打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
知乎链接:https://zhuanlan.zhihu.com/p/612560935
若是初学者,建议先看前面的,尤其是其中的关于MagicMind的模块部分。
吞吐率(Throughput):在单位时间内能完成多少次推理请求。
Throughput(qps) = Batchsize per launch * Launch times / Walltime
延时(Latency):指单次推理请求的总响应时间。包括H2D + Compute + D2H的时间
Latency = D2HEnd – H2DStart = H2D time + Compute time + D2H time
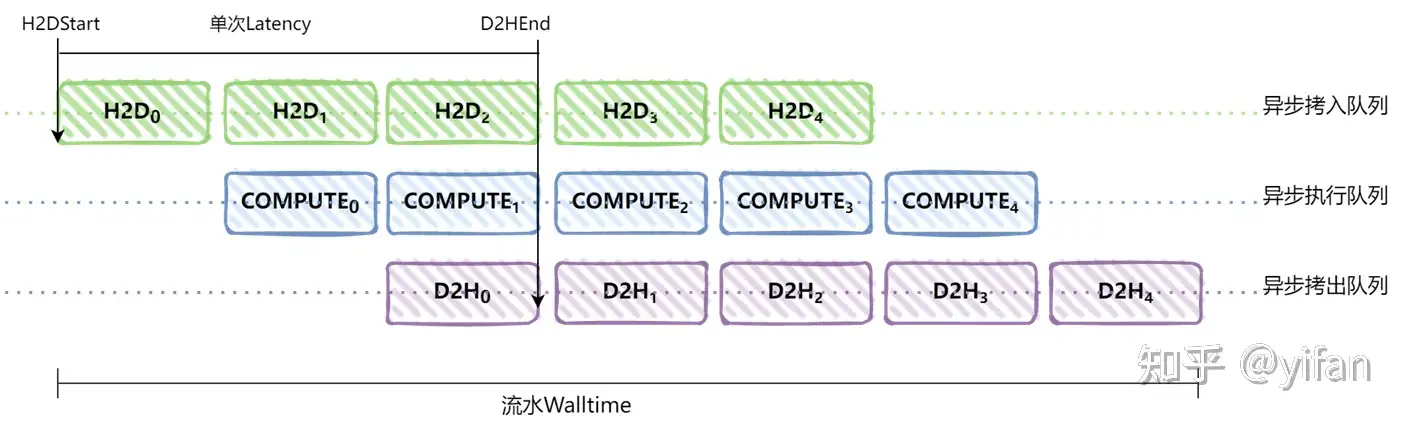
为了实现高吞吐率,业务层面通常会实现三级流水,让不同请求之间的计算和内存拷贝并行起来,如图所示:其中 H2D 表示数据拷入到设备端(host to device),COMPUTE 表示推理计算,D2H 表示数据拷出到主机端(device to host),下标表示第 n 次推理请求。walltime 是主机端总的执行时间。整体的吞吐率等于每次下发的BatchSize乘以walltime内下发的次数,除以walltime
一个完整的MagicMind推理通常流程包括:数据前处理->推理->数据后处理。我们的性能优化思路也是从这三个方面去考虑。
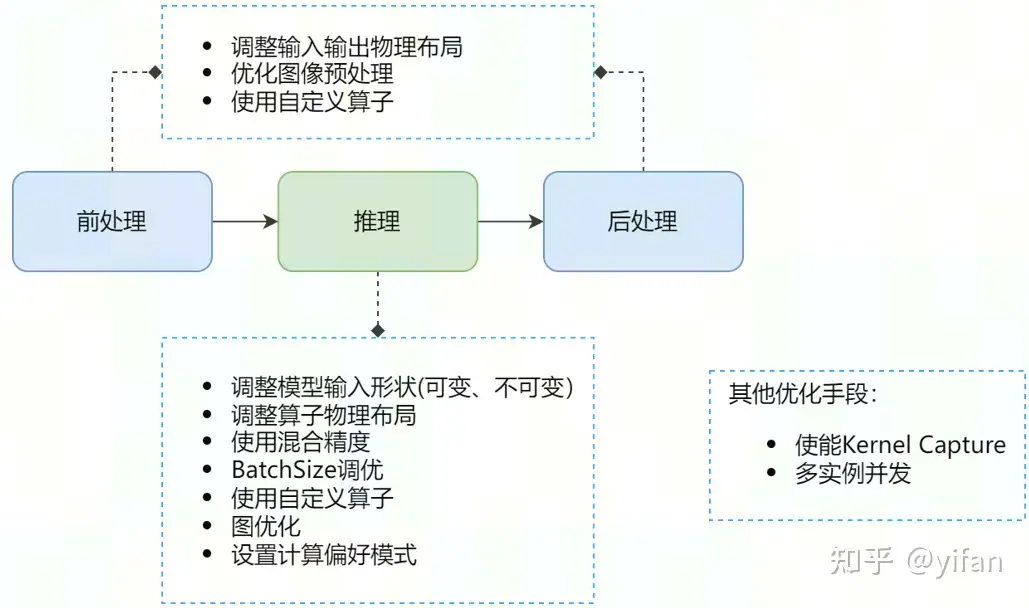
前后处理常用的优化手段有调整输入输出物理布局,优化图像预处理、使用自定义算子等;
模型推理的常用优化手段有调整模型的输入形状,包括可变和不可变,调整算子物理布局、使用混合精度、BatchSize调优、使用自定义算子、设置计算偏好模式等;
此外,还有多实例并发、使能 kernel capture 等其他优化手段
1)调整输入输出物理布局
原理:通过 PyTorch parser 或 Caffe parser 导入的模型,其输入输出物理布局默认是 NCHW。在预处理允许输出布局为 NHWC 数据的情况下,我们可以将推理部分的输入输出物理布局调整为 NHWC,从而提升推理性能。因为MagicMind的大部分算子都是根据 NHWC 进行布局的。
使用方法:

2)优化图像预处理
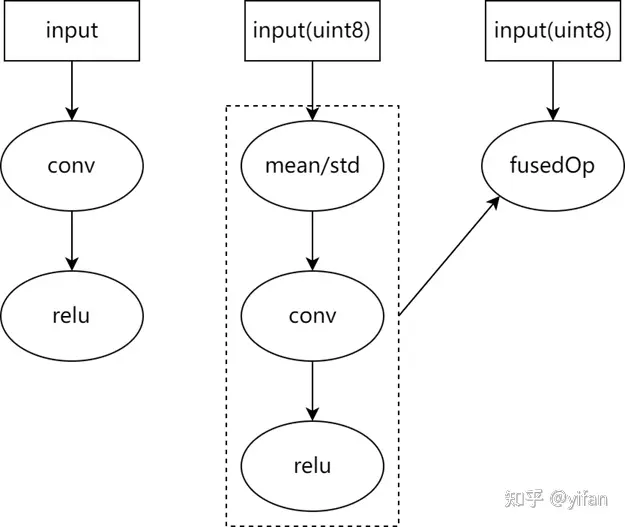
原理:MagicMind支持将部分图像预处理操作合并到推理模型中,进行算子融合,从而实现推理加速。目前支持融合的图像预处理操作为:减均值除方差。其原理如下图所示:
使用方法:在 BuilderConfig中设置 insert_bn_before_firstnode配置项来使能该功能。下面展示了一个通过 json文件配置的具体示例:

3)使用自定义算子
原理:MagicMind提供了自定义算子的功能,用户可以用 BANG C 自行实现一个高性能的 MLU 算子,并嵌入到网络中,实现定制化的性能优化。
使用方法:参见之前的《MagicMind特性之 PluginOp》课程。
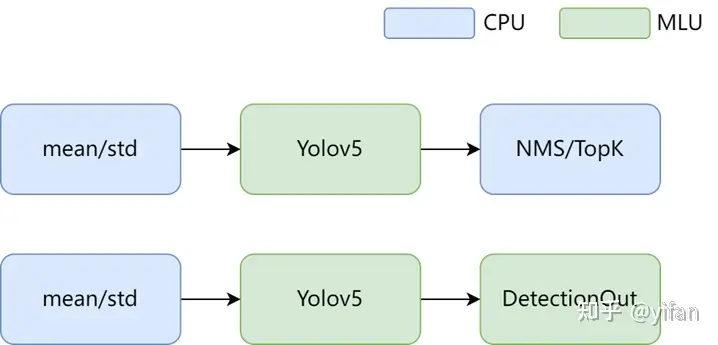
如Yolov5的后处理,我们可以将其写成一个 DetectionOutput,将 NMS/TOPK这些操作变成一个自定义算子,加快整个网络的执行。
1)模型输入形状优化(可变/不可变)

原理:MagicMind支持模型的输入形状在运行时可变,对于卷积网络(比如 ResNet),MagicMind目前仅对 N(BatchSize)、H(Height)、W(Width)维度可变进行性能优化。
其中,配置项 graph_shape_mutable 作为标志网络是否可变的总开关,默认为 true ,表示该网络是可变的。
① 模型输入形状优化(不可变)
使用方法1:如果实际业务场景没有输入形状可变的需求,可以通过固定模型输入形状来获得更好的推理性能。用户可以在生成模型时,通过 BuilderConfig中 graph_shape_mutable配置项来设置。示例如下:
IBuilderConfig *config = CreateIBuilderConfig();
config->ParseFromFile("build_config.json");
IModel *model = builder->BuildModel("model_name", network, config);
// 单独的 build_config.json 文件
{
"graph_shape_mutable": false,
}② 模型输入形状优化(可变)
使用方法2:如果实际业务场景需要可变的输入形状,可以通过设置场景需要的最小值和最大值的输入形状,来尽可能的提升推理性能。在生成模型时,需要将配置项 graph_shape_mutable设置为 true ,然后设置配置项 dim_range,来设置应用场景的输入形状范围。示例如下:
// 单独的 build_config.json 文件{
"graph_shape_mutable": true,
"dim_range": {
"0": {
"min": [1, 224, 224, 3],
"max": [12, 224, 224, 3]
}
}}注:运行时,需要指定网络输入维度,且在dim_range范围内。
2)调整算子物理布局
原理:大部分硬件在架构设计上都会有偏好的物理布局,在软件层面合理地安排数据的物理布局可以极大地提升系统性能,降低系统功耗。为了满足通用性需求,MagicMind在编程接口上支持用户选择多种物理布局,比如同时支持 NHWC 和 NCHW。为了满足性能需求,MagicMind会在图优化阶段进行物理布局优化。
使用方法:算子的物理布局可以调用算子的 SetLayout接口进行设置,不设置的情况下会默认使用算子的最优物理布局(通常是 Channel Last)。下面是一个手动设置物理布局的示例:
IConvNode *conv = network->AddIConvNode(input, weight, bias);conv->SetLayout(Layout::NHWC, Layout::NHWC, Layout::NHWC); // 设置conv 的输入、输出、常量数据的物理布局分别为 NHWC、NHWC、NHWC
3)使用混合精度
原理:MagicMind提供了 QINT8、QINT16、FP16、FP32 等多种推理精度支持,并对用户开放了精度模式选择接口。选择位宽较低的精度可以获得更好的性能,但有可能导致网络精度下降。默认情况下,MagicMind使用 FP32 进行推理,优先确保精度。如果追求极致性能,可以尝试使用 qint8_mixed_float16 混合精度模式进行推理,即性能最佳模式。
使用方法:可以参考《MagicMind特性之混合精度》课程。
4) 使用自定义算子
原理:对于网络中的某些结构,可通过实现一个高性能的 MLU 算子实现定制化的性能优化。如 Bert 网络的Self-Attention 结构 和 FFN 结构。
使用方法:可参考《MagicMind特性之 PluginOp》课程。
5) 图优化
原理:MagicMind 内置了大量图优化策略,能够帮助用户提升整体的推理性能。然而部分图优化策略可能会改变计算顺序,影响数据分布。某些看似等价的数学变换,在使用低精度推理的情况下,存在精度溢出的可能性,影响网络最终精度。MagicMind 将某些会影响精度的图优化策略默认设为关闭,并提供使能配置,允许用户权衡精度和性能。
使用方法:通过 BuilderConfig的 opt_config配置项,如下所示:
IBuilderConfig *config = CreateIBuilderConfig();config->ParseFromFile("build_config.json");IModel *model = builder->BuildModel("model_name", network, config);
// 单独的 build_config.json 文件{
"opt_config": {
"conv_scale_fold": false
},}6) 设置计算偏好模式
原理:MagicMind 提供了“auto”、“fast” 和 “high_precision” 三种计算偏好模式支持,并对用户开放了计算偏好模式设置接口。
“fast” 模式可以获得更好的性能,但有可能导致网络精度下降。如果追求极致性能,可以尝试使用 “fast” 计算偏好模式进行推理。
“high_precision” 模式可以获得更高的精度,但有可能导致网络性能下降。
默认情况下,MagicMind 使用 “auto” 模式,该模式为保持目前实现现状,理论上尽可能避免用户再手动设置计算偏好,做到在默认情况下精度和性能都满足要求。
使用方法:通过BuilderConfig中 computation_preference配置项来选择网络的计算偏好模式, 不设置的情况下会默认使用 “auto” 计算偏好模式。示例如下:
IBuilderConfig *config = CreateIBuilderConfig();config->ParseFromFile("user_config_path/build_config.json"); // 一个 build_config.json 示例{
"computation_preference": "fast"}IModel *model = builder->BuildModel("model_name", network, config);7) BatchSize调优
① 增大BatchSize
原理:过小的 BatchSize无法把 MLU 核充分利用起来,增大 BatchSize能提高 MLU 利用率。
使用方法:在单个推理实例(IContext)独占 MLU 设备的场景下,尝试增大输入 Batch Size 能提高吞吐率。
② BatchSize补齐
原理:MagicMind会优先在 Batch 维度对任务进行并行拆分,每个 MLU cluster 处理不同的输入 Batch。当 BatchSize不能整除可用 Cluster 数时,一些 Cluster 会多处理余数部分,拖慢整体性能。
使用方法:在单个推理实例(IContext)独占 MLU 设备的场景下,将 BatchSize设置为硬件 Cluster 数的整数倍能提高吞吐率。 对于 MLU370-S4,输入 BatchSize是 6 的倍数时吞吐率最佳,对于 MLU370-X4,输入 BatchSize是 8 的倍数时吞吐率最佳
1)多实例并发
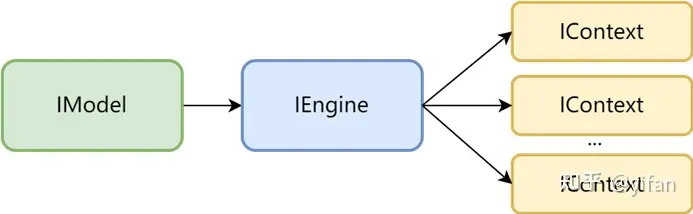
原理:当 MLU 核利用率没有达到 100% 时,可以通过并发多个推理实例(IContext)来提高吞吐率。MagicMind支持用同一个 IEngine创建多个推理实例(IContext),多个实例可以绑定不同的 cnrtQueue,并发地执行在同一设备上。
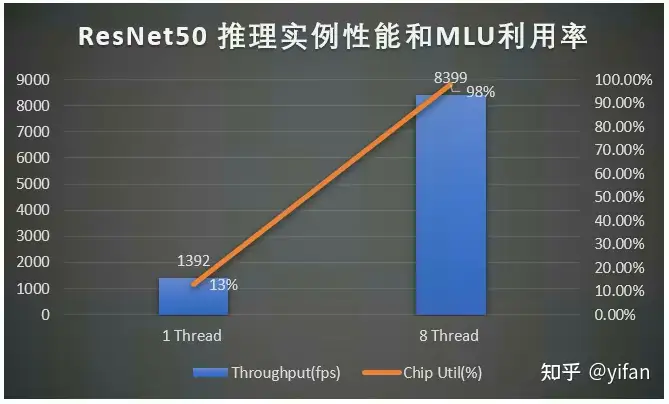
使用方法:创建多个实例执行,下图展示了用 mm_run运行ResNet50推理实例(IContext)的性能和 MLU 利用率,输入 BatchSize为 1,数据类型为INT8+FP16, 以下设备是MLU370-X4。
2)使能Kernel Capture
使用的原因:MLU 是一个从设备,用户需要在主机端调用异步接口 Enqueue 下发任务给 MLU 执行。存在某些业务场景,主机端下发任务的速度比 MLU 执行任务的速度慢,从而导致 MLU 空闲,整体性能不理想。MagicMind 提供了 kernel capture 功能,可以在受限场景下缓解主机端下发任务速度慢问题,提升上述业务场景的推理性能。
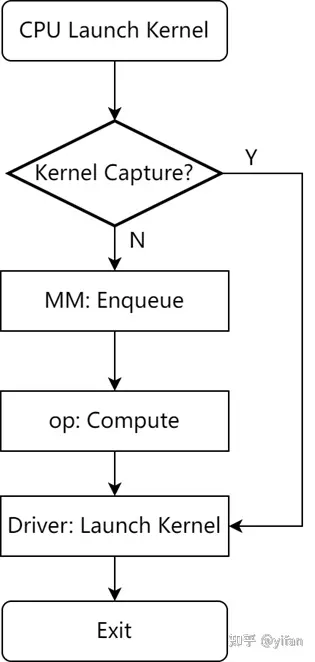
Kernel Capture 的基本原理:在模型的 Kernel 执行顺序和 Kernel 参数固定的情况下,提前执行模型中的所有 Kernel 并捕获(缓存)这些 Kernel 和对应的执行参数,在后续推理迭代中一直复用捕获的 Kernel 以及执行参数,从而节省主机端下发任务的时间。Kernel Capture 的原理如图所示:
如果明确知道业务场景满足如下条件:
主机端 CPU 比较弱,性能不理想。
模型输入的 Workload 很小(根据经验,Batch = 1 会是比较常见的场景)。
网络最终执行计算时,算子数量较多且 MLU 执行时间较短(可通过 Profile 工具查看)。
则可以尝试使能 Kernel Capture,来观察性能是否有提升。
使用方法:用户可按照下述示例代码在创建 Engine 的时候使能 Kernel Capture 功能:
magicmind::IModel::EngineConfig config;config.SetKernelCapture(true);config.SetIoAddrImmutable(true); //输入输出地址不可变auto engine = model->CreateIEngine(config);
约束:只支持纯静态模型,即IBuildConfig中的 graph_shape_mutable参数需要配置为 false。
SyntaxHighlighter.all();
热门帖子
精华帖子





 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读