打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
知乎链接:https://zhuanlan.zhihu.com/p/612200712
若是初学者,建议先看前面的,尤其是其中的关于MagicMind的模块部分。
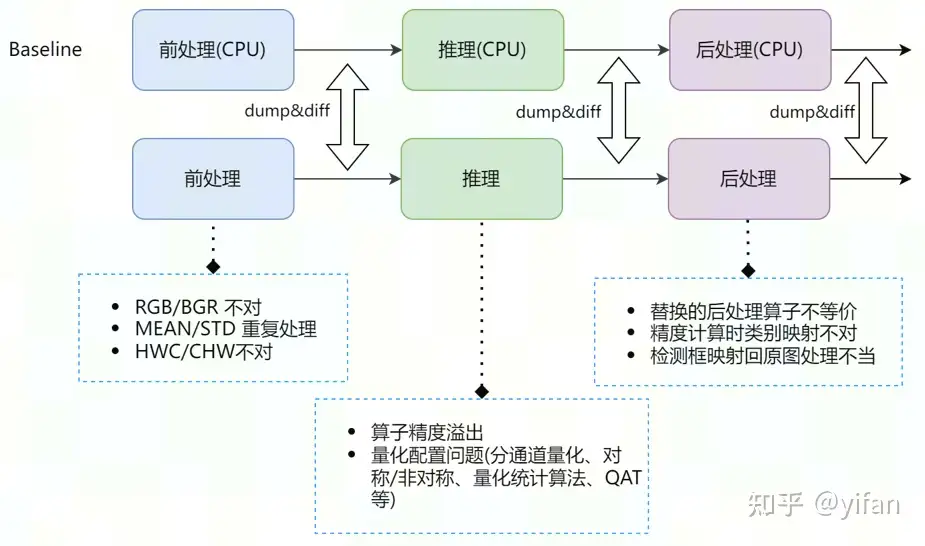
1) RGB/BGR 问题
训练时按 RGB 处理图片,推理时按 BGR 处理图片。
2) MEAN/STD 重复处理
生成模型时添加了 “insert_bn_before_firstnode”, 处理图片时依然做了减均值除方差操作。
3) CHW/HWC 问题
在推理 PyTorch/Caffe 模型时,CV 读取的图片没做 HWC 转 CHW 操作;或者生成模型时添加了 NCHW 转 NHWC 操作,CV 读取后依然做了 HWC 转 CHW 操作。
1)定位问题流程
如果已经确定是模型精度问题,可以借助精度对比工具,根据下面定位流程,再进行对比、分析,逐一解决问题
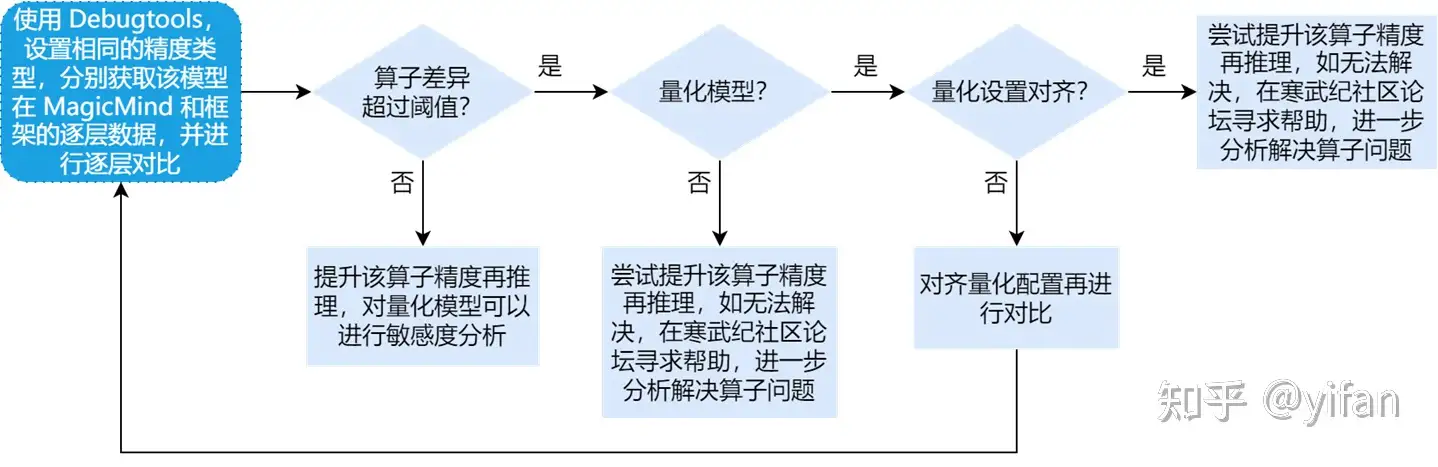
首先使用Debugtools,设置相同的精度类型,分别获取该模型在Magicmind和框架的逐层数据,并进行逐层对比
① 如果算子差异超过了阈值(一般是0.05),并且是量化模型,先看下量化设置是否已经对齐,没对齐需要对齐后再比对
② 如果已经对齐了,算子差异还是超过阈值,说明该量化算子在MagicMind上的实现可能有问题,可以尝试提升该算子精度,如果无法解决就需要在寒武纪社区论坛寻求帮助
③ 如果是非量化模型且算子差异超过阈值,说明该算子在MagicMind上的实现可能有问题;可以尝试提升该算子精度,如果无法解决就需要在寒武纪社区论坛寻求帮助
④ 如果算子差异没超过阈值,即框架模拟也有类似问题,说明该算子不适合该精度类型,可以提升该算子精度再推理;对量化模型可以进行敏感度分析,找出敏感算子来提升精度
2)常见问题
精度溢出:如果当前精度模式为非FP32,可以尝试提升精度模式后推理,但可能会影响推理性能,想要精度达标的同时保持性能,可以只将部分算子提升精度,具体配置方法参考《MagicMind特性之混合精度》课程。常见的有 norm、Rsqrt等算子在FP16精度下可能溢出。
量化配置:量化的配置也可能会造成精度问题,按层量化/按通道量化、量化对称/非对称、量化统计算法选择等;如网络中存在通道间常量分布范围差异较大的运算,却使用了按层量化;或网络中大部分节点的常量和输入范围都不是关于0点对称,却使用了对称量化等等;
3)常见问题举例
① 案例分析1(精度溢出)
Conformer 在测试 FP16精度时,精度异常;测试 FP32,精度正常;
和框架数据对比发现,网络中 Pow/ReduceMean/Add/Sqrt 等算子在 FP16 时精度溢出,将其调整为 FP32后精度正常
输出结果的 MSE 由原来的61% 下降到0.002%
auto name = node->GetNodeName();idx1 = name.find("Pow_");idx2 = name.find("ReduceMean_");idx3 = name.find("Add_");idx4 = name.find("Sqrt_");if (idx1 != -1) or (idx2 != -1) or (idx3 != -1) or (idx4 != -1):
for i in range(node.get_input_count()):
if node.get_input(i).get_data_type() in [DataType.FLOAT16]:
node.set_precision(i, DataType.FLOAT32)
for i in range(node.get_output_count()):
if node.get_output(i).get_data_type() in [DataType.FLOAT16]:
node.set_output_type(i, DataType.FLOAT32)② 案例分析2(敏感度分析)
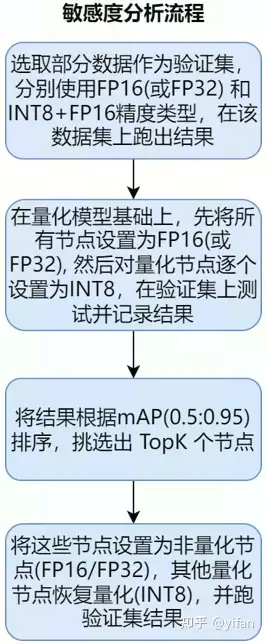
Yolov6s 在 INT8+FP16 模式下精度比 FP16 的精度低了很多
通过 Debugtools 发现 MagicMind 的算子精度和框架模拟差异较小
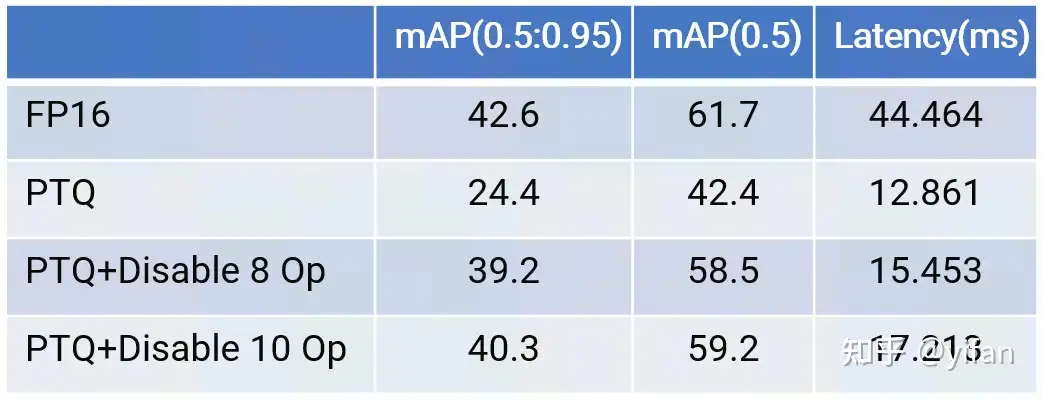
通过敏感度分析,选出了10个对精度影响比较大的量化算子,并改为 FP16计算
对比结果如下表所示(BatchSize=24, MLU370-S4)
1)问题介绍
替换的后处理算子不等价:某变种 SSD 后处理的 decode 部分发生变化,已有的 MLU SSD 后处理算子与之不等价,替换后造成结果不对。
精度计算时类别映射不对:COCO2017数据集共80小类,但类别 id 号不连续,最大为90,如果不做处理会导致计算的 mAP异常。
检测框映射回原图处理不当:推理时对输入做了等宽高比的 resize,检测结果是针对处理后的输入,将结果映射回原图处理不当,框偏移了也会导致 mAP异常

2)案例分析
SSD-ResNet34 模型在 MLU 上适配完(INT8+FP16),并替换好后处理算子后,单张图检测结果和 CPU基本一致,但是计算数据集的 mAP却异常。定位发现,只计算 Person 类别时,结果是对的,打印每一个类的 mAP发现第12类之后所有类 mAP为0或者-1,确定是类别映射错误导致的 mAP不对。
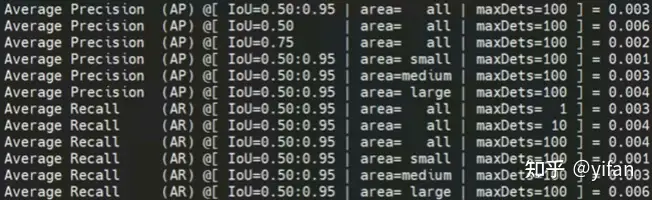
模型(INT8+FP16)精度正常结果如下图
当网络的最终结果不正确时,可能是网络中的某个算子出现了精度问题。为了帮助用户定位具体哪个算子出现了精度问题,MagicMind提供了Tensor Dump和精度对比工具。这个工具支持导出MagicMind运行网络时产生的中间结果,并与TensorFlow、Caffe、PyTorch、ONNX等框架运行网络时产生的中间结果进行比对,以定位MagicMind具体哪个算子的精度有问题。
精度对比步骤是,将输入文件和模型文件给到原生框架,调用tensor dump 工具,导出中间结果数据等文件,再用同样的输入文件和经过修改后的模型文件传给MagicMind后端进行计算,导出中间结果文件,最后用精度对比工具对比两边同名的结果数据文件,生成包含每个中间结果对比信息的json
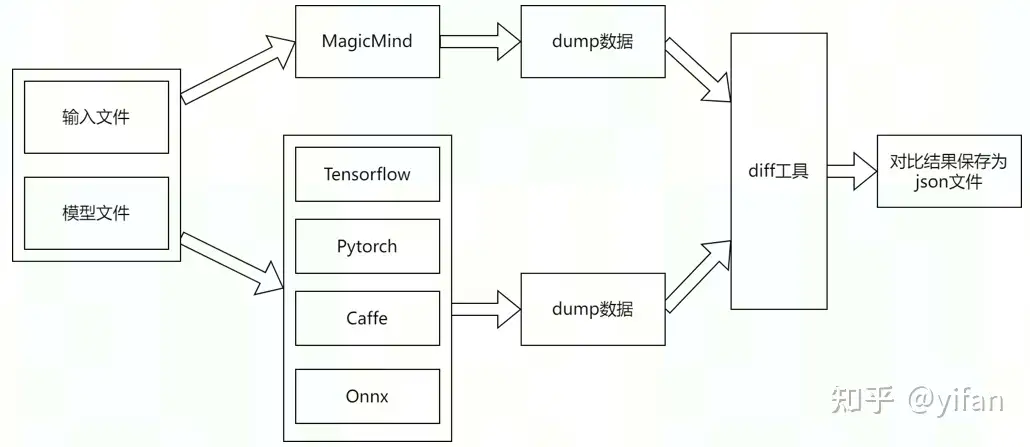
MagicMind提供了 TensorFlow、Caffe、PyTorch、ONNX 等框架对应的 Dump工具来导出中间结果文件以及处理过的模型文件。若要与 MagicMind 运行后的结果做对比,需要使用 MagicMind 加载这个处理过的模型文件(TF 除外)。(相应的工具可以在 MagicMind wheel 包安装后找到,如 /usr/lib/python3.7/site-packages/magicmind/tools/debug_tools)
1)框架的 Tensor Dump
下面是一个 PyTorch模型的 Dump 示例
dump_pytorch.py \ --model_file /path/to/your/pt_file/model.pt \ --bin_files /path/to/your/bin_file /path/to/your/bin_file2 \ --dump_dir "/path/to/your/dump_files/" \ --dump_model_dir "/path/to/dump/pytorch_processed_model/" \ --input_shapes [1,3,224,224] [1,3,224,224] \ --tensor_format "pb" --dump_all "True" \ --precision_mode "qint8_mixed_float32" \ --calibrate_inputs_dirs /path/to/your/calibrator_file_folder \ --quantize_algorithm "linear" \ --int_ops "Conv" "FC" "DeConv" \ --input_channel_quantize "False" \ --filter_channel_quantize "False" \ --asymmetric_quantize "False" --fold_conv_bn "False"
2)MagicMind的 Tensor Dump
精度对比工具只对比 Tensor Name 相同的中间结果,在导出中间结果文件之前,需要先指定每个中间结果的名字。中间结果的名字是在构建网络阶段指定的,目前 MagicMind支持两种网络构建方式:
方式一:调用 Network API 逐个算子构建网络
方式二:用 Parser 直接导入人工智能框架模型构建网络
通过方式一构建网络,可以通过调用 ITensor::SetTensorName 接口来设置中间结果名字, 名字要与原生网络对应上。一个具体的示例如下
IConvNode *conv = network->AddIConvNode(input, weight, bias); // 添加卷积节点conv->GetOutput(0)->SetTensorName("conv1_output"); // 设置conv的输出name为conv1_output通过方式二构建网络,MagicMind的 Parser 会从原框架模型中获取名字并自动设置。
MagicMind运行时默认不 Dump 任何中间结果,用户需要调用额外的配置接口来控制 MagicMind 中间结果 Dump 行为。具体的做法是在运行期:
创建 ContextDumpInfo 数据结构,并配置成员变量控制 Dump 的行为。
将 ContextDumpInfo 绑定到某个具体的 IContext 对象上,Dump 配置只对该 IContext 对象生效。
下面给出一个具体的 C++ 使用示例:
IContext::ContextDumpInfo dump_info;// kOff: 关闭dump模式; kSpecificTensors: dump指定tensor; kAllTensors: dump所有tensor; kOutputTensors: dump输出tensor//设置 Dump 模式dump_info.SetDumpMode(IContext::ContextDumpInfo::DumpMode::kSpecificTensors);dump_info.SetPath("dump_test"); // 将dump结果存放到dump_test目录下// dump名字为 ``input`` 和 ``output`` 的 tensor信息,若不进行设置,默认dump 所有tensor信息std::vector<std::string> tensor_names = {"input", "output"}; //设置需要 Dump 的 Tensor 名字dump_info.SetTensorNames(tensor_names);//设置 Dump 文件保存格式: kBinary 文件保存为pb格式; kText 文件保存为pbtxt格式dump_info.SetFileFormat(IContext::ContextDumpInfo::FileFormat::kText);// 为IContext对象绑定dump配置,使能dump功能context->SetContextDumpInfo(dump_info);ContextDumpInfo 提供的可配置属性说明如下:
| 参数 | 参数说明 |
| dump_mode | 取值为 -1 时不使能 Dump 功能。取值为 0 时只 Dump 指定 Name 的 Tensor 信息。取值为 1 时 Dump 所有 Tensor 信息。取值为 2 时 Dump 输出 Tensor 信息。 |
| path | Dump 出的数据文件存放路径。 |
| file_format | Dump 文件格式设置,默认为0,取值为0时是二进制格式,后缀名为 pb; 取值为1时是文本格式,后缀名为 pbtxt。 |
| tensor_name | 需要 Dump 的中间结果名字,可以指定多个。 |
| 参数 | 参数说明 |
| dump_mode | 取值为 -1 时不使能 Dump 功能。取值为 0 时只 Dump 指定 Name 的 Tensor 信息。取值为 1 时 Dump 所有 Tensor 信息。取值为 2 时 Dump 输出 Tensor 信息。 |
| path | Dump 出的数据文件存放路径。 |
| file_format | Dump 文件格式设置,默认为0,取值为0时是二进制格式,后缀名为 pb; 取值为1时是文本格式,后缀名为 pbtxt。 |
| tensor_name | 需要 Dump 的中间结果名字,可以指定多个。 |
| 参数 | 参数说明 |
| dump_mode | 取值为 -1 时不使能 Dump 功能。取值为 0 时只 Dump 指定 Name 的 Tensor 信息。取值为 1 时 Dump 所有 Tensor 信息。取值为 2 时 Dump 输出 Tensor 信息。 |
| path | Dump 出的数据文件存放路径。 |
| file_format | Dump 文件格式设置,默认为0,取值为0时是二进制格式,后缀名为 pb; 取值为1时是文本格式,后缀名为 pbtxt。 |
| tensor_name | 需要 Dump 的中间结果名字,可以指定多个。 |
| 参数 | 参数说明 |
| dump_mode | 取值为 -1 时不使能 Dump 功能。取值为 0 时只 Dump 指定 Name 的 Tensor 信息。取值为 1 时 Dump 所有 Tensor 信息。取值为 2 时 Dump 输出 Tensor 信息。 |
| path | Dump 出的数据文件存放路径。 |
| file_format | Dump 文件格式设置,默认为0,取值为0时是二进制格式,后缀名为 pb; 取值为1时是文本格式,后缀名为 pbtxt。 |
| tensor_name | 需要 Dump 的中间结果名字,可以指定多个。 |
| 参数 | 参数说明 |
| dump_mode | 取值为 -1 时不使能 Dump 功能。取值为 0 时只 Dump 指定 Name 的 Tensor 信息。取值为 1 时 Dump 所有 Tensor 信息。取值为 2 时 Dump 输出 Tensor 信息。 |
| path | Dump 出的数据文件存放路径。 |
| file_format | Dump 文件格式设置,默认为0,取值为0时是二进制格式,后缀名为 pb; 取值为1时是文本格式,后缀名为 pbtxt。 |
| tensor_name | 需要 Dump 的中间结果名字,可以指定多个。 |
| 参数 | 参数说明 |
| dump_mode | 取值为 -1 时不使能 Dump 功能。取值为 0 时只 Dump 指定 Name 的 Tensor 信息。取值为 1 时 Dump 所有 Tensor 信息。取值为 2 时 Dump 输出 Tensor 信息。 |
| path | Dump 出的数据文件存放路径。 |
| file_format | Dump 文件格式设置,默认为0,取值为0时是二进制格式,后缀名为 pb; 取值为1时是文本格式,后缀名为 pbtxt。 |
| tensor_name | 需要 Dump 的中间结果名字,可以指定多个。 |
也给出 Python 代码如下:
from magicmind.python.runtime import Context, DumpMode, FileFormatdump_info = Context.ContextDumpInfo(path="/tmp/output_pb/", tensor_name=[], dump_mode = DumpMode.kSpecificTensors, file_format = FileFormat.kBinary)dump_info.val.dump_mode = DumpMode.kSpecificTensors # kOff: 关闭dump模式; kSpecificTensors: dump指定 tensor; kAllTensors: dump所有tensor; kOutputTensors: dump输出tensordump_info.val.path = "/tmp/output" # 将dump结果存放到/tmp/output目录下dump_info.val.tensor_name = ["input"] # dump名字为 ``input`` 的 tensor信息,若[]为空,则dump 所有tensor信息dump_info.val.file_format = FileFormat.kBinary # kBinary 文件保存为pb格式; kText 文件保存为pbtxt格式self._context.set_context_dump_info(dump_info)
3)结果分析
MagicMind提供了 analysis_tools.py 脚本来分析导出的中间数据,可用于自动对比原框架中间数据与 MagicMind中间数据并生成对比结果文件,或是用于解析pb格式文件,转换成可读文件从而进行人工调试。
当主参数为 compare 时,会把所有中间结果的序列化pb格式文件进行对比,每个tensor的对比结果构成一个字典,所有对比结果构成一个列表,用一个diff.json文件保存在json_files文件夹中。一个具体示例如下:
analysis_tools.py compare \ --src_dir path/to/ work_dump_files \ --dst_dir path/to/magicmind_dump_files \ --output_dir path/to/your/json_files/ \ -- work pytorch
| 参数 | 参数说明 |
| compare | 必选。比较两个文件夹中的pb文件。与 convert、single 互斥。 |
| convert | 必选。把一个pb格式文件转换成可读文件。与 compare、single互斥。 |
| single | 必选。比较两个独立的pb格式文件,根据给定阈值和比较模式输出结果文件。与 compare、single 互斥。 |
SyntaxHighlighter.all();
热门帖子
精华帖子





 Ashelly
13 回复
Ashelly
13 回复
 fengyunkai
1 回复
fengyunkai
1 回复
 三叶虫
3 回复
三叶虫
3 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读