打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
知乎链接:https://zhuanlan.zhihu.com/p/611606630
若是初学者,建议先看前面的,尤其是其中的关于MagicMind的模块部分。
建议结合实测试和同步查看,这样更容易理解各步骤的意义。
1)为什么需要自定义算子?
MagicMind提供了丰富的算子库,能够满足绝大多数场景的使用需求。但出于以下原因,可能需要定制化算子的实现,从而满足特定需求:
某些运算逻辑没有对应算子,或无法组合基础 API 实现
通过算子融合追求更高的计算性能
2)流程图
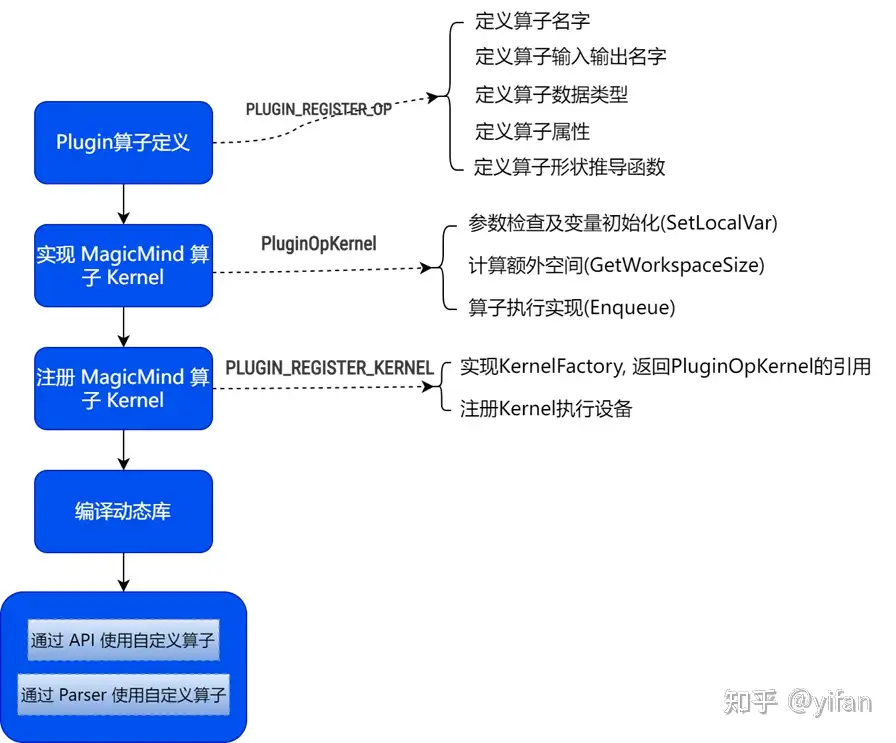
先看第一部分:
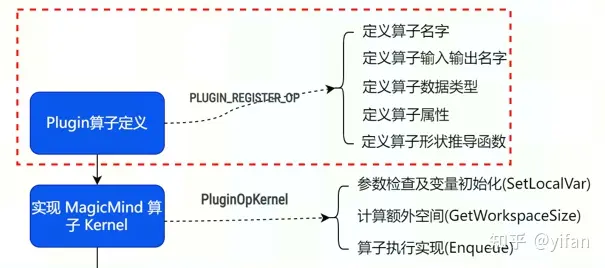
自定义算子定义就是根据算子的特性,将算子对应的输入、输出,输入和输出数据类型、形状推导函数、属性信息通过调用 IPluginDefBuilder相关接口注册到 Magicmind算子库中; PLUGIN_REGISTER_OP 宏是自定义算子注册的入口。
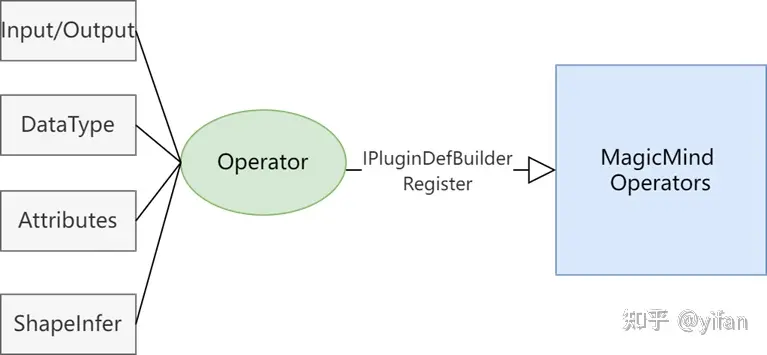
以 C++ API 为例, PluginAdd的注册示例
PLUGIN_REGISTER_OP("PluginAdd")
.Input("input1").TypeConstraint("T")
.Input("input2").TypeConstraint("T")
.Output("output").TypeConstraint("T")
.Param("T").Type("type")
.Default(DataType::FLOAT32)
.ShapeFn(DoShapeInfer);接下来我们介绍下注册算子名字,输入输出及输入输出数据类型,形状推导的语法
| 注册项 | 语法 | 说明 |
| 注册算子名字 | PLUGIN_REGISTER_OP(op_name) | op_name为该自定义算子名,可以根据算子功能来取名 |
| 注册算子的输入和输出 | Input(conststd::string &input)Output(conststd::string &output) | 如果有多个输入和输出,需要多次调用该接口 |
| 设置算子输入和输出的数据类型 | TypeConstraint(DataType constraint) | 如果设置多种数据类型,可以向 TypeConstraint传入一个字符串声明一个 Type param,然后再调用 Param接口对这个 Type Param进行具体描述,例如 TypeConstraint("T")....Param("T")… |
| 注册形状推导函数 | ShapeFn(ShapeInferFun) | 需实现 ShapeInferFun,且自定义算子的形状推导函数只能注册一次 |
形状推导是根据输入形状推导输出形状,是必须实现并注册的;形状推导接口的输入参数 IShapeInferResource 以键值对方式(name, value),存储了算子编译和运行期所需要的各种参数,包括输入输出形状、输入输出地址、算子参数等,用户可以通过 name 获取到所需要的参数;下面示例代码为 PluginAdd 的形状推导函数实现;该算子输出形状和输入形状一致,所以只需要获取输入形状并设置给输出形状即可。
Status DoShapeInfer(IShapeInferResource *context) {
Status ret;
std::vector<int64_t> input_shape;
// 获取输入'input1'的形状,获取成功返回Status::OK(),获取失败返回其它错误 ret = context->GetShape("input1", &input_shape);
if (ret != Status::OK()) {
return ret;
}
// 设置输入'input1'的形状,设置成功返回Status::OK(),设置失败返回其它错误 ret = context->SetShape("output", input_shape);
return ret;}除了上述介绍的注册接口,还有其他属性的注册接口,介绍如下
| 注册项 | 语法 | 说明 |
| 注册参数 | Param(conststd::string ¶m) | 算子的属性,如 Conv算子的 pad、stride、dialation等描述信息,有多个 parameter,需要多次调用该接口 |
| 声明参数的数据类型 | Type(conststd::string &type)TypeList(conststd::string &type) | 1. 声明对应 parameter的数据类型,数据类型支持设置的值为:bool/int/float/string/type/layout2.当参数为 “float” 时,对应的 Parameter 为 vector<float> 类型 |
| 设置参数最小值 | Minimum(int64_tvalue) | 当数据类型为 vector 时,表示 vector 允许的最小 size , 其值必须是非负数 |
| 设置参数默认值 | Default(VTypevalue) | 参数类型与对应 parameter 的数据类型应保持一致 |
| 设置参数的取值范围 | Allowed(VType value) | 声明对应 parameter 允许的值域 |
| 注册可变输入输出 | NumberConstraint(conststd::string &constraint) | 对可变的输入输出使用 NumberConstraint接口声明约束,约束被声明后需要作为自定义算子中的参数被进一步描述 |
复杂算子注册示例
PLUGIN_REGISTER_OP("PluginFusedMatMul") // 自定义算子名 .Input(“a”).TypeConstraint(“T”) // 注册输入 Input a,并对其进行属性设置 .Input(“b”).TypeConstraint(“T”) // 注册输入 Input b,并对其进行属性设置 .Input(“args”).TypeConstraint(“T”).NumberConstraint(“num_args”) // 注册输入 args,并对其进行属性设置 .Output(“product”).TypeConstraint(“T”) // 注册输出 product,并对其进行属性设置 .Param(“transpose_a”).Type(“bool”).Default(false) // 注册 transpose_a 属性,并对其进行属性设置 .Param(“transpose_b”).Type(“bool”).Default(false) // 注册 transpose_b 属性,并对其进行属性设置 // 注册自定义算子的 Param 范型描述 T,并对其进行属性设置 .Param("T").Type("type").Allowed({DataType::FLOAT16,DataType::FLOAT32})
.Param(“num_args”).Type(“int”).Minimum(0) // 注册 num_args 属性,并对其进行属性设置 .Param(“fused_ops”).TypeList(“string”).Default({“op”})// 注册 fused_ops属性,并对其进行属性设置 .Param(“epsilon”).Type(“float”).Default(0.0001f) // 注册 epsilon 属性,并对其进行属性设置 // 注册 leakyrelu_alpha 属性,并对其进行属性设置 .Param("leakyrelu_alpha").Type("float").Default(0.2f)
.ShapeFn([](IShapeInferResource* rsc)->Status { // 注册自定义算子的形状推导函数 std::vector<int64_t> input_shape;
rsc->GetShape("input1", &input_shape);
rsc->SetShape("output", input_shape);
return Status::OK();
});MagicMind算子Kernel的实现,这一步主要实现算子的执行行为
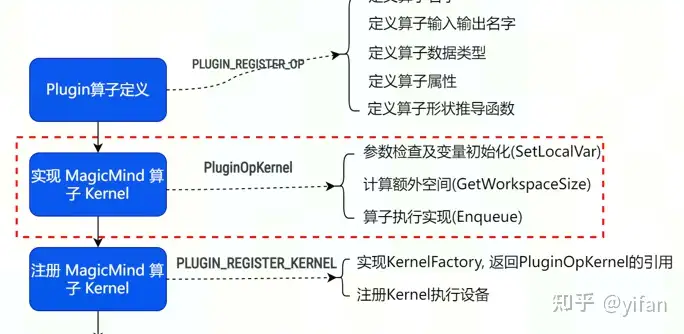
Kernel定义了算子的执行行为,会在运行期被调用。所有自定义算子的 Kernel 都派生自 IPluginKernel 基类,并要求实现 SetLocalVar、GetWorkspaceSize、Enqueue 接口。下面示例为派生自 IPluginKernel 的 PluginAddKernel 类。
class PluginAddKernel : public IPluginKernel {
public:
// 完成参数检查和用户自定义成员变量的初始化 Status SetLocalVar(INodeResource *context) override;
// 获取加法操作运行时所需要的额外内存(如果有的话) size_t GetWorkspaceSize(INodeResource *context) override;
// 执行加法运算 Status Enqueue(INodeResource *context) override;
~PluginAddKernel();
private:
uint32_t input_count;};SetLocalVar、GetWorkspaceSize、Enqueue 接口的作用说明如下:
| 接口 | 说明 |
| SetLocalVar | 完成 Kernel 参数的检查与派生类成员变量的初始化 |
| GetWorkspaceSize | 负责计算 Kernel 运行所需的额外内存大小 |
| Enqueue | 负责完成 Kernel 的执行,该接口会在运行期被调用,支持在 MLU 上计算,也支持在 CPU 上计算 |
SetLocalVar、GetWorkspaceSize、Enqueue 接口代码如下:
# SetLocalVarStatus PluginAddKernel::SetLocalVar(INodeResource *context) {
std::vector<int64_t> input_shape;
context->GetTensorShape("input1", &input_shape);
if (input_shape.size() < 1) {
return Status(magicmind::error:Code::INVALID_ARGUMENT, "FAILED"); }
input_count = GetInputCount(input_shape);
return Status::OK();}# GetWorkspaceSizesize_t PluginAddKernel::GetWorkspaceSize(INodeResource *context) {
size_t workspace_size = 0;
return workspace_size;}# EnqueueStatus PluginAddKernel::Enqueue(INodeResource *context) {
float *input1_addr = nullptr;
float *input2_addr = nullptr;
float *output_addr = nullptr;
context->GetTensorDataPtr("input1", &input1_addr);
context->GetTensorDataPtr("input2", &input2_addr);
context->GetTensorDataPtr("output", &output_addr);
for (int i = 0; i < input_count; i++) {
output_addr[i] = input1_addr[i] + input2_addr[i];
}
return Status::OK();}PluginAdd在MLU上运行,需要调用支持MLU运行的CNNL算子或BANGC实现,这里我们用Bangc实现了在MLU执行加法的VectorAdd接口, 在获取到对应输入输出的设备指针后,调用VectorAdd接口完成计算。
Status PluginAddKernel::Enqueue(INodeResource *context) {
float *input1_addr = nullptr;
float *input2_addr = nullptr;
float *output_addr = nullptr;
cnrtQueue_t queue;
context->GetTensorDataPtr("input1", static_cast<void **>(&input1_addr));
context->GetTensorDataPtr("input2", static_cast<void **>(&input2_addr));
context->GetTensorDataPtr("output", static_cast<void **>(&output_addr));
context->GetQueue(&queue); // 获取所需要的输入输出地址和Queue cnrtDim3_t dim{4,1,1};
cnrtFunctionType_t type = cnrtFuncTypeUnion1;
VectorAdd<<<dim, type, queue>>>(input1_addr, input2_addr, output_addr, input_count);
// 调用BangC 实现好的VectorAdd接口完成计算 return Status::OK();}// VectorAdd__mlu_global__ void VectorAdd(const float *input1, const float *input2,
float *output, const uint32_t count) {
__nram__ float src1_nram[BANG_NRAM_SIZE/8]; // 在nram上分配空间 __nram__ float src2_nram[BANG_NRAM_SIZE/8];
__nram__ float dst_nram[BANG_NRAM_SIZE/8];
uint32_t num_per_core = count / taskDim;
// 将ddr内存上的数据拷贝到nram上 __memcpy(src1_nram, input1 + taskId * num_per_core, num_per_core * sizeof(float), GDRAM2NRAM);
__memcpy(src2_nram, input2 + taskId * num_per_core, num_per_core * sizeof(float), GDRAM2NRAM);
__bang_add(dst_nram, src1_nram, src2_nram, num_per_core); // 在mlu上执行加法操作 // 将数据拷出到ddr内存上 __memcpy(output + taskId * num_per_core, dst_nram, num_per_core * sizeof(float), NRAM2GDRAM);}MagicMind算子 Kernel 的注册,这一步主要是实现 KernelFactory 以及注册执行设备,以便调用该算子。
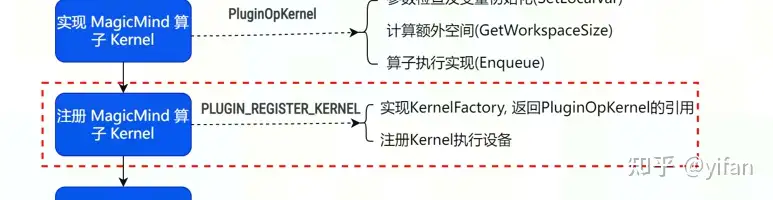
在实现完算子 Kernel 之后,还需要对算子 Kernel 进行注册,使得 Runtime 运行时能够识别并调用它。需要注册的信息包括算子 Name、设备类型以及 KernelFactory, 注册Kernel 使用 PLUGIN_REGISTER_KERNEL 进行注册。PluginAdd示例如下
class PluginAddKernelFactory : public IPluginKernelFactory {
public:
IPluginKernel* Create() override { // 重写Create接口 return new PluginAddKernel();
}
~PluginAddKernelFactory() {}};PLUGIN_REGISTER_KERNEL(CreatePluginKernelDefBuilder("PluginAdd").DeviceType("MLU"), PluginAddKernelFactory);注意:注册 Kernel 的 Name 要和前面注册算子的 Name 保持一致
算子 Kernel 注册完之后,还需要编译出一个动态库,供后面使用

如果涉及 BangC Kernel,需要使用 CNCC 将对应的 MLU 文件编译成.o文件,如下所示
cncc --bang-arch=compute_30 -c vectoradd_mlu_kernel.mlu -O3 -o vectoradd_mlu_kernel.o -fPIC
接着将实现好的 Plugin 文件和编译好的.o(如有)编译成动态库;如下所示
gcc --shared -fPIC plugin_add.cc vectoradd_mlu_kernel.o \ -I /usr/local/neuware/include -o libplugin.so
注:上面 BangC Kernel 的编译不是必须的,取决于 Enqueue接口是调用 BangC实现还是其他(如CNNL算子)
自定义算子的使用有两种方式,可以通过API使用,也可以通过parser使用

MagicMind INetwork 类提供了 AddIPluginNode 接口,它用来往网络中添加 Plugin 算子,并返回一个 Plugin 算子对象引用,C++示例如下,(调用PluginOp时需要在函数一开始调用dlopen打开对应plugin.so);如果调用PluginOp和PluginOp的文件同时编译,则不需要用dlopen
//调用PluginOp时需要调用dlopen打开对应plugin.soauto kernel_lib = dlopen("libplugin.so", RTLD_LAZY); //添加网络输入INetwork *network = CreateINetwork();ITensor *input1 = network->AddInput(magicmind::DataType::FLOAT16, Dims({1, 2, 2, 4}));ITensor *input2 = network->AddInput(magicmind::DataType::FLOAT16, Dims({1, 2, 2, 4}));TensorMap plugin_inputs;DataTypeMap plugin_outputs_dtype;//准备PluginOp的输入和输出类型std::vector<ITensor *> VInput1{input1};std::vector<ITensor *> VInput2{input2};plugin_inputs["input1"] = VInput1;plugin_inputs["input2"] = VInput2;plugin_outputs_dtype["output"] = std::vector<DataType>{magicmind::DataType::FLOAT16};// 添加PluginAdd节点IPluginNode *plugin_add = network->AddIPluginNode("PluginAdd", plugin_inputs, plugin_outputs_dtype);// 添加其它算子IMaxPool2DNode *pool = network->AddIMaxPool2DNode(plugin_add->GetOutput(0), true);// …通过Parser使用自定义算子,分别支持Pytorch/TF/ONNX,不支持Caffe.
1)使用PyTorch Parser
加载模型之前还需要注册自定义算子接口到 libtorch 中,可通过调用 LoadRegistedPlugin 接口来实现 libtorch 的算子注册,如下示例;
const char* op_name = "MyPlugin::custom_add"; // 算子名称static auto TorchLoadRegistedPlugin = LoadRegistedPlugin<ModelKind::kPytorch>;TorchLoadRegistedPlugin(
[op_name](const std::string& name) { return name == op_name; }, nullptr);2)OnnxParser
直接加载模型即可
3)使用 TensorFlow Parser 加载模型
TensorFlow Parser 加载模型之前还需要注册自定义算子到 libtf中,目前TensorFlow Parser 支持调用 LoadRegistedPlugin接口来实现libtf的算子注册。
const char* op_name = "TF_custom_add_op"; // 算子名称static auto TFLoadRegistedPlugin = LoadRegistedPlugin<ModelKind::kTensorFlow>;TFLoadRegistedPlugin(
[](const std::string& name) { return name == op_name; },
[](const std::string& name) { return op_name; });*注册自定义算子名字首字母要大写,后面的字符要属于字母、数字、下划线,否则注册到libtf中会失败。
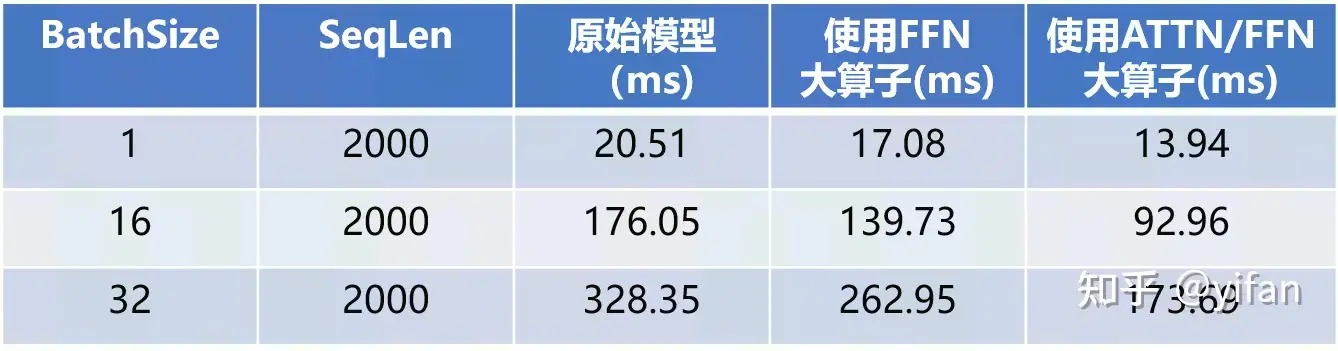
案例:在 MagicMind上测试 Conformer 网络性能时发现该网络时延较大,将网络结构中的 ATTN/FFN 结构分别替换为大算子,时延得到显著的减少,下图为 FFN 结构替换示例

该模型在 SeqLen=2000,BatchSize=1,16,32的时延对比表如下(测试环境:MLU370-X4, 测试精度为 Float32):
SyntaxHighlighter.all();
热门帖子
精华帖子





 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读