打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
【寒武纪硬件产品型号】必填*:MLU370-x8
【MagicMind版本号】必填*: magicmind v1.5.0
【操作步骤】选填:
参考 Resnet50 QPS 为什么在 MLU370-x8上 只能达到 1200? - 寒武纪软件开发平台 - 开发者论坛 (cambricon.com) 生成magicmind 模型
模型推理脚本如下
import os
import numpy as np
import magicmind.python.runtime as mm
import sys
import torch
import onnxruntime as ort
'''
magicmind 执行一次ChatGLM-6B 推理
'''
# sys.path.append("..")
sys.path.append("magicmind/utils")
sys.path.append("magicmind/python_common")
sys.path.append("magicmind/cpp_common")
from utils import Record
from mm_runner import MMRunner
torch.manual_seed(666)
def prepare_inputs_for_generation():
# np.random.seed(1)
input = np.ones((16,3,224,224),dtype=np.float32)
return [ input ]
resnet50_int8_model_path = "resnet50-v1-12_qint8_mixed_float32.magicmind"
model_inputs = prepare_inputs_for_generation()
resnet50_int8 = MMRunner(resnet50_int8_model_path, device_id=0)
# 1, 8, 32, 64, 188
import time
start = time.time()
for i in range(1):
output = resnet50_int8(model_inputs)
end = time.time()
print("time consume is ",end-start,"s")
# print(output)cnperf 命令如下
cnperf-cli record python magicmind_resnet50_int8_demo.py
cnperf-cli timechart
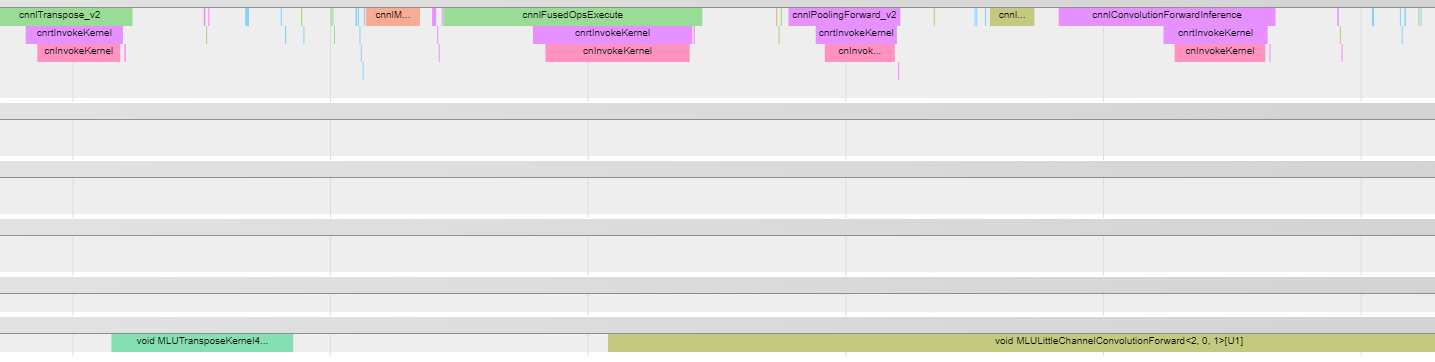
cnperf 采集结果如下
从 cnperf 采集到的timechart 结果来看,模型执行一次推理时的任务下发方式是由host侧做调度管理的。
我的问题如下:
1. 为什么任务下发要由 Host 侧进行?通过Host侧做任务下发,岂不是会受限于Host侧的CPU的性能。
2. 这种任务下发方式是否是导致 Resnet50 QPS 为什么在 MLU370-x8上 只能达到 1200? - 寒武纪软件开发平台 - 开发者论坛 (cambricon.com) 这个帖子中 QPS 太差的直接原因?
热门帖子
精华帖子





 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读