打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
承接上面的模型生成,这里在此基础上介绍模型部署,即下图红框部分表示 MagicMind 模型运行期。
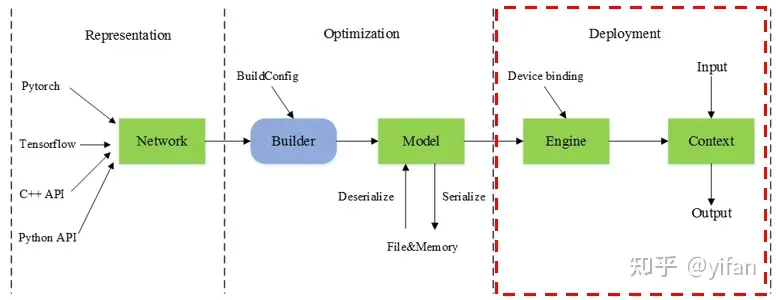
模型部署最基础的场景是单模型单卡单实例。但是在真实的业务场景中,用户往往会有多模型、多线程、多卡部署业务等需求。下面我们介绍三种典型的场景。
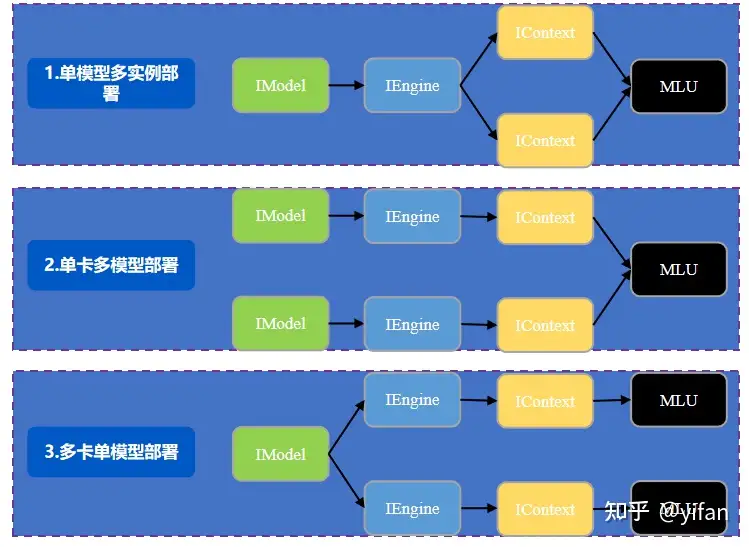
单模型多实例部署:单模型多实例部署是将单个模型部署到单设备上,一般配合主机端起多个线程,并发地处理不同的输入实例,不同的实例共享该设备上的指令和模型数据(权值),MagicMind 提供了这种能力,用户可以用多个 IContext 来实现在同一设备上并发地执行不同实例。
单卡多模型部署:单卡多模型部署是在同一 MLU 设备上同时部署多个模型。在 MagicMind 上,用户可以通过创建多个模型对象来完成多模型部署。比如我们想要在同一 MLU 设备上串行部署 VGG16 和Resnet50 两个模型,我们就需要创建2个模型对象,再分别创建不同的引擎实例,来将不同的模型部署到同一设备上。
多卡单模型部署:多卡单模型部署是将单个模型部署到同一台主机的多个 MLU 设备上,以实现数据并行。用户可以用同一个模型创建不同的引擎实例来将同一模型部署到多个设备上,每个引擎所生成的 IContext 也应用在对应的设备上。不可以用同一个引擎创建不同的 IContext 实例部署到不同的设备上。多个引擎共享主机端指令、模型数据,主机内存占用不会随着引擎数增多而明显增⻓。
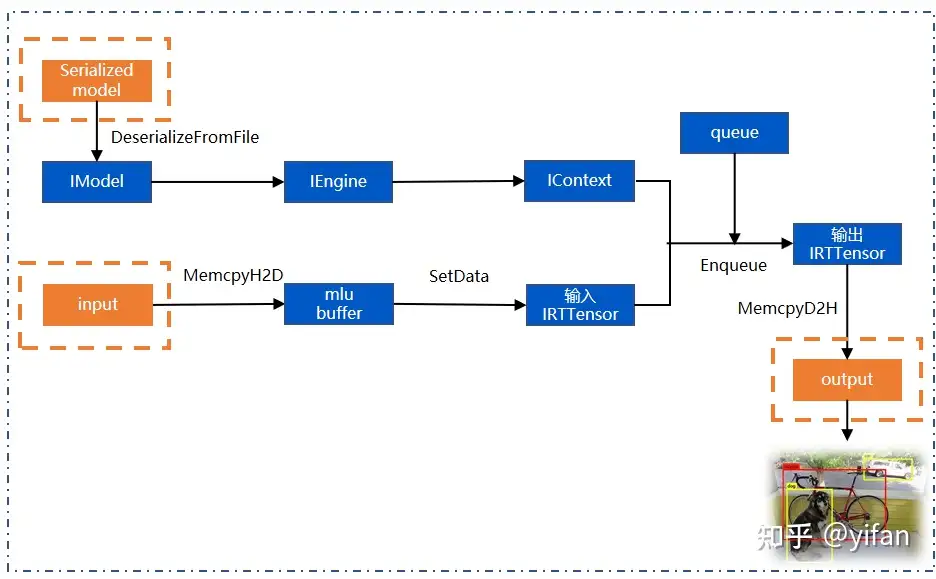
其中:
IModel 是用来保存序列化结构内容的纯 Host 变量,在加载完权值后可以被释放。
通过IModel对象实例化一个 IEngine,并将指令和权值部署到指定的设备上。
IContext是实际运行的交互类,IContext 中保存有运行过程中的状态。
创建IModel:MagicMind 需要先创建一个空的 Model,将模型文件通过反序列化接口反序列化到 IModel 中,DeserializeFromFile 接口会从文件系统加载模型,将指令、权值、图结构等信息加载到主机内存,生成模型对象。
创建IEngine:通过 IModel 实例化一个推理引擎 Iengine,将指令和权值部署到指定的设备上,默认0号设备。
创建IContext:再通过 engine 创建运行上下文 Icontext,完成引擎创建和执行上下文创建两项准备工作之后,就可以准备输入数据去执行推理了。
创建输入输出输结构 IRTTensor。
拷贝数据到 mlu buffer:将input输入通过Memcpy接口拷贝到 mlu buffer 上,并通过 SetData 接口将 mlu buffer 设置到 IRTTensor 中。
创建队列:然后我们就可以通过 cnrtCreateQueue 创建任务队列了,队列的创建不依赖上面的这些数据结构,我们也可以在 Imodel 创建之前就把队列创建好。
执行推理:最后通过 context 的 Enqueue 接口执行推理,计算结果保存在输出 IRTTensor 中,然后我们可以通过 Memcpy 接口将接口拷出到 cpu buffer 上做后处理。
下图为检测模型的推理流程:
展示了反序列化,创建 engine、context、queue 以及任务 enqueue 执行的 c++和python 接口,还有多卡部署的时候会涉及的关于 Device 的设置方法。
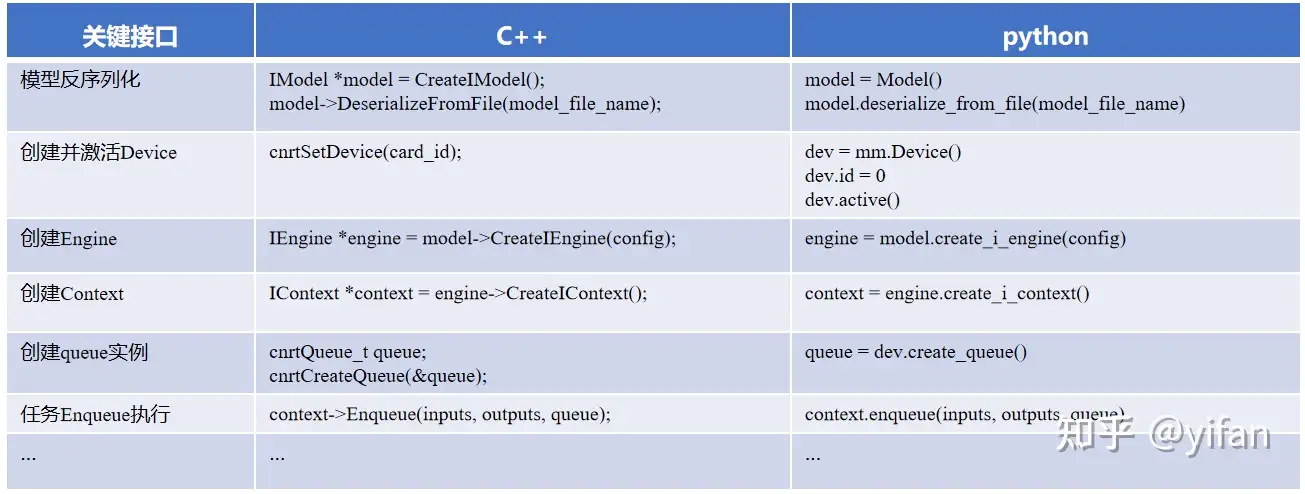
单卡单实例模型部署
import magicmind.python.runtime as mmimport numpy# 反序列化模型model = mm.Model()model.deserialize_from_file(graph_path)# 设置运行的devicedev = mm.Device()dev.id = 0assert dev.active().ok()# 创建engine,context,queueengine = model.create_i_engine()context = engine.create_i_context()queue = dev.create_queue()# 准备输入输出tensorinputs = context.create_inputs()input_dims = model.get_input_dimensions()for i in range(len(inputs)): inputs[i].from_numpy(numpy.random.rand(*tuple(input_dims[i].GetDims())))outputs = context.create_outputs(inputs)# 执行推理assert context.enqueue(inputs, outputs, queue).ok()assert queue.sync().ok()
1)mm_run 定义
是一个集 MagicMind 多个高级特性于一身的命令行工具,是主要的 End2End 性能测试工具。mm_run 随 MagicMind 发布,安装后位于系统 /usr/local/neuware/bin/mm_run 路径
mm_run 是一个集 MagicMind 多个高级特性于一身的命令行工具,对标 TensorRT 的 trtexec 工具,是主要的 End2End 性能测试工具。其主要功能是做性能评测。
2)mm_run 意义
Q1:为什么需要模型部署工具(mm_run)
A1:
1. 模型复杂度高
2. 性能测试难度大(延迟、吞吐量)
Q2:mm_run解决了哪些问题?
A2:
1. 模型精度验证
2. 快速测试模型吞吐量和延迟
3. 性能分析
#测试命令及参数解释mm_run \--magicmind_model model \ --input_dims 1,3,480,640 \--threads 6 \--disable_data_copy 1
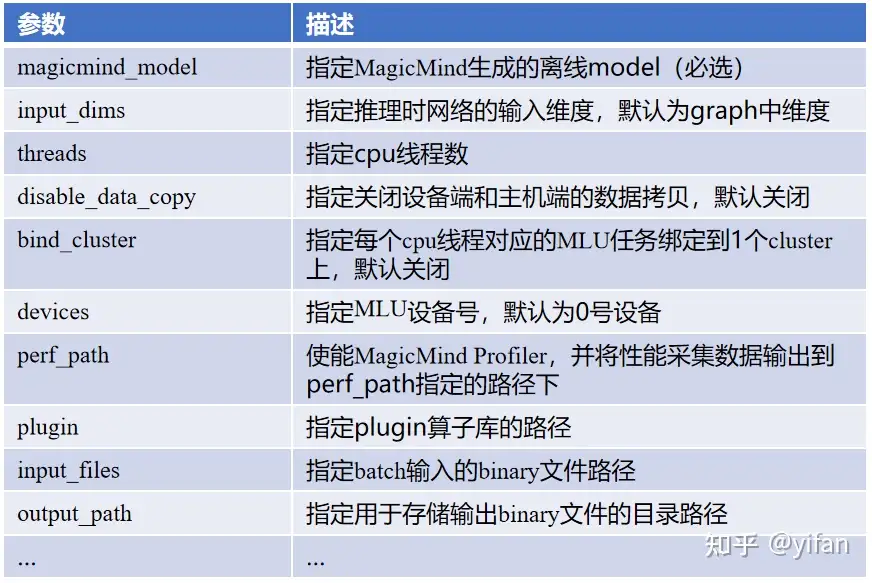
mm_run 工具只有 magicmind_model 参数是必选的,其他所有参数都是根据需要使用,生成的模型不同,用到的参数也是不同的。
关于一些高级别的参数,如 bind_cluster,perf_path 参数可查文档。具体运行情况可以看以下实验的第2个部分。
运行
# 测试 parser 的python predict_on_resnet50.py --path_mm_model ../cn_mm2/resnet50_parser.mm# 测试 mm_build 的python predict_on_resnet50.py --path_mm_model ../cn_mm2/resnet50_from_mm_build.mm
根据【CN_MM2】parser和mm_build的模型结果是一致的:
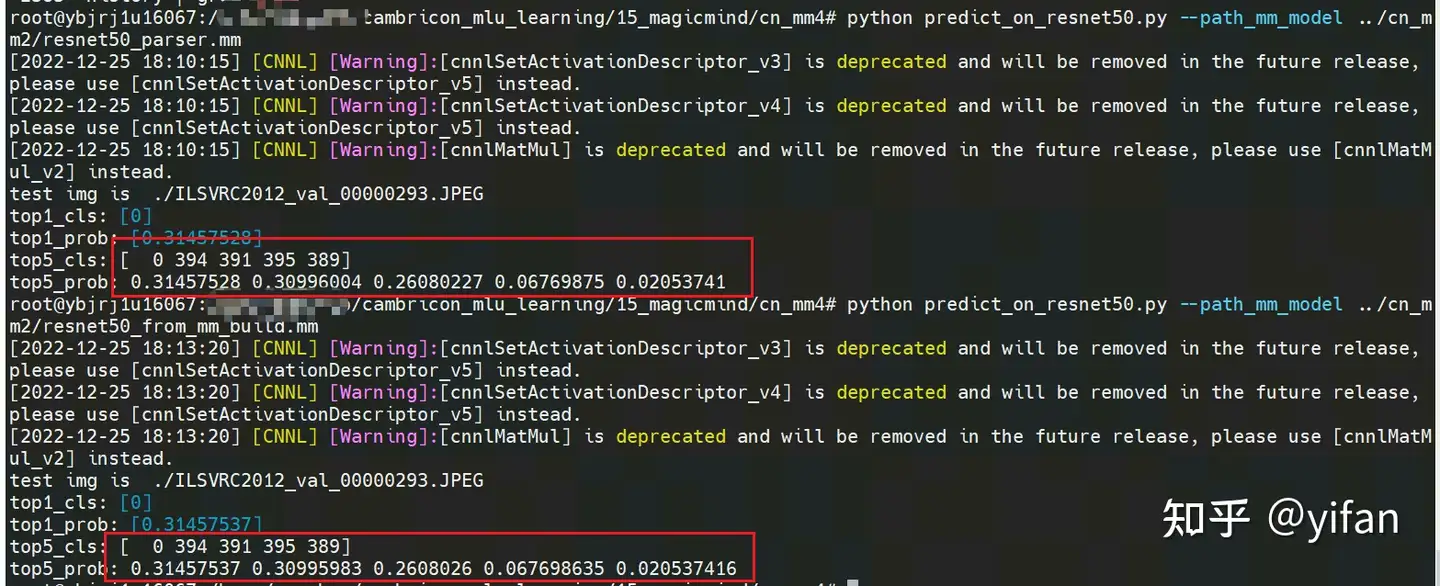
其中 predict_on_resnet50.py代码:
import jsonimport argparseimport numpy as npimport torchimport magicmind.python.runtime as mmimport magicmind.python.runtime.parser as mm_parserfrom torchvision import transformsfrom PIL import Imagedef parse_option():
parser = argparse.ArgumentParser('resnet50 ', add_help=False)
parser.add_argument('--path_mm_model', type=str, var="FILE", help='path to model',
default='../cn_mm2/resnet50_from_mm_build.mm')
args = parser.parse_args()
return argsdef img_preprocess():
transform = transforms.Compose([
transforms.Resize(size=292, interpolation=Image.BICUBIC),
transforms.CenterCrop(size=(256, 256)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225))
])
image_list = ['./ILSVRC2012_val_00000293.JPEG']
return transform, image_listdef main(args):
transform, image_list=img_preprocess()
# 创建 Device
dev = mm.Device()
dev.id = 0 #设置 Device Id
assert dev.active().ok()
# 加载 MagicMind resnet50 模型
model = mm.Model()
model.deserialize_from_file(args.path_mm_model)
# 创建 MagicMind engine, context
engine = model.create_i_engine()
context = engine.create_i_context()
# 根据 Device 信息创建 queue 实例
queue = dev.create_queue()
# 准备 MagicMind 输入输出 Tensor 节点
inputs = context.create_inputs()
for i in range(len(image_list)):
path = image_list[i]
with open(path, 'rb') as f:
img = Image.open(f)
img = img.convert('RGB')
image = transform(img).unsqueeze(0)
outputs = []
images = np.float32(image)
inputs[0].from_numpy(images)
# 绑定context
assert context.enqueue(inputs, outputs, queue).ok()
# 执行推理
assert queue.sync().ok()
pred = torch.from_numpy(np.array(outputs[0].asnumpy()))
## 计算概率,以及输出top1、top5
pred = pred.squeeze(0)
pred = torch.softmax(pred, dim=0)
pred = pred.numpy()
top_5 = pred.argsort()[-5:][::-1]
top_1 = pred.argsort()[-1:][::-1]
print('test img is ', path)
print('top1_cls:', top_1)
print('top1_prob:', pred[top_1])
print('top5_cls:', top_5)
print('top5_prob:', pred[top_5[0]], pred[top_5[1]],
pred[top_5[2]], pred[top_5[3]], pred[top_5[4]])if __name__ == '__main__':
args = parse_option()
main(args)mm_run --magicmind_model ../cn_mm2/resnet50_parser.mm --iterations 1 --duration 0 --warmup 0 --input_dims 1,3,244,244
结果:
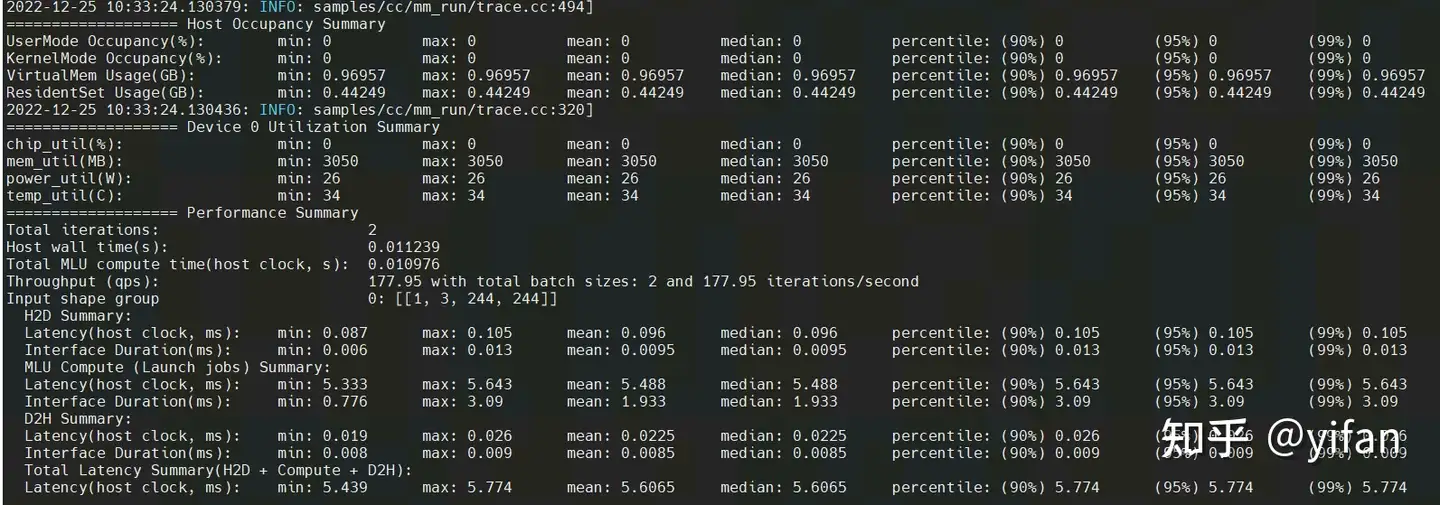
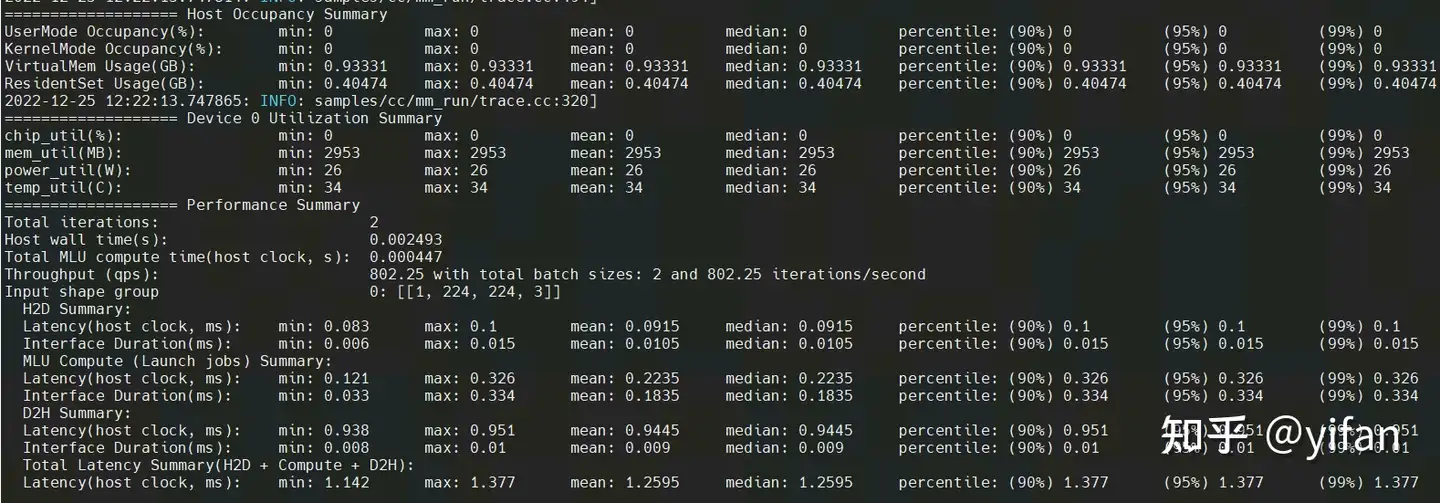
这是 mm_run 跑的一个模型的结果,可以看到输出了吞吐,延迟,以及 mlu 板卡利用率等等。
mm_run --magicmind_model ../cn_mm2/resnet50_parser.mm --iterations 1 --duration 0 --warmup 0 --input_dims 64,3,244,244
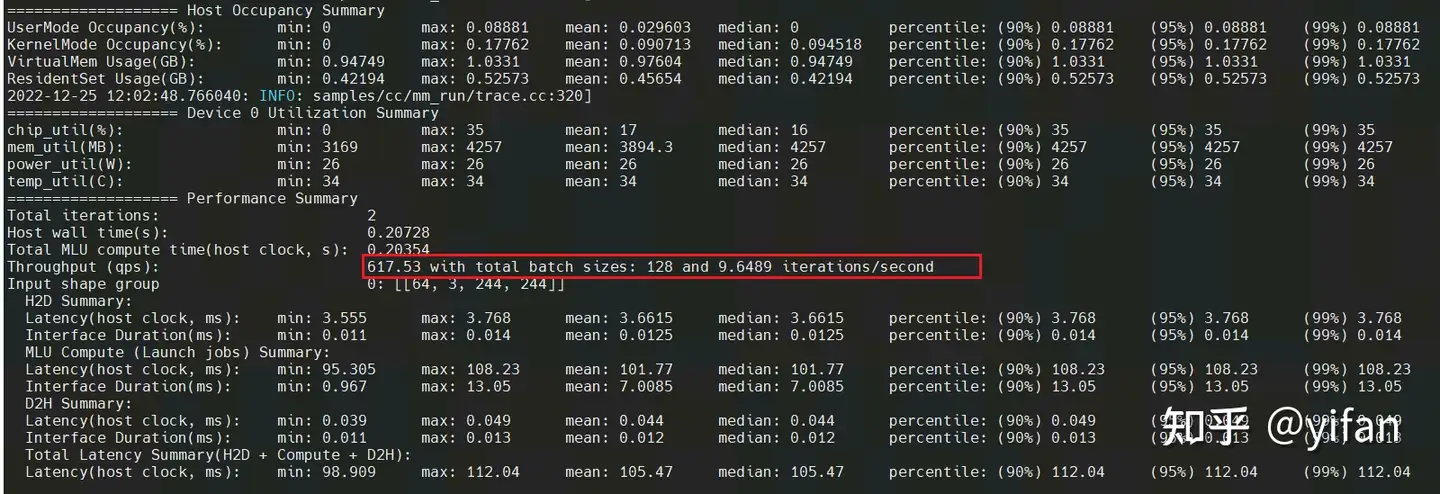
可以发现推理速度增加了。
测试【CN_MM3】使用API搭建的模型
运行 : bash graph_run.sh。graph_run.sh命令如下:
mm_run --magicmind_model ../cn_mm3/sample_convrelu/graph --iterations 1 --duration 0 --warmup 0 --input_dims 1,224,224,3
其中 ../cn_mm3/sample_convrelu/graph 是上一节中的模型。
运行结果如下:
说明:代码见 代码库的:cambricon_mlu_learning/15_magicmind/cn_mm4
热门帖子
精华帖子





 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读