打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
知乎链接:【CN-MM05】MagicMind 特性之混合精度
https://zhuanlan.zhihu.com/p/611605965
若是初学者,建议先看前面的,尤其是其中的的后面4个关于MagicMind的模块。
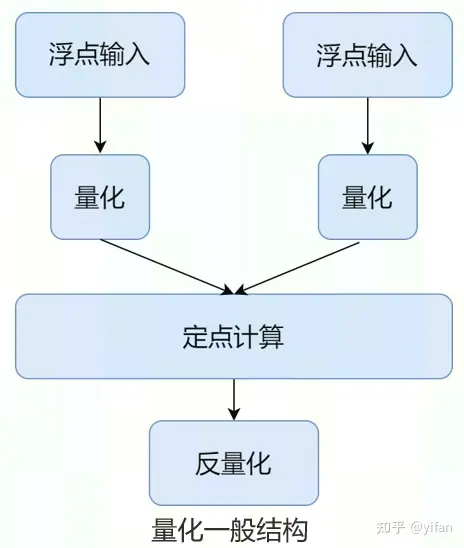
量化的优点:
模型大小可以压缩,32Bit 数据量化为 8/16Bit 可以减少存储空间
定点运算相比浮点运算指令,单位时间内能处理更多的数据;而且大部分的硬件对于定点运算都有特定的优化,所以在运行速度上会有较大的提升。
量化粒度主要分为按层量化和按通道量化;
按层量化,通常也称为per-tensor或per- 量化,整个tensor 会共用一个Range(数据范围);
按通道量化,也称为per-axis/per-channel, 每个kernel会单独统计一个Range(数据范围)。
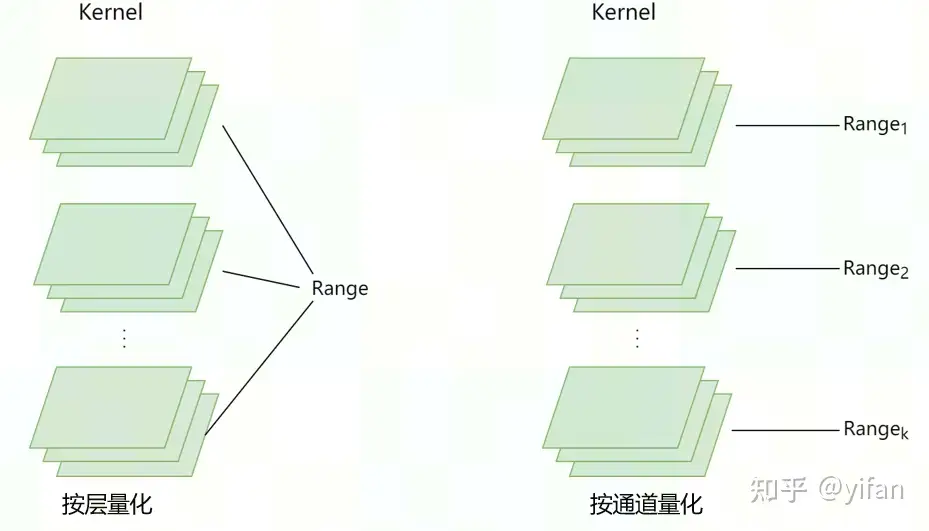
注意:对于 per-channel 量化来说,很多同学第一感觉:给 feature 和 kernel 的每一个 channel 都单独计算一个 scale 和 zeropoint。但是这个计算代价太高。因此就变成了上图右侧的形式:这其中的差别就在于,feature 还是整个 tensor 共用一个 scale 和 zeropoint,但每个 kernel 会单独统计一个 scale 和 zeropoint(注意是每个 kernel,而不是 kernel 的每个 channel)。

量化可以分为对称量化和非对称量化,主要依据零点偏置offset是否为0来判断,即 min 和 max 是否关于0对称。
对称量化公式:我们目标是将浮点数从(min,max)变换到定点数(n, p),其中 。所以需要除以 s 进行对应比例的缩放,再对结果使用 round 取整,最后通过 clip 函数将其限制在(n,p)的范围内,从而达到量化的目的; 在反量化中,也即是这里的x_DQ,DQ表示DeQuant,即反量化。可以通过乘以缩放系数 s 求得。
非对称量化公式:目标不变,但s对应变成 ,前面也提到对称量化和非对称量化主要区别在于偏置值 z 是否为0,所以非对称量化公式相比对称量化从公式上看多了偏移 z;关于z的计算,有2种计算方式:一种如上面给出的公式所示,根据左边数据的 n 和对应 min/s 来求得; 另一种也可以根据右边边界p和对应max/s 来求得。 接下来的量化和反量化过程中注意加减刚求得的z,其他步骤和对称量化类似。
目前工业界主要应用三类量化技术:
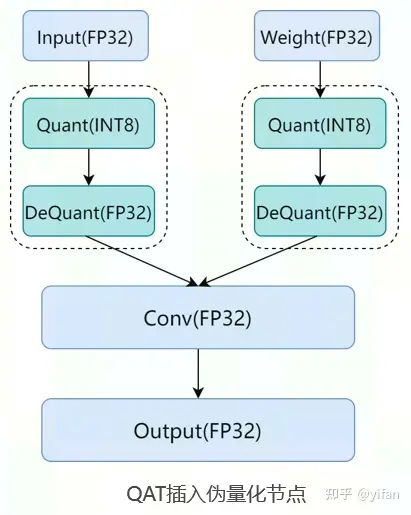
量化感知训练QAT,英文全称Quantization-Aware Training, 在训练好的模型基础上,进行量化感知的 finetune,通过插入量化和反量化节点(如上图所示),引入量化误差损失,从而在训练过程中提高模型对量化的适应能力,提高最终的量化模型精度,相较后面将要表述的离线量化PTQ而言,QAT精度更高,缺点是需要对模型进行一定的finetune。
动态离线量化dPTQ,英文全称Post-Training Quantization Dynamic,仅将模型中待量化节点权值映射成 INT8/16 类型,而activation在前向推理过程中被动态量化。
静态离线量化sPTQ,英文全称Post-Training Quantization Static,将已经训练好的浮点模型,通过校准数据集统计待量化节点的输入和权值范围,将模型转换成低精度/比特模型,优点是不需要finetune,缺点是量化后的模型可能掉点(即预测正确率下降)。严重情况下会导致量化模型不可用;
主要:本文后续提到的PTQ特指这里的sPTQ。
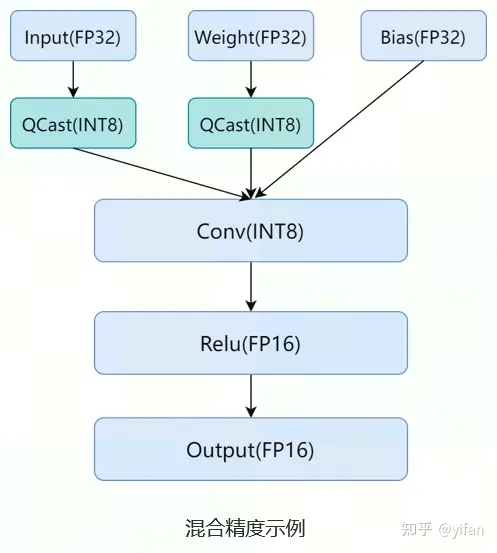
MagicMind 支持网络中的不同算⼦使⽤不同的输⼊精度以及输出数据类型,我们称之为混合精度。如图Conv的计算使用INT8进行计算,Relu使用FP16进行计算;
混合精度优势:低精度模型有着更小的内存与带宽占用和更快的推理速度等优点,高精度模型可以保证模型精度,用户可以根据实际业务需要,配置网络按什么样精度运行,从而做到性能和精度的权衡
MagicMind混合精度支持以下功能:
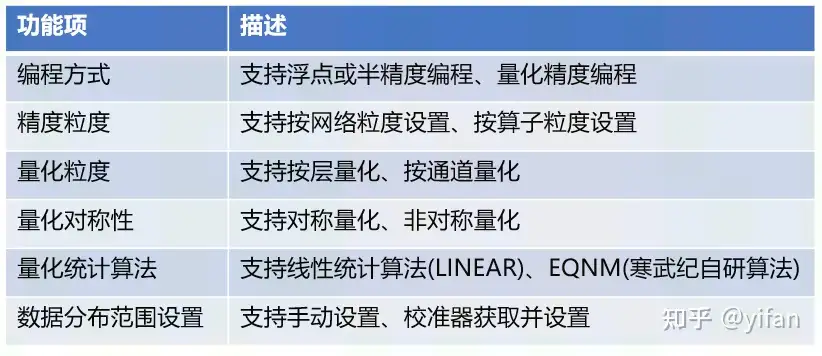
MagicMind 支持浮点/半精度编程以及量化精度编程两种⽅式:
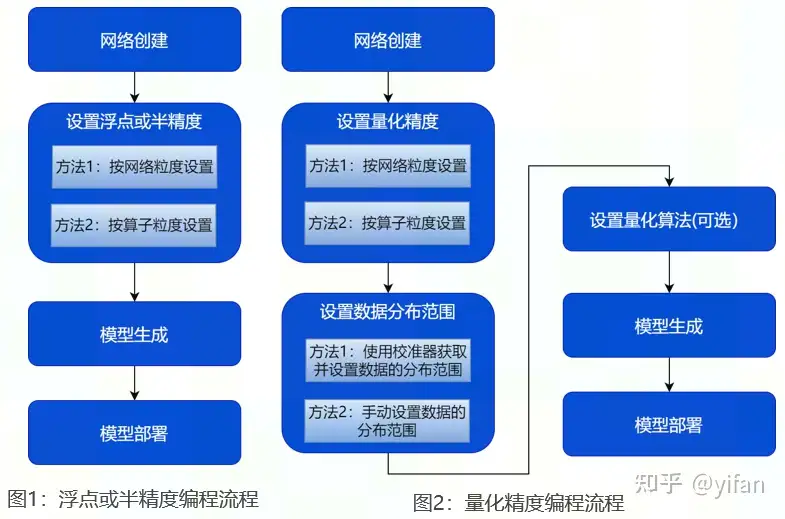
当待构建的模型为浮点/半精度模型时,无需提供 tensor 的数据分布范围,直接构建即可。构建流程如右图1所示,网络创建-设置浮点或半精度-模型生成-模型部署;
当待构建的模型为量化模型时,需通过量化校准自动统计并设置 tensor 的数据分布范围或手动设置待量化 tensor 的数据分布范围。构建流程如右图2所示,相较于浮点或半精度编程流程,量化精度构建流程多了设置数据分布范围和量化算法设置操作
MagicMind提供了两套方式设置算子输入精度和输出数据类型,分别是按网络粒度设置和按算子粒度设置;
1)按网络粒度设置
设置整个网络中所有算子所使用的输入精度和输出数据类型,用于快速完成整网算子的精度设置,推荐使用这种精度配置方式。设置方法可通过配置 BuilderConfig 的”precision_mode”字段设置整个网络的精度,示例如下
config->ParseFromString(R"({"precision_config" : {"precision_mode": "qint8_mixed_float16"}})")2) 按算子粒度设置
主要用于精细设置每⼀个算子所使用的输入精度和输出数据类型。这种方式相对比较灵活,但使用起来相对复杂。设置输⼊精度的接口为 INode::SetPrecision(size_t index, DataType precision),设置输出数据类型的接口为 INode::SetOutputType(size_t index, DataType precision),下面C++示例中,将conv输入和权值精度设置为QINT8,conv bias 精度设置为FP16, conv 输出数据类型设置为FP16, pool 输出数据类型设置为FP16。
ITensor *input = network->AddIInput(DataType::QINT8, Dims({-1, -1, -1, 3}));IConvNode *conv = network->AddIConvNode(input, filter, bias);IMaxPool2DNode *pool = network->AddIMaxPool2DNode(conv->GetOutput(0), false);network->MarkOutput(pool->GetOutput(0));conv->SetPrecision(0, DataType::QINT8); // 设置 conv 输⼊的精度为 QINT8conv->SetPrecision(1, DataType::QINT8); // 设置 conv 滤波张量的精度为 QINT8conv->SetPrecision(2, DataType::FLOAT16); //设置 conv bias 的精度为 FLOAT16conv->SetOutputType(0, DataType::FLOAT16); //设置 conv 输出的数据类型为 FLOAT16pool->SetOutputType(0, DataType::FLOAT16); //设置 pool 输出的数据类型为 FLOAT16需要注意的是当同时设置整网粒度和算子粒度,且二者不同时,算子粒度具有更高优先级。按网络粒度设置完精度后,如果遇到精度不达标的情况下,可以对部分算子调整算子粒度。
MagicMind 支持多种混合精度模式:

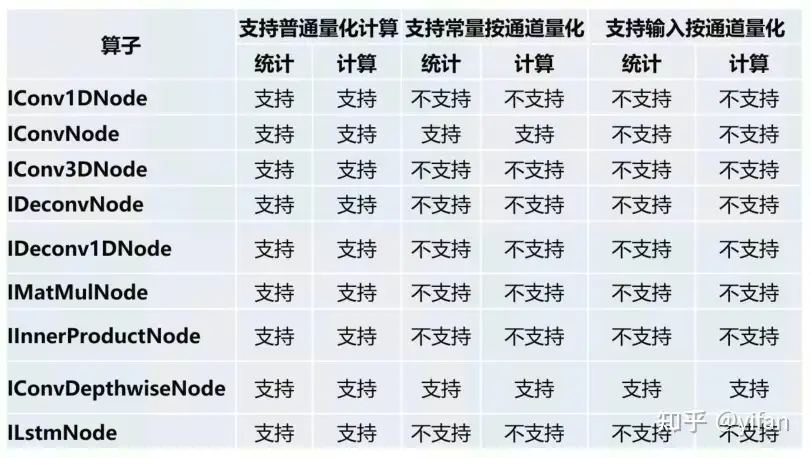
MagicMind量化相关算子的支持情况
量化部分的使用主要涉及数据分布范围的设置,MagicMind 提供两种方式,分别是使用校准器获取并设置以及手动设置,下面先讲使用校准器获取这一种方式,也是最常见的一种方式。
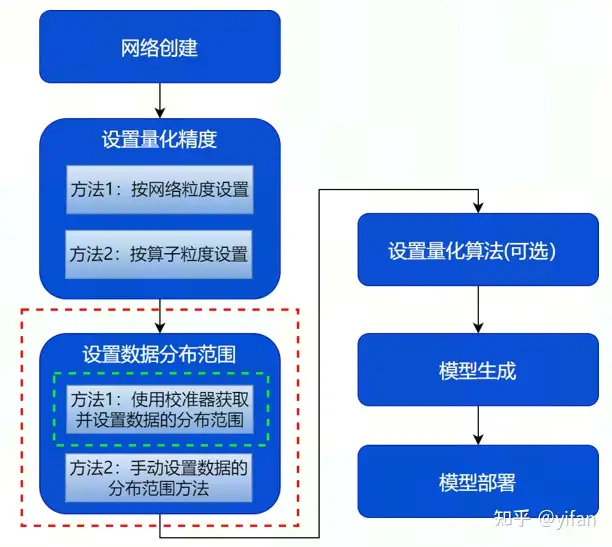
为什么需要提供数据的分布范围呢?前面讲量化基础的时候,我们知道量化是将数据从浮点数转成定点数,这里转换的时候需要知道待量化数据的一个分布范围(即min,max)
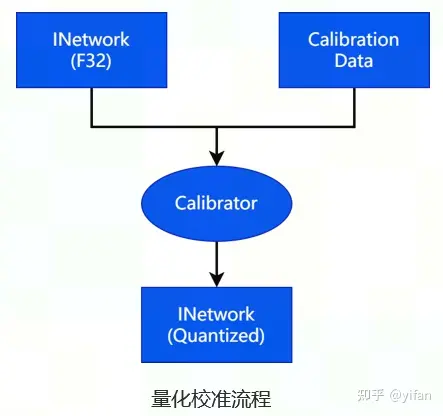
对于支持量化输入的算子,除了设置输入精度之外,还需要提供数据的分布范围。MagicMind 提供了量化校准器 (Calibrator),它支持 post-training 量化功能,能够基于浮点模型和样本数据计算并设置数据的分布范围,适用于只能提供浮点网络和样本数据的使用场景,量化校准的接口为 ICalirator::Calibrate()。
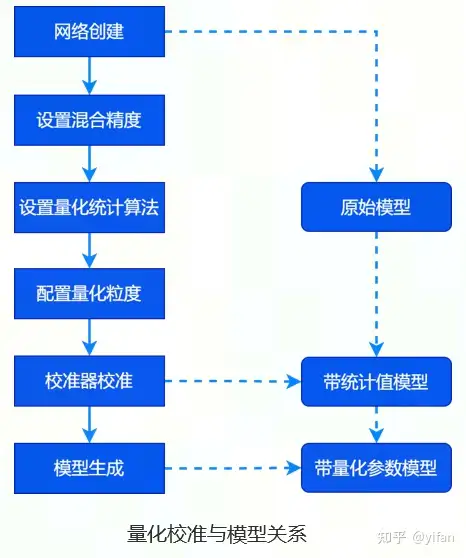
量化校准与模型关系,使用校准器获取并设置数据的分布范围时,从原始模型到带量化参数的模型会经过校准器校准和模型生成两个阶段
校准器校准得到的是带统计值的模型
模型生成的是带量化参数的模型
class CalibDataInterface(cc.CalibDataInterface): def __init__(self): cc.CalibDataInterface.__init__(self) def get_shape(self) -> basic_types.Dims: raise NotImplementedError def next(self) -> basic_types.Status: raise NotImplementedError def reset(self) -> basic_types.Status: raise NotImplementedError def get_sample(self) -> np.ndarray: raise NotImplementedError def get_data_type(self) -> enums.DataType: raise NotImplementedError
1)校准器使用
使用校准器之前,需要用户自行定义校准数据集的加载和处理方式,就是用户需要实现一个继承于 CalibDataInterface 虚基类的子类,并实现基类的所有虚函数,下面是CalibDataInterface 虚基类。其中,Init 函数主要是初始化该类的一些内建变量,get_shape 是返回数据的形状,Next是取校准数据集中的下一条样本数据,reset 是对样本计数进行重置, get_sample 是返回当前的样本数据, get_data_type 是返回当前的数据类型。
热门帖子
精华帖子





 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读