打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
1. 寒武纪推出BANG语言及其工具链
寒武纪编译团队推出了BANG编程语言及其工具链,优化了寒武纪芯片的通用编程能力并提升了用户编程的自由度。用户不仅可以直接使用BANG语言编写AI程序,而且能使用BANG语言和寒武纪高性能库进行混合编程来最大限度的释放芯片的强大算力。BANG语言专门针对寒武纪智能处理器产品架构而设计,能够支持寒武纪现有的各种云端、边缘侧和终端的芯片和板卡(如思元100、思元220、思元270、IP产品等),并将支持后续新的产品架构。
BANG语言支持最常用的C99和C++11语言的语法特性,并提供了用于编写高性能程序的内置Intrinsic接口。开发者能够依托寒武纪强大的编译工具链,在编程灵活的同时最大程度地利用寒武纪智能处理器产品上的计算和存储资源,确保程序的高性能。此外,BANG语言还具备以下关键特性:
(1)内置寒武纪智能处理器产品硬件相关的类型系统;
(2)支持开发者构建自定义算法模型;
(3)提供统一高效的编程接口,充分发挥寒武纪产品的硬件特性;
(4)提供异构编程模型;
(5)提供多核并行编程模型;
(6)能够与寒武纪高性能库进行混合编程;
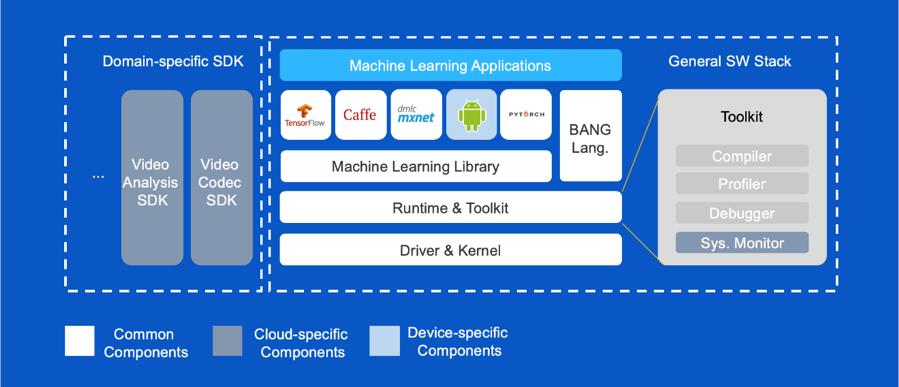
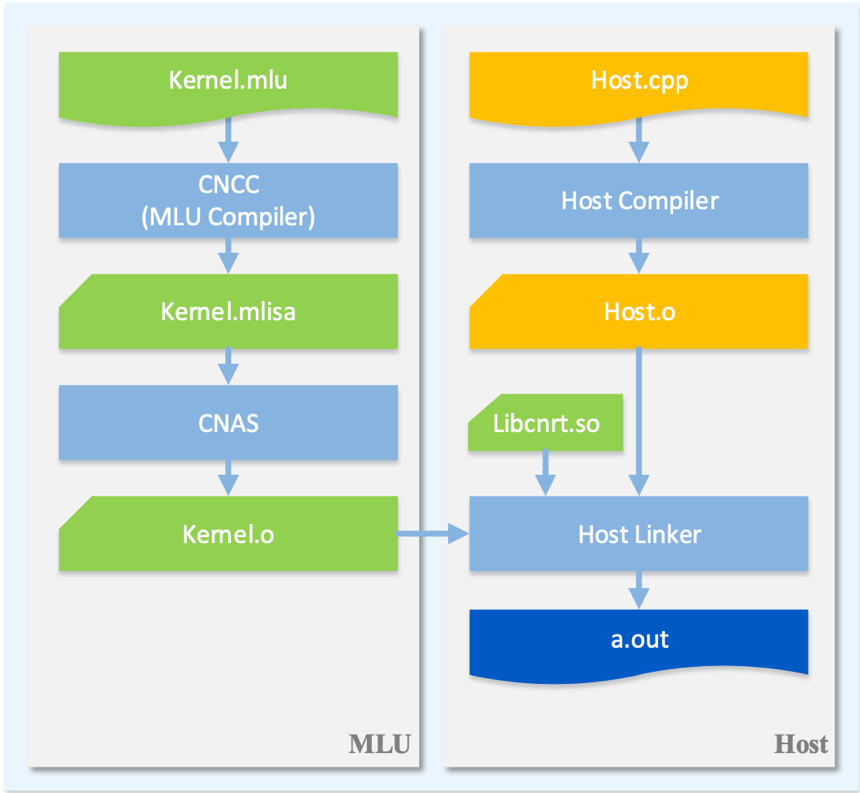
寒武纪编译团队自研了编译工具链,极大地提高BANG语言的运行性能。编译工具链包括CNCC(Cambricon Neuware Compiler Collection )、CNAS(Cambricon Neuware Assembler)、CNLINKER(Cambricon Neuware Linker)。工具链中的CNCC负责处理编译前端工作,将BANG 语言编译成中间语言MLISA。CNAS主要负责将中间语言MLISA编译为包含MLU (Machine Learning Unit) 机器指令的目标文件,最后由CNLINKER将目标文件链接成可执行程序。编译工具链使用简单,编译命令和GNU-GCC类似,使用命令行进行编译。BANG语言和编译工具链互相协作,可充分发挥寒武纪芯片的强大算力,具体协作流程如下图所示:
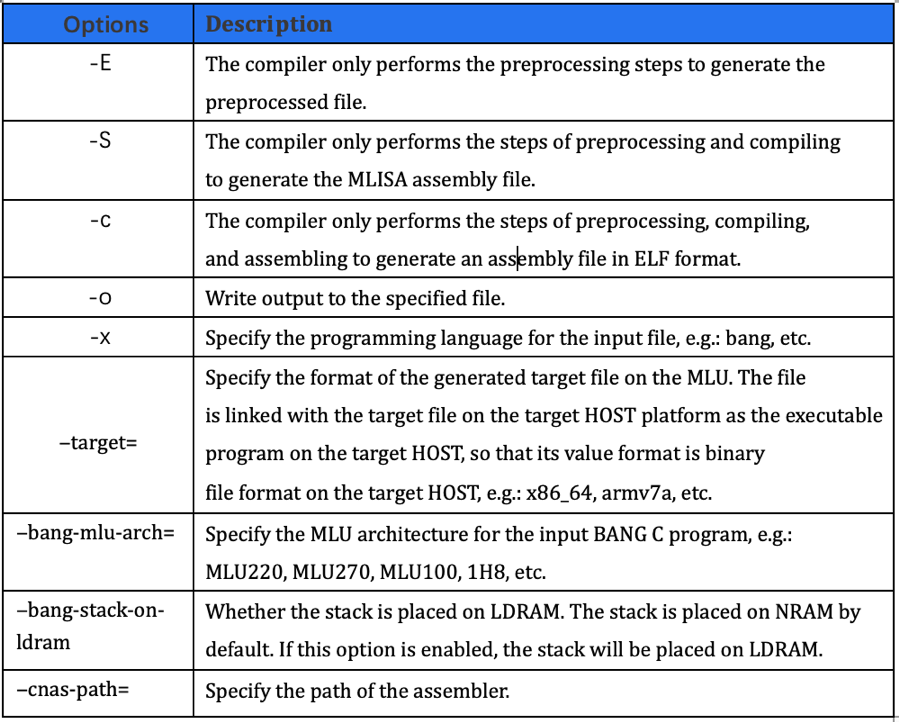
为了提升应用程序性能,寒武纪优化编译器实现了包括自动软件流水、全新的寄存器分配算法、全局指令调度、精确的程序依赖分析、Profiling Guided Optimization、地址指针推理及优化、以及数据类型(如半精度浮点数)计算优化等在内的大量优化工作。CNCC的通用编译选项如下图所示:
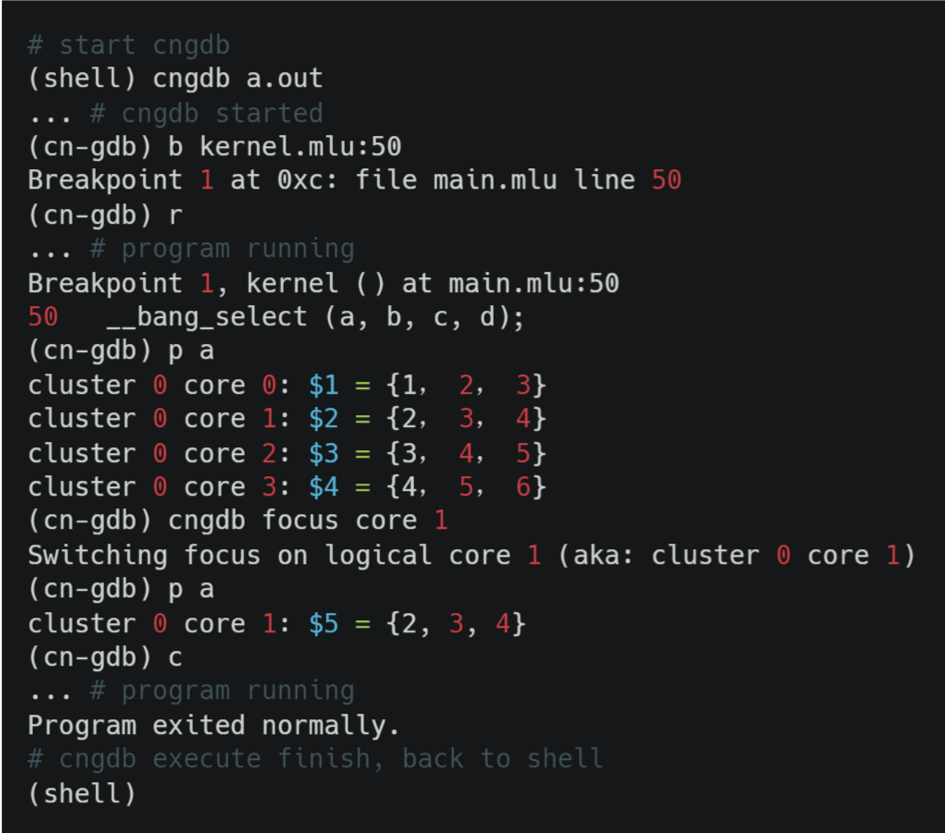
此外,为了便利寒武纪芯片的调试工作,提升开发效率,寒武纪编译器团队开源了CNGDB(Cambricon Neuware GDB )。CNGDB是Linux系统上调试BANG语言程序的工具,基于GNU的调试器GDB开发,能支持GNU GDB在CPU上原有的全部操作,使用它可以在真实的硬件上同时调试寒武纪硬件产品的设备侧和主机侧的代码。同时,它可以支持控制程序执行和访问变量等多种操作、多核调试模式、CPU/Device调试的透明切换以及生成CNML内核的错误信息,解决了开发者难以调试的问题,极大地提升了程序开发效率。
CNGDB的主要特性如下:
(1) 支持GNU-GDB在CPU上原有的全部操作。
(2) 支持硬件设备上GDB的大部分操作,包括断点、单步、访问修改变量等。
(3) 支持灵活的多核调试模式。
(4) 支持思元270(MLU270)及以上硬件的调试。
(5 )CPU/Device的调试切换过程对用户透明
(6)支持生成CNML内核的错误信息。
BANG C编程接口简单,编程规范易懂,编程方式与C/C++类似,它的Intrinsic函数集成了多种复杂的计算指令,开发者能够依托寒武纪强大的编译工具链,在编程灵活的同时最大程度地利用寒武纪智能处理器产品上的计算和存储资源,确保了程序的高性能。BANG C为寒武纪软硬件生态环境建设提供强有力的支撑。在实际开发过程中,相对于原生C/C++,使用BANG C进行编程,仅需要1/10的开发时间就能达到85%的极致性能。随着CNCC的持续优化,性能将会进一步大幅度提升。
2. BANG语言使用入门示例
(1)安装相应的CNCC&CNAS软件包
(2)编写BANG语言代码kernel.mlu
#include "macro.h"
#include "mlu.h"
__mlu_entry__ void ConvKernel(half* out_data, half* in_data, half* filter_data,
int in_channel, int in_height, int in_width,
int stride_height, int stride_width,
int out_channel) {
__nram__ half nram_out_data[OUT_DATA_NUM];
__nram__ half nram_in_data[OUT_DATA_NUM];
__wram__ half wram_filter[FILTER_DATA_NUM];
__memcpy(nram_in_data, in_data, IN_DATA_NUM * sizeof(half),GDRAM2NRAM);
__memcpy(wram_filter, filter_data, FILTER_DATA_NUM * sizeof(half),GDRAM2WRAM);
__bang_conv(nram_out_data, nram_in_data, wram_filter, in_channel,
IN_HEIGHT, IN_WIDTH, filter_height, filter_width, stride_height,
stride_width, out_channel);
__memcpy(out_data, nram_out_data, OUT_DATA_NUM * sizeof(half),NRAM2GDRAM);
}
(3)编写相应的Host代码main.c
#include “cnrt.h”
extern void ConvKernel(half* out_data, half* in_data,
half* filter_data, int in_channel,
int in_height, int in_width,
int stride_height, int stride_width,
int out_channel);
int main() {
// 1. Initialize MLU device.
cnrtInit(0);
// 2. Prepare CPU data and MLU data.
for (int k = 0; k < N; k++) { cpu_data[k] = (float)(rand() % 20); }
// 3. Malloc On-Device memory space.
half * mlu_data = NULL;
cnrtMalloc((void**)&mlu_data, N * sizeof(half));
// 4. Copy data to MLU DDR memory space.
cnrtMemcpy(mlu_data, cpu_data, N * sizeof(half));
// 5. Invoke kernel.
cnrtKernelParamsBuffer_t params;
cnrtGetKernelParamsBuffer(¶m);
uint32_t size = N;
cnrtKernelParamsBufferAddParam(params, &size, sizeof(size)));
cnrtKernelParamsBufferAddParam(params, mlu_data,
sizeof(half*));
cnrtInvokeKernel((void*)&ConvKernel, params));
// 6. Get the result of running the mlu kernel.
half cpu_result[N];
cnrtMemcpy(cpu_result, mlu_data, N * sizeof(half));
// 7. Free MLU memory.
cnrtFree(mlu_data);
return 0;
}
(4) 编译执行
cncc conv_kernel.mlu -c -o conv_kernel.o
gcc main.c conv_kernel.o -lcnrt -o main.exe
./main.exe
3. CNGDB使用示例
热门帖子
精华帖子







 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复

 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读