打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
1. 概念
所谓异构计算,是指CPU+ GPU或者CPU+ 其它设备(如FPGA等)协同计算。一般我们的程序,是在CPU上计算。但是,当大量的数据需要计算时,CPU显得力不从心。那么,是否可以找寻其它的方法来解决计算速度呢?那就是异构计算。例如可利用CPU(Central Processing Unit)、GPU(Graphic Processing Unit)、甚至APU(Accelerated Processing Units, CPU与GPU的融合)等计算设备的计算能力从而来提高系统的速度。异构系统越来越普遍,对于支持这种环境的计算而言,也正受到越来越多的关注。
2. 异构计算的实现
目前异构计算使用最多的是利用GPU来加速。主流GPU都采用了统一架构单元,凭借强大的可编程流处理器阵容,GPU在单精度浮点运算方面将CPU远远甩在身后。英特尔Core i7 965处理器,在默认情况下,它的浮点计算能力只有NVIDIA GeForce GTX 280 的1/13,与AMD Radeon HD 4870相比差距就更大。
3.基于GPU编程
不同厂商通常仅仅提供对于自己设备编程的实现。对于异构系统一般很难用同种风格的编程语言来实现机构编程,而且将不同的设备作为统一的计算单元来处理的难度也是非常大的。基于GPU编程的,目前主要有:Nvidia,其提供的GPU编程为CUDA,目前使用的CUDA SDK ; Cambricon 目前使用的是Cambricon NeuWare SDK; 另一个是AMD,其提供的GPU编程为AMD APP (其前身是ATI Stream),目前最新版本 AMD APP 。这几个东东是不兼容的,各自为政。作为软件开发者而言,用CUDA开发的软件只能在NVidia相应的显卡上运行,用AMD APP开发的软件,只能在ATI相应的显卡上运行。Cambricon的芯片 在神经网络推理阶段对网络的加速不论从易用性还是性能上都表现强悍,已经应用于华为海思手机芯片以及众多高新企业服务器后端。作为我国高新企业希望能够扛起中国智造的大旗,在AI芯片这块儿让我国不再受制于人。
4. OpenCL简介
那么有没有可能让他们统一起来,简化编程呢?有,那就是由苹果公司发起并最后被业界认可的OpenCL,目前版本1.2。
开放式计算语言(Open Computing Language:OpenCL),旨在满足这一重要需求。通过定义一套机制,来实现硬件独立的软件开发环境。利用OpenCL可以充分利用设备的并行特性,支持不同级别的并行,并且能有效映射到由CPU,GPU, FPGA(Field-Programmable Gate Array)和将来出现的设备所组成的同构或异构,单设备或多设备的系统。OpenCL定义了运行时, 允许用来管理资源,将不同类型的硬件结合在同种执行环境中,并且很有希望在不久的将来,以更加自然的方式支持动态地平衡计算、功耗和其他资源。
5. DirectCompute简介
作为软件行业的老大—微软在这方面又做了什么呢?微软也没闲着,微软推出DirectCompute,与OpenCL抗衡。DirectCompute集成在DX中,目前版本DX11,其中就包括DirectCompute。由于微软的地位,所以大多数厂商也都支持DirectCompute。
6. GPU计算模型
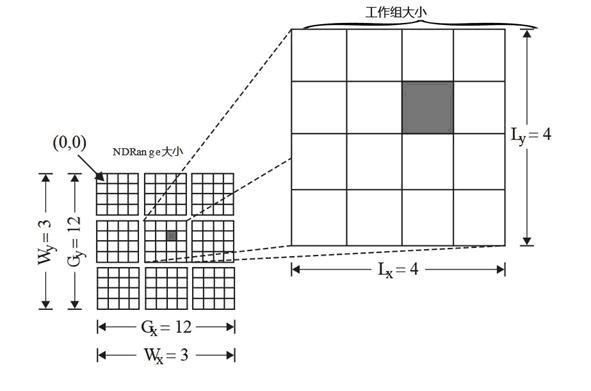
内核是执行模型的核心,能在设备上执行。当一个内核执行之前,需要指定一个 N-维的范围(NDRange)。一个NDRange是一个一维、二维或三维的索引空间。 还需要指定全局工作节点的数目,工作组中节点的数目。如图NDRange所示,全局工作节点的范围为{12, 12},工作组的节点范围为{4, 4},总共有9个工作组。
如果定义向量为1024维,特别地,我们可以定义全局工作节点为1024,工作组中节点为128,则总共有8个组。定义工作组主要是为有些仅需在组内交换数据的程序提供方便。当然工作节点数目的多少要受到设备的限制。如果一个设备有1024个处理节点,则1024维的向量,每个节点计算一次就能完成。而如果一个设备仅有128个处理节点,那么每个节点需要计算8次。合理设置节点数目,工作组数目能提高程序的并行度。
热门帖子
精华帖子





 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读
{kind=link}