打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
原文链接:如何在使用寒武纪MLU的情况下,编写pytorch代码? - 知乎 (zhihu.com)
1、Cambricon PyTorch 概述
1.1 PyTorch 框架介绍
PyTorch 是一款 开源的人工智能编程框架,适用于 Python、C++ 等编程语言,用以实现高效的 GPU 等并行计算及人工智能网络搭建,具有轻松拓展、快速实现、生产部署稳定性强等优点。
PyTorch 在 Python 中重新设计和实现 Torch ,同时在后端代码中共享相同的核心 C 库。因此 PyTorch 的后端不是单一的,可以通过 Python C 扩展模块将 Torch 库中的 Python 接口与底层 C/C++ 实现衔接,并通过底层 C/C++ Aten 模块实现不同后端的适配,CPU/GPU/TPU 等等。
1.2 PyTorch 后端适配
PyTorch 对后端设备的适配主要依赖 Aten 模块和 PyTorch Extension扩展机制: Aten 模块 (A Tensor Library)是 PyTorch 的 C/C++ Tensor 库,提供了很多张量操作和集成了不同后端的前后向计算算子。此外,上层 Python 算子接口也是在该模块下确定其应该调用哪个计算算子并分发到哪个后端设备。
PyTorch Extension 扩展机制:寒武纪设备后端的 Aten 代码都封装在 Catch 包中,Catch 包以 Patch 方式将编译好的设备后端Aten代码合入原生 PyTorch 工程,其中寒武纪 Cambricon PyTorch 适配方案如下图所示:
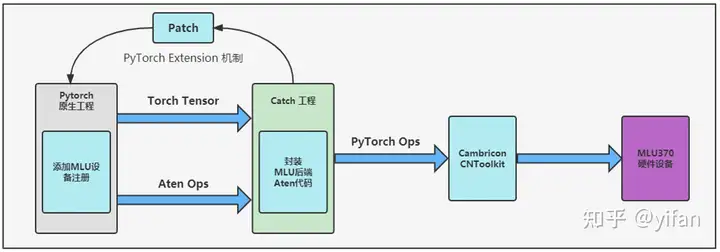
1.3 Cambricon PyTorch 概述
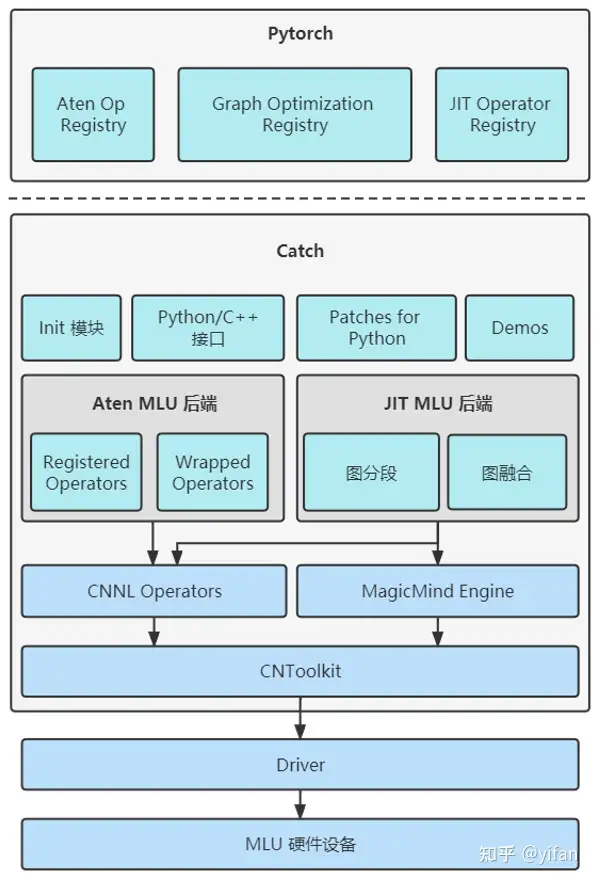
Init 模块:初始化 CATCH 库并将 MLU 算子、图分段算法以及图优化算法注册到 PyTorch 中。
Python/C++ 接口:封装了⼀些 Python 转 C++ 调用的接口来提供⼀些拓展功能。
Patches for Python:新增的 Cambricon PyTorch Python 接口。
Demos:新增的 Cambricon PyTorch 网络模型 Demos。
Aten MLU 后端:包括 MLU Operator Register 和 MLU Operator Wrapper 组件。 MLU Operator Register 模块会调用 PyTorch 中的相关函数将 MLU 算子注册到 PyTorch 中。 MLU Operator Wrapper 用来封装 MLU 算子。
JIT MLU 后端:MLU 图分段、图融合算法。MLU图分段算法会根据MagicMind算子支持情况将图中节点划分成若干子图。MLU 图融合算法用于完成MLU融合算子的创建和编译。
2、Cambricon PyTorch 架构设计
2.1 寒武纪软件栈介绍
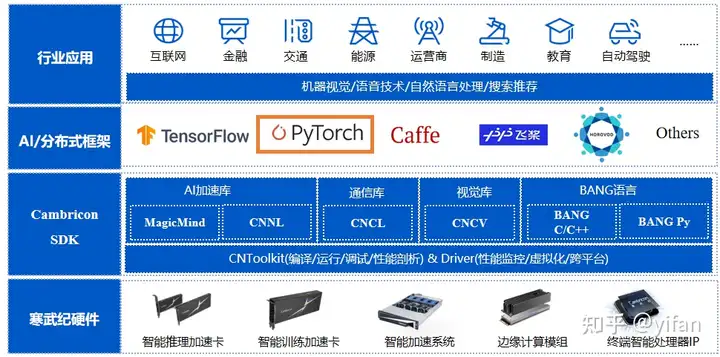
2.2 Cambricon PyTorch 系统架构
1)相关名词解释
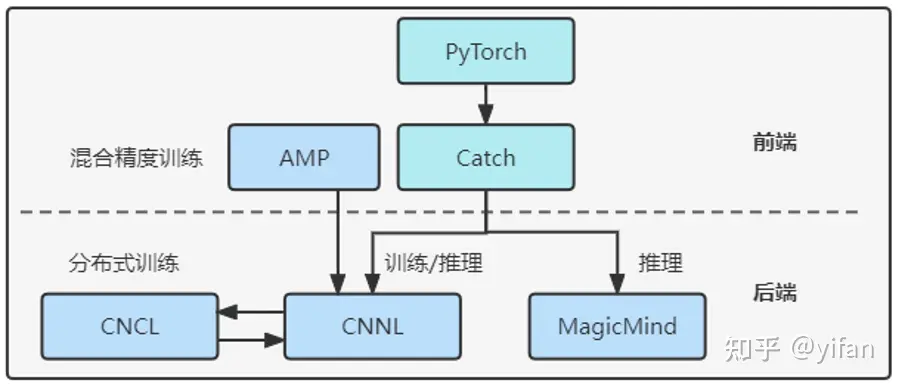
Cambricon PyTorch 训推一体:系统架构分为前端和后端两部分,前端指的是 Torch 和 Catch 中的各种算子接口,后端指的是 CNNL 和 MagicMind ;
CNNL:寒武纪人工智能计算库,支持丰富基本算子、可变输入推理、量化训练和混合精度训练;
MagicMind:寒武纪推理加速引擎,支持灵活输入维度、多种量化模式、多种图优化算法,给用户带来极致推理性能;
2)训推一体系统架构
前端为 Catch 和 Pytorch 库,后端为 CNNL MagicMind ,特殊情况下,如混合训练时前端还包括 AMP 库,分布式训练时后端需要CNCL+CNNL
3)训练
使用cnnl后端,有4种训练模式分别为:量化感知训练、分布式训练、混合精度训练、单机单卡浮点训练如图所示,完成训练得到浮点模型,其中训练时mlu不支持的算子也会自动使用cpu进行训练;
使用Cambricon Pytorch 进行推理时,有Eager 模式和 Jit模式,Eager 模式只能使用 float精度进行推理,Jit模式可以选择int量化或者float模式
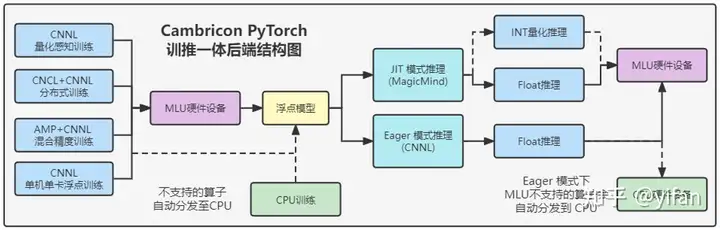
2.3 Cambricon PyTorch 训练模式
单机单卡浮点训练模式:使用 CNNL 作为后端,无需进行量化设置和分布式设置,灵活简单易用,可快速逐层调试,并且可以在单卡上发挥良好的训练性能和得到高训练精度,并且mlu不支持的算子可以自动分发到cpu执行。
首先 torch api或者pt加载模型
模型中的算子逐层经过pytorch的 dispatch 模块进行 cpu/mlu算子分发,即mlu支持的算子优先使用mlu,mlu不支持的算子使用cpu进行运算,分发到mlu上的算子会进入到catch库中,先使用catch库中的catch dispatch 模块进行 cnnl 算子分发
分发完毕后会进入到runtime阶段,其中runtime阶段的流程如图所示,得到一个cnnlqueue,最后进行cnrtsyncqueue将cnnlqueue下发至驱动进行运算并返回结果
如果mlu算子后面还接着cpu算子,将继续使用cpu进行运算
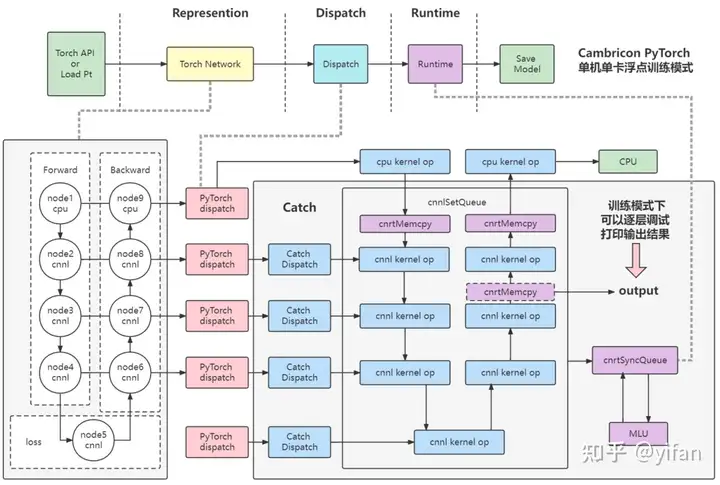
其中:
PyTorch Dispatch:该模块为PyTorch 包中的分发模块,根据算子注册列表,将PyTorch Python层算子接口分发至后端,指定每一个算子的后端设备(cpu/mlu)。
Catch Dispatch:该模块为Cambricon Catch 包中的分发模块,根据MLU的算子注册列表,对每一个进入Catch的算子进行分发和 CNNL 接口指定。
Runtime:调用cnrtSyncQueue,将CNNL 的计算队列进行下发至驱动,并执行队列内的 kernel 函数计算并返回结果。
逐层调试:该训练模式下,支持逐层调试,打印某一层输出时会将输出结果通过 cnrtMemcpy 将数据从 Device 端拷贝到 Host 端。
2.4 Cambricon PyTorch 推理模式
两种推理模式:Eager 推理模式和 JIT 推理模式
1)Eager 推理模
该模式与单机单卡浮点训练模式类似,同样使用cnnl后端。整体计算方式和训练相似,不同之处在于推理时不需要进行方向计算和传播。
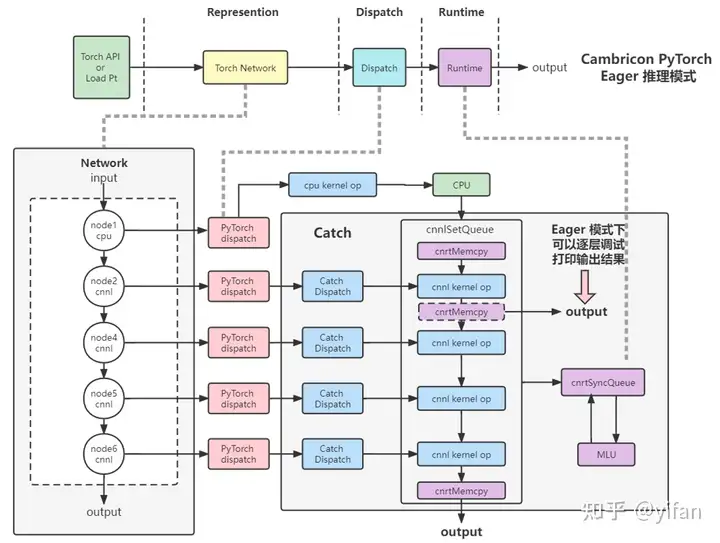
其中:
Eager 模式:使用 CNNL 作为后端,灵活简单易用,可快速逐层调试,支持可变输入,无需量化并可以获得优秀的推理性能。
其他和前面相同。
2)JIT 推理模式
该模式使用MagicMind 加速推理引擎作为后端,包含多种量化模式、多种图优化算法,给用户带来极致推理性能。
首先torch api pt模型经过torch.jit.trace 得到torch 模型
torch 模型经过torch的图优化图融合算法处理后得到如下的ir图,其中图融合算法主要根据MagicMind 算子融合规则,将可以MM融合的节点放在一个 SubGraph 节点中,
接着到了codegen代码生成阶段,该阶段使用 MagicMind Parser、Builder 将 sub-graph 编译成 MLU 硬件设备执行的 Model。
最后是runtime 阶段,使用MagicMind Engine、Context 绑定并启动设备执行推理。
另外,使用调试模式,当图融合不能完全支持的时候,会分发至CNNL/CPU 后端,以调试 MagicMind 不支持的算子。
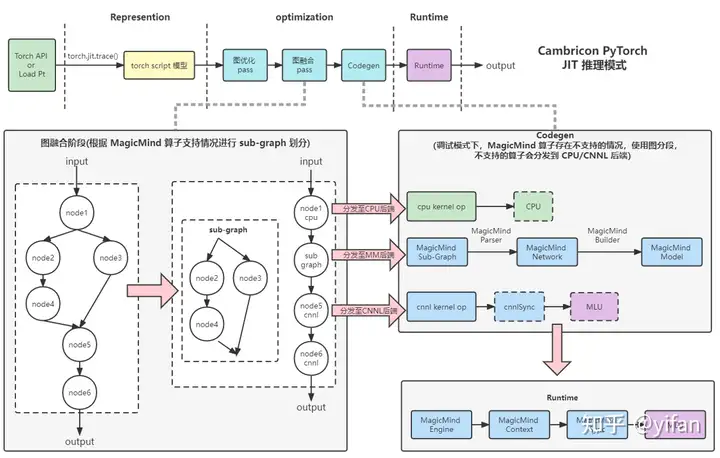
其中:
JIT 模式:使用 MagicMind 加速推理引擎作为后端,包含多种量化模式、多种图优化算法,给用户带来极致推理性能。
图融合:Cambricon PyTorch jit 运行机制中,图融合阶段会根据MagicMind 算子融合规则,将可以融合的节点放在一个 SubGraph 节点中。
Codegen:使用 MagicMind Parser、Builder 将 sub-graph 编译成 MLU 硬件设备执行的 Model。Runtime:使用 MagicMind Engine、Context 绑定并启动设备执行推理。
调试模式:当图融合不能完全支持的时候,会分发至 CNNL/CPU 后端,以调试 MagicMind 不支持的算子。
3、相关问题
Q: Cambricon PyTorch 通过那种方式对原生 PyTorch 进行后端适配?
A: pytorch原生工程中添加 MLU设备的注册,然后将MLU后端代码封装在Aten模块,并利用Pytorch extension 扩展机制 将catch工程patch回pytorch原生工程,这样pytorch算子接口就可以通过torch tensor、aten ops链接mlu后端aten代码;其中catch工程中的mlu后端aten代码是通过对cambricon cntookit 的封装和使用,实现对计算任务分发到cnnl、mm算子,并下发驱动实现计算
Q:Cambricon PyTorch 训推一体架构的后端是如何实现的?
A:使用Cambricon Pytorch 进行训练时,使用cnnl后端,有4种训练模式分别为:量化感知训练、分布式训练、混合精度训练、单机单卡浮点训练。完成训练得到浮点模型,其中训练时mlu不支持的算子也会自动使用cpu进行训练;
使用Cambricon Pytorch 进行推理时,有Eager 模式和 Jit模式,Eager 模式只能使用 float精度进行推理,Jit模式可以选择int量化或者float模式
热门帖子
精华帖子






 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复


 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读