打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
我使用magicmind_runtime 进行离线模型推理,出现了CN_INVOKE_ERROR_EXECUTED_TIMEOUT问题?请问是驱动问题吗?还是我的代码有问题,请求帮助,谢谢。
代码比较简单,主体逻辑是加载一个restnet50的模型,模型从cnstream代码示例中下载,然后在板卡上运行,没有进行前后处理。
(1)代码如下:
int main(int argc, char *argv[])
{
std::string model_name = "/data/model/resnet50_v0.13.0_4b_rgb_uint8.magicmind";
std::vector<magicmind::IRTTensor *> input_tensors_;
std::vector<magicmind::IRTTensor *> output_tensors_;
std::vector<void *> input_host_ptrs_;
std::vector<void *> output_host_ptrs_;
cnrtSetDevice(0);
magicmind::IModel *model = magicmind::CreateIModel();
model->DeserializeFromFile(model_name.c_str());
{
///////////////////Print info below//////////////////////
size_t size = 0;
model->GetSerializedModelSize(&size);
std::cout << "Create IModel done." << std::endl;
std::cout << "Name: " << model_name << " Size: " << size << std::endl;
std::cout << "Input num: " << model->GetInputNum() << std::endl;
std::cout << "Input info:[ " << std::endl;
auto names = model->GetInputNames();
// CHECK_EQ(names.size(), in_dims_.size());
auto dims = model->GetInputDimensions();
auto types = model->GetInputDataTypes();
for (uint32_t i = 0; i < names.size(); ++i)
{
std::cout << names[i] << ": " << dims[i] << ", " << magicmind::TypeEnumToString(types[i]) << std::endl;
}
std::cout << "]" << std::endl;
std::cout << "Output info:[ " << std::endl;
names = model->GetOutputNames();
dims = model->GetOutputDimensions();
types = model->GetOutputDataTypes();
for (uint32_t i = 0; i < names.size(); ++i)
{
std::cout << names[i] << ": " << dims[i] << ", " << magicmind::TypeEnumToString(types[i]) << std::endl;
}
std::cout << "]" << std::endl;
////////////////////////////////////////////////////////
}
magicmind::IEngine *engine = model->CreateIEngine();
magicmind::IContext *context_ = engine->CreateIContext();
context_->CreateInputTensors(&input_tensors_);
context_->CreateOutputTensors(&output_tensors_);
auto input_dim_vec = model->GetInputDimension(0).GetDims();
if (input_dim_vec[0] == -1)
{
input_dim_vec[0] = 4;
}
magicmind::Dims input_dims = magicmind::Dims(input_dim_vec);
for (uint32_t i = 0; i < input_tensors_.size(); ++i)
{
input_tensors_[i]->SetDimensions(input_dims);
auto input_size = input_tensors_[i]->GetSize();
std::cout << "input_tensors_[i]->GetSize():" << input_size << std::endl;
void *input_ptr = nullptr;
cnrtHostMalloc(&input_ptr, input_size);
input_host_ptrs_.push_back(input_ptr);
// Some network has param as input, Host address will speed them up.
if ((input_tensors_[i]->GetMemoryLocation() == magicmind::TensorLocation::kMLU) ||
(input_tensors_[i]->GetMemoryLocation() == magicmind::TensorLocation::kRemoteMLU))
{
input_tensors_[i]->SetData(MallocMLUAddr(input_size));
Memcpy(input_tensors_[i]->GetMutableData(), input_ptr, input_size, true);
std::cout << "copy data host2device size=" << input_size << std::endl;
}
else
{
input_tensors_[i]->SetData(input_ptr);
}
}
magicmind::Status isOk = context_->InferOutputShape(input_tensors_, output_tensors_);
if (magicmind::Status::OK() == isOk)
{
for (uint32_t i = 0; i < model->GetOutputNum(); ++i)
{
void *out_ptr = nullptr;
auto output_size = output_tensors_[i]->GetSize();
cnrtHostMalloc(&out_ptr, output_size);
std::cout << "output_tensors_[i]->GetSize():" << output_size << std::endl;
magicmind::Status isOk = output_tensors_[i]->SetData(out_ptr);
if (isOk != magicmind::Status::OK())
{
std::cout << "SetData message=" << isOk.error_message() << std::endl;
}
output_host_ptrs_.push_back(out_ptr);
}
}
cnrtQueue_t queue_ = nullptr;
cnrtQueueCreate(&queue_);
isOk = context_->Enqueue(input_tensors_, output_tensors_, queue_);
if (isOk != magicmind::Status::OK())
{
std::cout << "Enqueue message=" << isOk.error_message() << std::endl;
}
cnrtQueueSync(queue_);
#if 0
for (uint32_t i = 0; i < output_tensors_.size(); ++i)
{
auto size = output_tensors_[i]->GetSize();
// fill in input data
Memcpy(output_host_ptrs_[i], output_tensors_[i]->GetMutableData(), size, false);
}
#endif
getchar();
return 0;
}(2)运行结果如下:
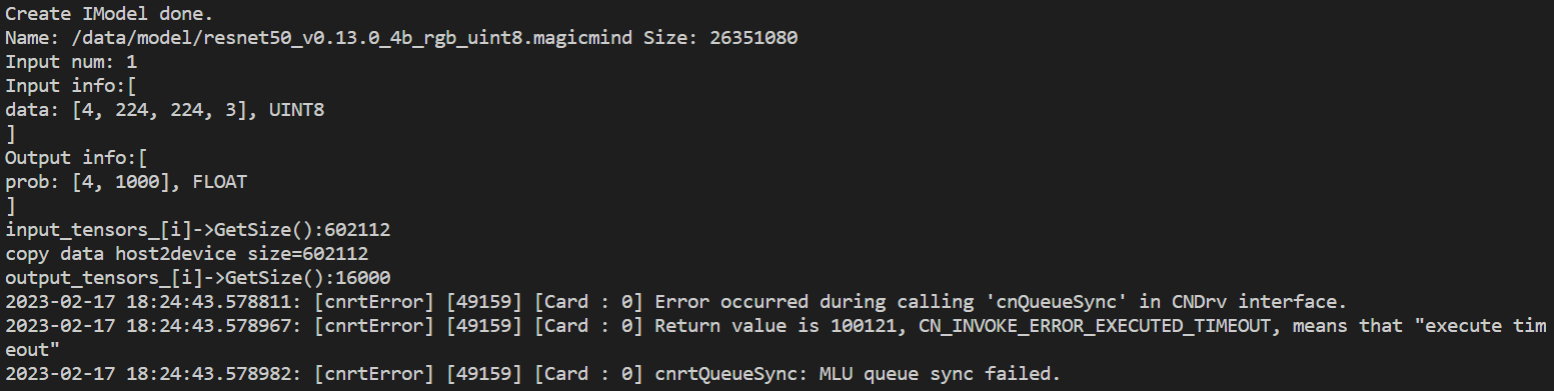
(3)驱动和软件信息如下:
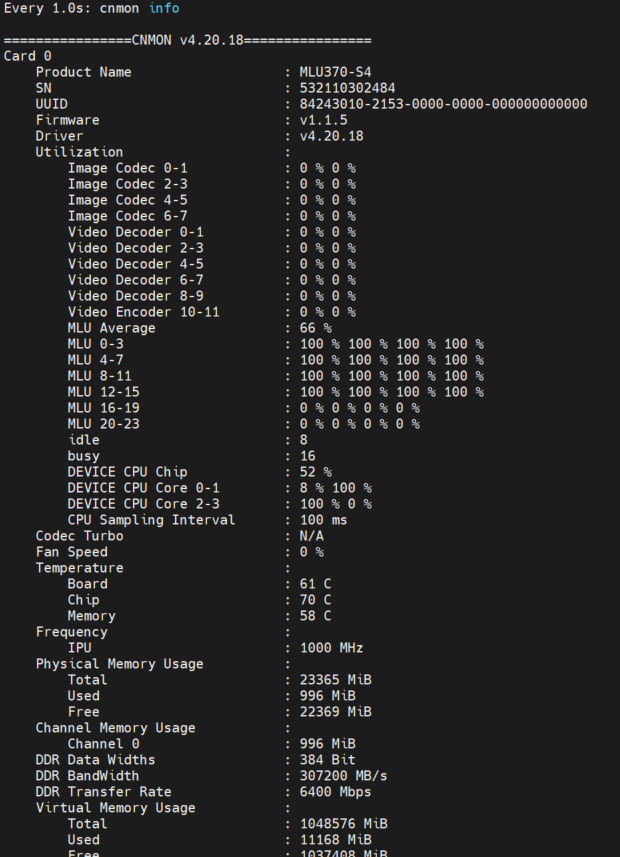
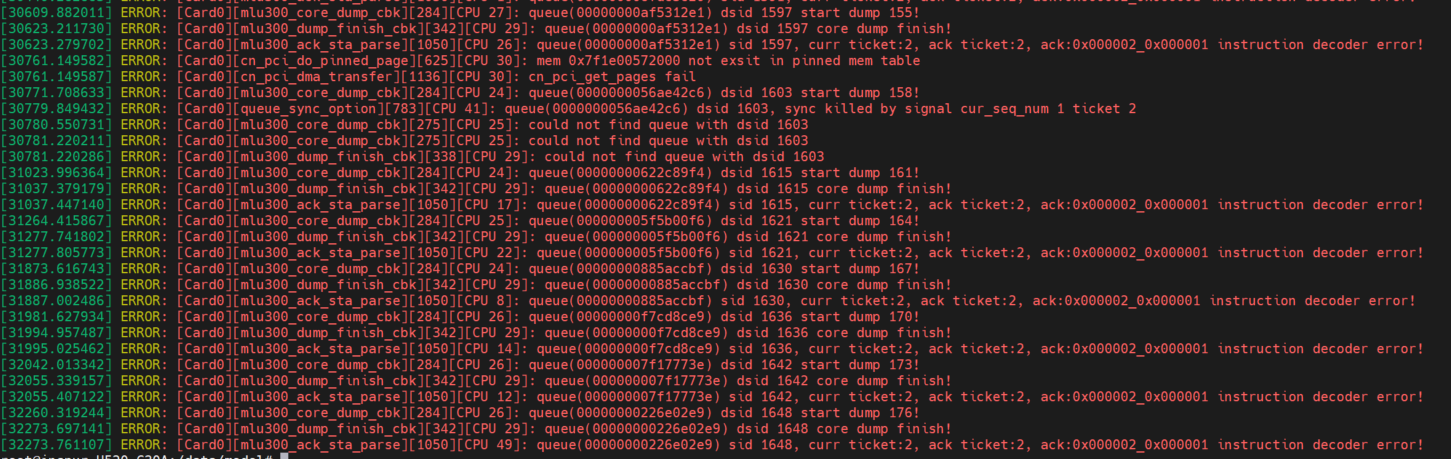
(4)模型和代码见附件,其去掉后缀.txt
![]() resnet50_v0.13.0_4b_rgb_uint8.magicmind.txt
resnet50_v0.13.0_4b_rgb_uint8.magicmind.txt
![]() core_1676658283_pid_49159_mluid_0_queue_670.cndump.txt
core_1676658283_pid_49159_mluid_0_queue_670.cndump.txt
热门帖子
精华帖子





 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读