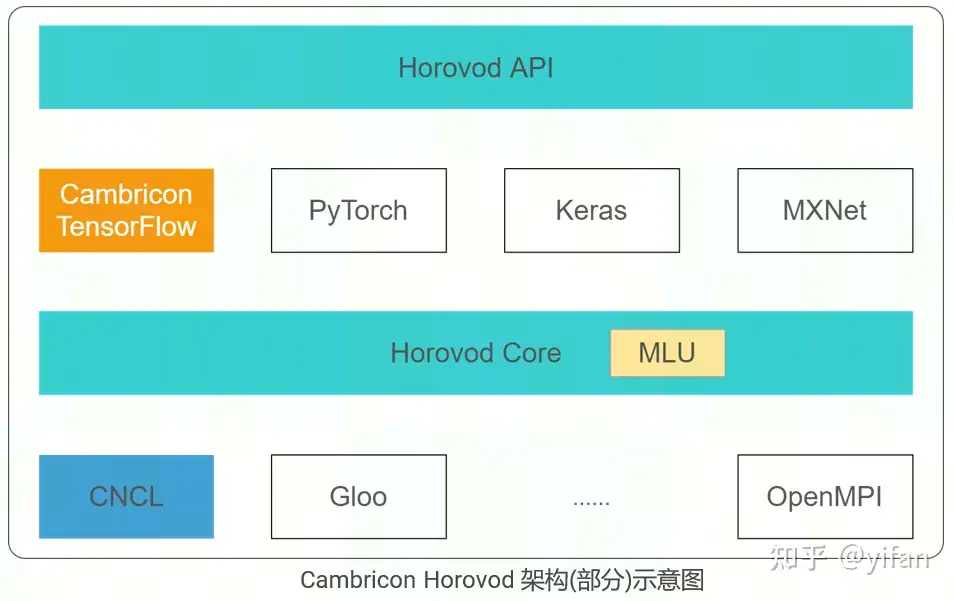
1)对 Horovod的主要修改
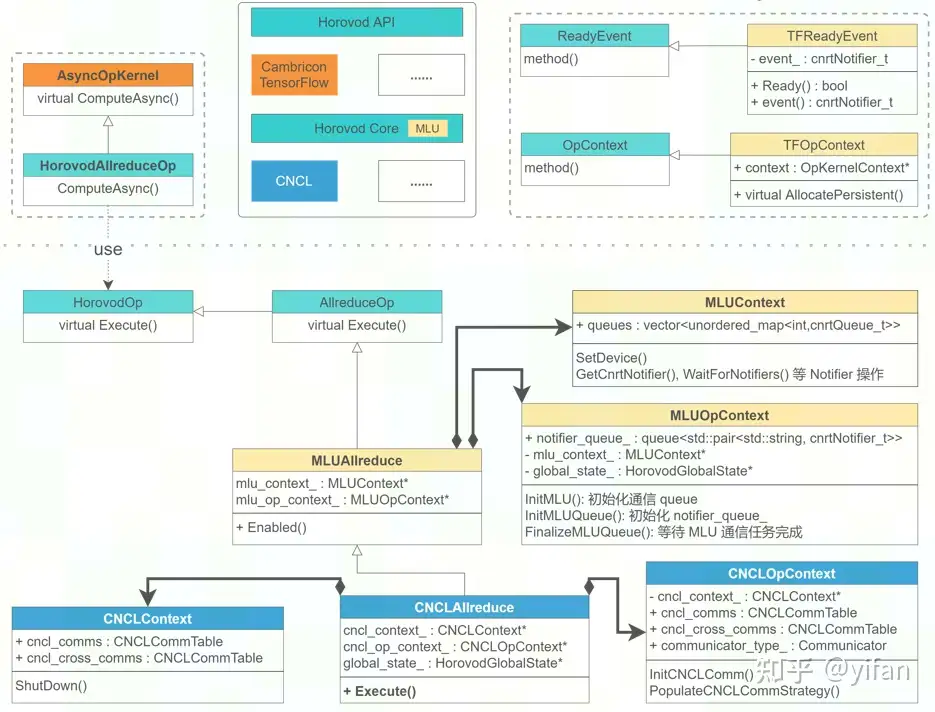
① TensorFlow 层面:注册 TensorFlow 算子,使CambriconTensorFlow 可以调用 HorovodAllreduceOp。
② Horovod层面:
创建 MLUAllreduce类,负责Allreduce时 MLU 相关的内存拷贝及下发 AllreduceOP至 CNCL 执行;
创建 CNCLAllreduce类,封装了CNCL 底层通信原语,在MLU 上实现 Allreduce。
创建 TFOpContext类,为Alllreduce的输出分配内存。 TF 在执行 HorovodAllreduceOp时,通过 AllocatePersistent() 为 Allreduce的输出(待执行规约的梯度 tensor)分配MLU 内存。
创建 TFReadyEvent类,提供计算队列与通信队列之间的同步。
TF 会向计算队列压入计算梯度的任务。
往计算队列插入 Notifier,保证通信队列取 tensor 时 tensor 已就绪。
通信队列会对 tensor 进行 Allreduce。
TF 进行梯度更新时会检查通信队列的Notifier,保证通信任务已完成。
调度协调资源:
创建 MLUContext类,主要负责MLU 的设备管理及多个任务队列间的协调。
创建 MLUOpContext类,主要负责MLU 通信队列管理及与计算队列的协调。
创建 CNCLContext类,主要负责CNCL 通信子的封装及资源释放。
创建 CNCLOpContext类,主要负责CNCL 通信域的创建。
2)CNCL 简介
CNCL(CambriconCommunicationLibrary,寒武纪通信库)是面向 MLU 设计的高性能通信库,用于完成 MLU 设备之间的数据传输,参考了 MPI 对各种通信原语的定义。
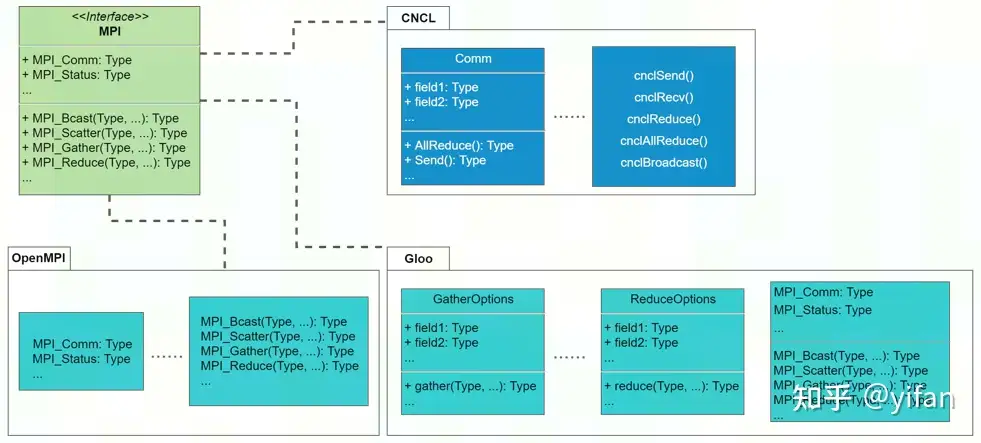
实现了基于 MLU 的多机多卡点对点通信与集合通信操作,如 SEND,BROADCAST, REDUCE。
支持多种 MLU 芯片互联技术,如 PCIe, MLU- ,RoCE等。
可根据 MLU 芯片的互联拓扑关系,自动地选择最优的通信算法和数据传输路径,最大化地利用带宽资源
SyntaxHighlighter.all();
热门帖子
精华帖子





 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读