打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
文章概述:图像分类任务是计算机视觉(Compute Vision,简称 CV)的一项基本任务,也是入门 CV 领域的基础和关键,本文主要介绍分类图像中的评价指标等。
二分类:就是类别只有2个,如0,1分类;猫狗分类;医学疾病的二分类(注:一般0、neg代表正常/良性;1、pos代表癌症/恶性。)等。
多分类:这个更加常见,比如imageNet的1000分类问题,CIFAR-10的10分类等。
准确率,精确率,召回率,F1-Score, AUC, ROC, P-R曲线等
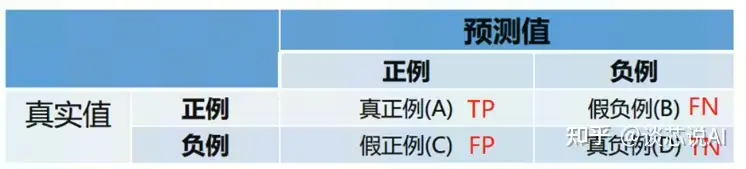
True Positives,TP:预测为正,实际为正,预测为正样本是对的
False Positives,FP:预测为正,实际为负,预测为正样本是错的
True Negatives,TN:预测为负,实际为负,预测为负样本是对的
False Negatives,FN:预测为负,实际为正,预测为负样本是错的
即对于给定的数据,分类正确的样本数占总样本数的比例。
计算公式:
缺陷:准确率这一指标在Unbalanced数据集上的表现很差,因为如果我们的正负样本数目差别很大,比如负样本10个,正样本9990个,那么直接把所有的样本都预测为正, 准确率为99.9 %,但是此分类模型完全无意义。
分类正确的正样本个数占分类器所有的【预测】正样本个数的比例。即以判断为正例作为基准:模型判别为正例的里面,实际正确的概率是多少。
计算公式:
分类正确的正样本个数占实际正样本个数的比例。以真实为正例作为基准:真实值的正例中,被判断出来为正例的概率是多少。
计算公式:
即F值为正确率和召回率的调和平均值,当类别不均衡,它或许是一个比单纯Accuracy更好的指标。
计算公式:
准确率、精确率、召回率 和 F1-score 都是单一的数值指标,如果想观察分类算法在不同的参数下的表现,此时可以使用一条曲线,即 ROC。ROC 曲线可以用评价一个分类器在不同阈值下的表现。横纵坐标均基于真实值为分母:
横坐标是 FPR(False Position Rate):FPN = FP / (FP + TN),表示分类器预测的正类中实际负实例占所有负例的比例,FPR越大,预测正类中的实际负类越多。
纵坐标是TPR(True position Rate):公式同召回率的,TPN = TP / (TP + FN),表示分类器预测的正类中实际正实例占所有正例的比例;
ROC 曲线有四个关键点(如下图):
(0,0)点:FPR=TPR=0,表示分类器预测所有的样本都为负样本;
(1,1)点:FPR=TPR=1,表示分类器预测所有的样本都为正样本;
(0,1)点:FPR=0,TPR=1,此时FN=0且FP=0,表示最优分类器,所有的样本都被正确分类;
(1,0)点:FPR=1,TPR=0,此时TP=0且TN=0,表示最差分类器,有所得样本都被错误分类;
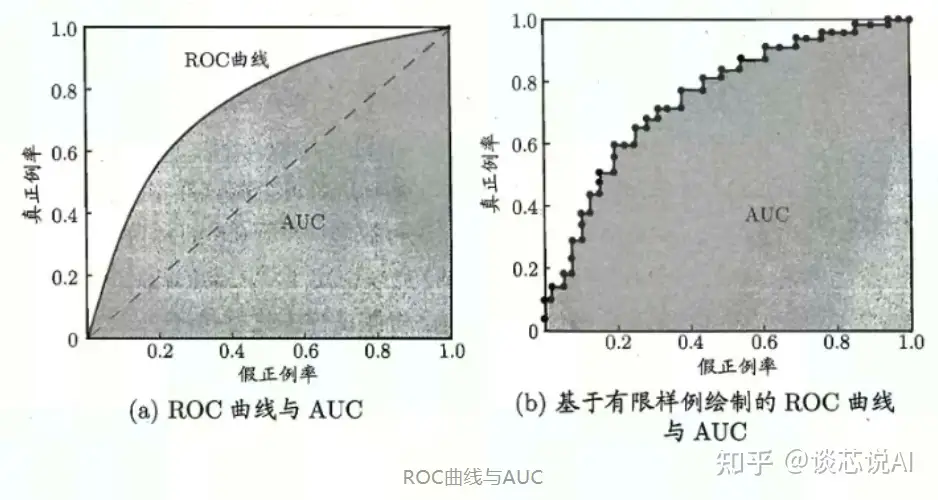
ROC 曲线有一个很好的特征:当测试集中的正负样本比例分布变化时,ROC曲线能够保持不变,即它对正负样本不均衡问题不敏感。所以对不均衡样本问题,通常选择ROC曲线作为评价标准。
ROC 曲线越接近左上角,表示该分类器的性能越好,若一个分类器的ROC曲线完全包住了另一个分类器ROC曲线,那么可以判断前者的性能更好。
AUC为ROC曲线下的面积,这个面积的数值不会大于1。
AUC=1:在任何阈值下分类器都可以 100% 识别所有类别,这是理想的分类器;
AUC=0.5:相当于随机预测,此时分类器不可用;
0.5<AUC<1:优于随机预测,这也是实际作用中大部分分类器所处的状态;
AUC<0.5:总是比随机预测更差;
AUC 作为一个评价标准,常和 ROC 曲线一起使用,可以看作是ROC的量化表现。
以查准率(Precision)为纵轴、查全率(Recall)为横轴作图 ,就得到了查准率-查全率曲线,简称 "P-R曲线"。
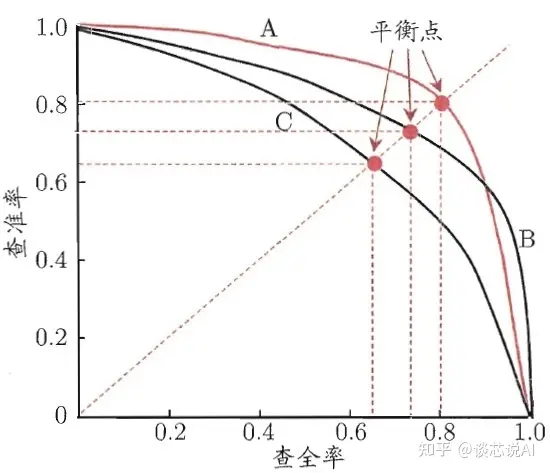
优劣比较:
若一PR曲线完全“包住”,可以断言后者的性能优于前者,像上图中学习器A的性能就优于学习器C;
若是两个学习器的PR曲线发生交叉,像A和B,就比较难断言孰优孰劣,只能是在具体的查准率或查全率条件进行比较。这里引入平衡点(Break-Even Point,BEP)的概念,就是那么一个综合考虑查准率和查全率的性能度量,它是“查准率=查全率”时的取值,基于BEP进行比较,我们可以认为学习器A要比B好。
就是Precision-Recall 曲线下围成的面积,通常来说一个越好的分类器,AP值越高。而mAP(mean average precision)是多个类别AP的平均值。
如果我们想知道类别之间相互误分的情况,查看是否有特定的类别相互混淆,就可以用混淆矩阵画出分类的详细预测结果。对于包含多个类别的任务,混淆矩阵很清晰地反映了各类别之间的错分概率。
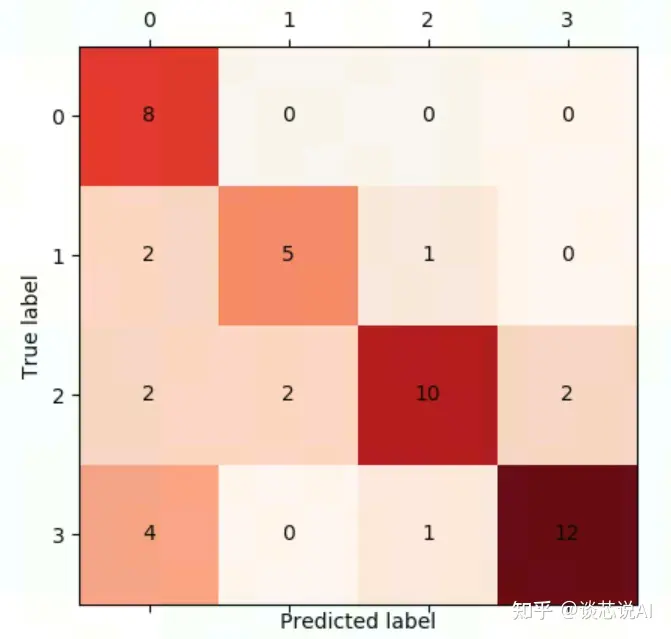
该图可用代码中的tools confusion_matrix_test.py 运行得到。
热门帖子
精华帖子





 Ashelly
13 回复
Ashelly
13 回复
 fengyunkai
1 回复
fengyunkai
1 回复
 三叶虫
3 回复
三叶虫
3 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读