打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
老师 你好之前问题已经解决了,现在我们尝试调用该接口
detect_out = torch.ops.torch_mlu.mlunmsthresh(score.to(ct.mlu_device()),80,8400)
会报以下错误
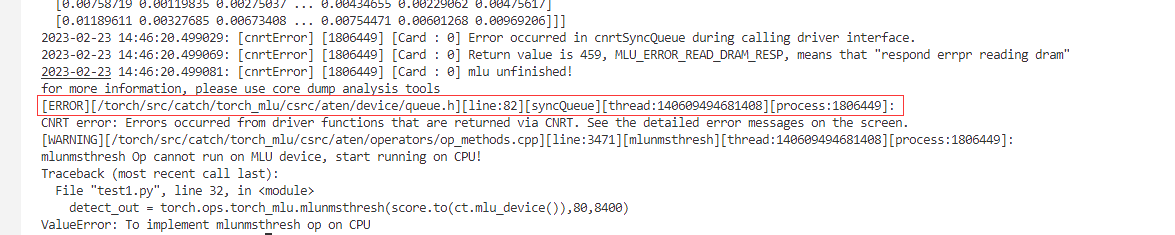
根据提示是计算队列出错(syncQueue),可是提示中没有任何线索指向我写的代码问题,也没有思路发现问题希望老师们能帮忙看看
唯一使用到
syncQueue(queue)就是在mlunmsthresh_internal.cpp中
cnmlComputePluginPpyoloenmsOpForward
具体代码如下
#include "aten/operators/cnml/cnml_kernel.h"
namespace torch_mlu
{
namespace cnml
{
namespace ops
{
std::tuple<at::Tensor, at::Tensor> cnml_mlunmsthresh_internal(const at::Tensor & source,int64_t num_classes, int64_t num_anchors)
{
int numclass=num_classes;
int numanchor=num_anchors;
cnmlTensor_t cnml_input_ptr[1];
cnmlTensor_t cnml_output_ptr[3];
// prepare input cnml tensor
auto *source_impl = getMluTensorImpl(source);
auto source_cnml = source_impl->CreateCnmlTensor(CNML_TENSOR,
toCnmlDataType(source.dtype()));
// prepare out cnml tensor
// auto output_options =
// at::TensorOptions(c10::ScalarType::Half).device(at::DeviceType::MLU);
// auto output_bbox = at::empty({batch_size * nms_num, 4, 1, 1}, output_options);
// auto* output_bbox_impl = getMluTensorImpl(output_bbox);
// auto output_bbox_cnml =
// output_bbox_impl->CreateCnmlTensor(CNML_TENSOR, CNML_DATA_FLOAT16);
// auto* tmp_impl = getMluTensorImpl(tmp);
// auto tmp_cnml = tmp_impl->CreateCnmlTensor(CNML_TENSOR, CNML_DATA_FLOAT16);
//#CNML_DATA_INT32
auto output_options =
at::TensorOptions(c10::ScalarType::Half).device(at::DeviceType::MLU);
auto output_options1 =
at::TensorOptions(c10::ScalarType::Int).device(at::DeviceType::MLU);
auto output1 =at::empty({8400, 1},output_options1);
auto *output1_impl = getMluTensorImpl(output1);
auto output1_cnml = output1_impl->CreateCnmlTensor(CNML_TENSOR,
CNML_DATA_INT32);
auto output2 = at::empty({8400, 2}, output_options);
auto* output2_impl = getMluTensorImpl(output2);
auto output2_cnml = output2_impl->CreateCnmlTensor(
CNML_TENSOR,CNML_DATA_FLOAT16);
auto output3 = at::empty({16, 2}, output_options1);
auto* output3_impl = getMluTensorImpl(output3);
auto output3_cnml = output3_impl->CreateCnmlTensor(
CNML_TENSOR,CNML_DATA_INT32);
// End the execution flow if not MLU device
CHECK_MLU_DEVICE(std::make_tuple(output1, output2));
cnml_input_ptr[0] = source_cnml;
cnml_output_ptr[0] = output1_cnml;
cnml_output_ptr[1] = output2_cnml;
cnml_output_ptr[2] = output3_cnml;
cnmlPluginPpYoloenmsOpParam_t param;
cnmlCreatePluginPpyoloenmsOpParam(¶m,numclass,numanchor);
cnml Op_t op;
TORCH_CNML_CHECK(cnmlCreatePluginPpyoloenmsOp(&op,param,cnml_input_ptr,cnml_output_ptr));
// return to JIT if running mode is fuse
CHECK_RETURN_TO_FUSE(op, std::make_tuple(output1, output2));
// get queue and func_param
cnrtInvokeFuncParam_t func_param;
static u32_t affinity = 0x01;
int data_parallelism = 1;
func_param.affinity = &affinity;
func_param.data_parallelism = &data_parallelism;
func_param.end = CNRT_PARAM_END;
auto queue = getCurQueue();
// compile all ops
TORCH_CNML_CHECK(cnmlCompile Op(op,GET_CORE_VERSION,GET_CORE_NUMBER));
void *input_addrs[1];
void *output_addrs[3];
input_addrs[0] = source_impl->raw_mutable_data();
output_addrs[0] = output1_impl->raw_mutable_data();
output_addrs[1] = output2_impl->raw_mutable_data();
output_addrs[2] = output3_impl->raw_mutable_data();
// compute operator
TORCH_CNML_CHECK(cnmlComputePluginPpyoloenmsOpForward(op,
input_addrs,
1,
output_addrs,
3,
&func_param,
queue));
syncQueue(queue);
TORCH_CNML_CHECK(cnmlDestroyPluginPpyoloenmsOpParam(¶m));
TORCH_CNML_CHECK(cnmlDestroy Op(&op));
return std::make_tuple(output1, output2);
}
} // namespace ops
} // namespace cnml
} // namespace torch_mlu
热门帖子
精华帖子





 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读