打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
【CN-TF5】基于 Cambricon TensorFlow2 的混合精度训练
https://zhuanlan.zhihu.com/p/610697049
若是初学者,建议先看前面的,尤其是其中 TensorFlow2 相关的模块。
使用原因
训练现状:网络在训练时,网络参数的数据类型默认为 FP32,随着模型结构越来越复杂,训练所需显存与时间均不断增加。
混合精度训练:在训练过程中,网络参数的数据类型使用 FP32/FP16,从而在保证训练精度的前提下,尽可能减小所需显存,提升训练速度。
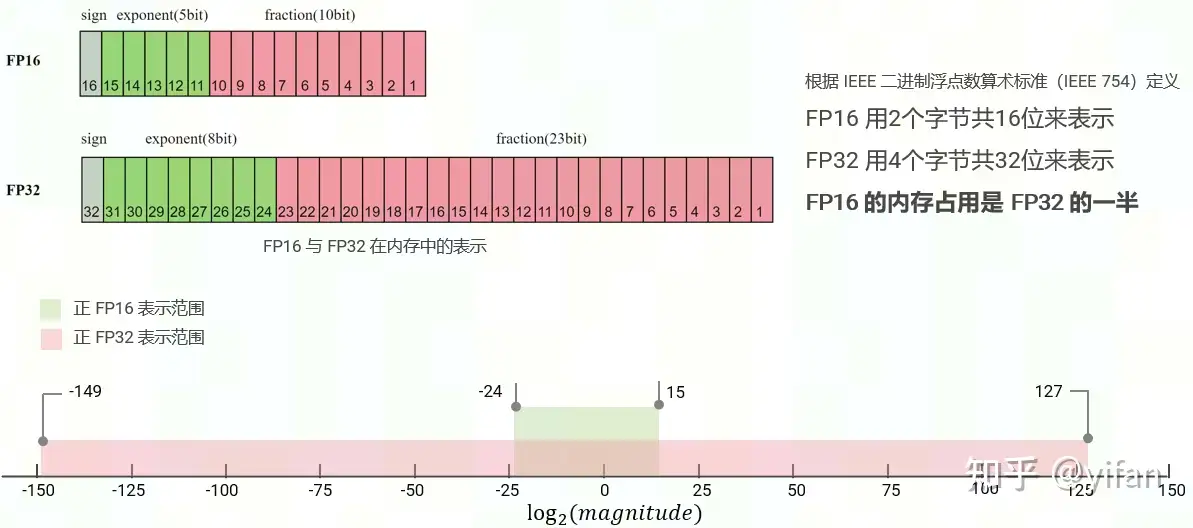
这里对fp16的[-24,15]表示范围做下注解:16个比特位分3部分:符号位 , 指数部分, 小数部分。
符号位: 1代表负数, 0代表正数。
指数部分,5个比特位, 全0和全1有特殊用途,所以是00001~11110, 也就是1到30, 人为设置偏置15,指数部分最终范围为-14 ~15. (Emin = 000012 − 011112 = −14;Emax = 111102 − 011112 = 15;Exponent bias = 011112 = 15)
小数部分, 10个比特位, 范围为(0~1023)/1024.
对应的计算方法:
fp16 的最大值为:
fp16 的最小值为:
注意, 有2个特殊情况, 也就是上面说的指数位全0和全1的特殊用途。
1)exponent全0 计算公式为:
,所以最小进度精度为:
。这也是上图中绿色部分左侧 -24 的来源。
2)exponent全1 计算公式为:
如果fraction全0 , 则表示+inf或者−inf
如果fraction不全为0 , 则表示 NaN
综上所述: 正数取对数得到表示图中的取值方位:[ -24, 15 ]
1)优缺点
优点:显存减小;batch 增大;通信量减小;训练速度加快
缺点:数据溢出;舍入误差
2)数据溢出
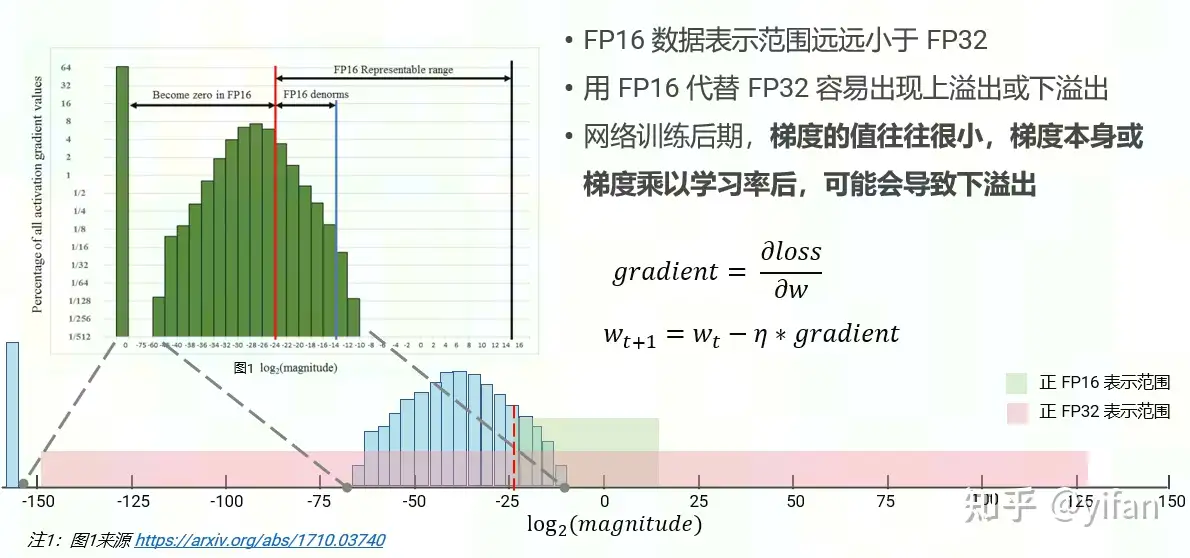
3)舍入误差

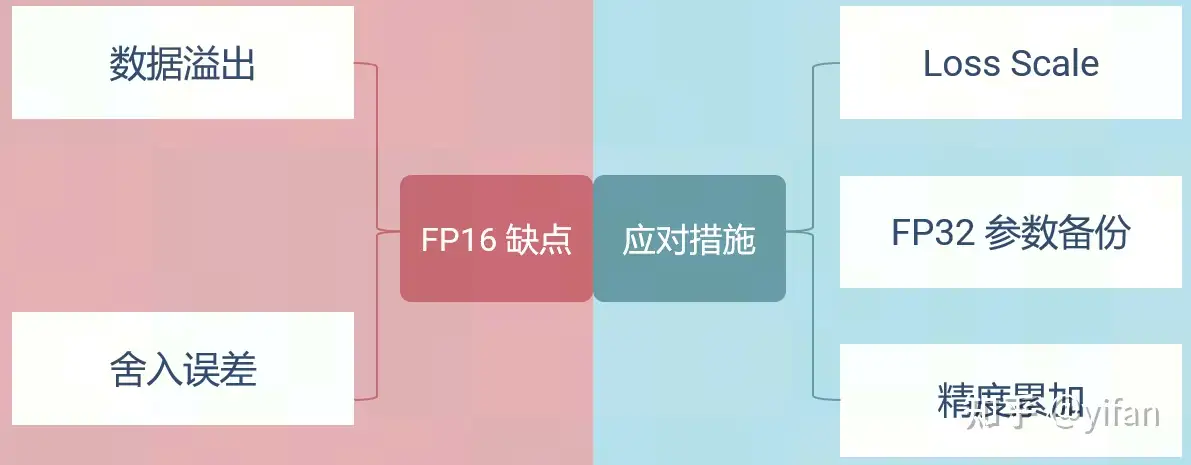
1)Loss Scale
主要思想就是缩小或扩大一定比例进行调整到所求范围。
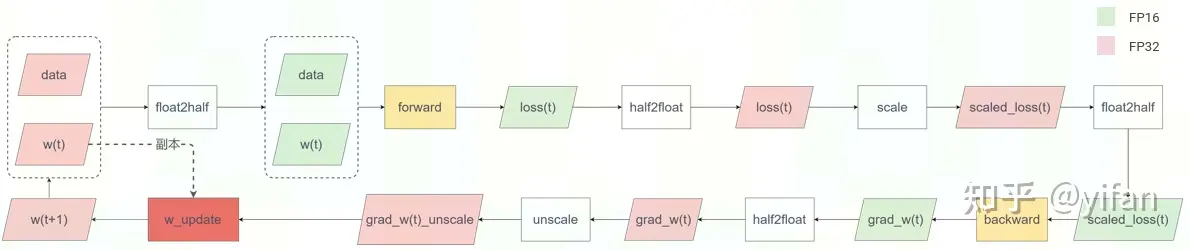
对前向过程得到的误差 loss 放大 scale 倍,如下图所示。根据链式法则,网络中每一层的梯度均随之放大并落在 FP16 有效范围内,避免了下溢出
从而可使用 FP16 存储梯度
并在更新参数前将梯度缩小 scale 倍

2)FP32 权值备份
梯度 * 学习率的值往往较小,用 FP16 表示梯度时,可能会导致:
梯度 * 学习率的值超出 FP16 的表示范围,即小于 ,出现下溢出
梯度 * 学习率和模型参数相加后可能会出现舍入误差的问题,如在 FP16 精度下:
应对措施:
Loss Scale,即下图的右半部分
参数备份:前后向过程使用 FP16 精度表示 w(t),同时保存一份 FP32 精度的 w(t) 副本用于参数更新,即下图左半部分。
3)精度累加
精度累加:利用 FP16 进行矩阵相乘,利用 FP32 来进行加法计算。可有效减少计算过程中的舍入误差,尽量减缓精度损失的问题。
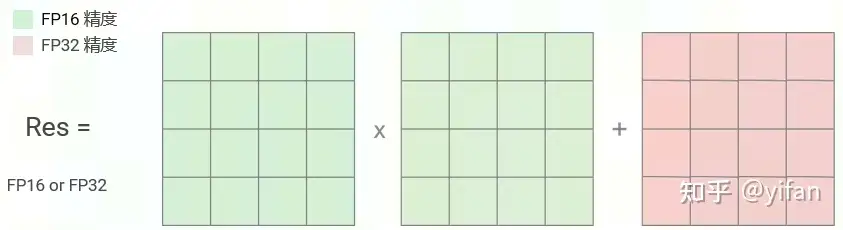
结论:原生TensorFlow2和Cambricon TensorFlow2都支持loss scale和参数备份,都不支持精度累加。
热门帖子
精华帖子





 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读