打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
生成离线模型是寒武纪软件栈中比较重要的一个特性部分。通过离线模型可以减轻用户在部署时的运行和开发成本,获得更高的性能。最近我学习了cambricon caffe配套的离线模型运行程序。这里以分类网络的记录一下学习笔记。
编译:
caffe的离线模型运行example会随着编译caffe一起编译出来。只要执行caffe的编译脚本就可以得到可运行的二进制文件。
运行:
我们可以选择使用cambricon caffe提供的运行脚本可以手动执行二进制文件。例如下面这样:
../build/examples/clas_offline_multicore/clas_offline_multicore -offlinemodel resnet50_intx_16_16.cambricon -images file_list_for_release -labels synset_words.txt
这中间 -offlinemodel 表示传入的离线模型文件位置。 -images 需要传入一个文件列表。-labels 转入类别编号对应的label。其中文件列表文件有专门的格式要求。例如下面的形式:
../imagenet/988.jpg 824
../imagenet/989.jpg 124
../imagenet/990.jpg 119
../imagenet/991.jpg 138
../imagenet/992.jpg 746
../imagenet/993.jpg 162
../imagenet/994.jpg 572
../imagenet/995.jpg 807
../imagenet/996.jpg 101
../imagenet/997.jpg 739
../imagenet/998.jpg 836
../imagenet/999.jpg 603
这里前面是完整的文件路径,后面是图片对应的类别编号。
以上程序在运行后会输出完整的图像分类结果,运行时间等信息。例如:
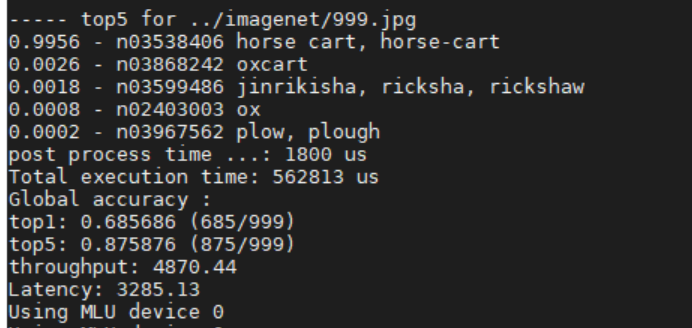
代码结构:
多种需求的离线模型运行都可以使用相关的example来完成。结构上看,这套代码把任务分解为前处理,推理运行,后处理三个部分。这意味着不论是分类任务,还是检测或其他深度学习推理任务。我们都可以使用这套架构来完成。而这套架构的优势就是可以自动的把前处理,运行,后处理这些相对独立的子任务并行化,使用流水线的方式运行整个任务,从而提高整体的吞吐效率。
关于流水线:“流水线,亦称管线,是现代计算机处理器中必不可少的部分,是指将计算机指令处理过程拆分为多个步骤,并通过多个硬件处理单元并行执行来加快指令执行速度。其具体执行过程类似工厂中的流水线,并因此得名。” 转自维基百科 https://zh.wikipedia.org/wiki/%E6%B5%81%E6%B0%B4%E7%BA%BF_(%E8%AE%A1%E7%AE%97%E6%9C%BA)
更具体的,对于分类任务来说,整个任务有如下几个部分:
1. 载入离线模型并完成初始化(一次性完成)
2. 载入图片并将图片数据拷贝至MLU。
3. 运行推理。
4. 将数据从MLU拷出并统计精度数据。
5. 销毁相关资源。(一次性完成)
不难看出,其中三步可以流水线的方式并行执行。具体的有如下模块:
1. OffDataProviderT;
2. OffRunnerT;
3. ClassOffPostProcessorT;
4. PipelineT;
在声明PipelineT的时候通过构造函数传入 DataProvider,Runner,ClassOffPostProcessor的实例从而完成绑定。其中最重要的是这几个模块之间的数据通讯。这些通讯通过BlockingQueue完成。BlockQueue的具体实现在common/blocking_queue.cpp。这里通过boost的线程锁实现了一个可阻塞队列的push,pop,sync等操作。具体的原理这里不再赘述。
OffDataProviderT定义在common/off_data_provider.cpp。主要完成了读入图片并把图片mencpy到MLU的过程。在程序运行开始的时候会调用allocateMemory分配所有的内存空间,并把分类好的MLU内存指针放入一个vector中。在每次需要往MLU上拷贝数据的时候调用runner->popFreeInputData();来获取空闲的空间地址。更具体的图片读入通过readOneBatch函数(common/data_provider.cpp)调用一系列的opencv api完成。
在Runner中定义了两种运行方式。一种是从队列中通过线程锁pop元素进行推理,另一种则是使用乒乓法(https://en.wikipedia.org/wiki/Ping-pong_scheme)的实现。使用队列的方式比较简单,唯一要注意的是在推理结束之后要插入一个cnrtSyncQueue从而得到正确的MLU运行时间。
ClassOffPostProcessor的实现原理和其他模块类似。具体任务要完成将数据从MLU 拷贝到CPU的过程。并且比对分类结果,并统计top1,top5。
热门帖子
精华帖子






 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复


 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读