打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
在用16*5*5的全1的src与1*2*2*16的全1的kernel进行测试时发现mlu返回的结果错误,与仅取kernel的对应通道的第一个值做kernel shape为C_i*1*1*C_o的结果一致。测试了调用int16_t dst, int8_t src, int8_t kernel的__bang_conv与均为float的___bang_conv,结果都是一样的。上面为正常结果
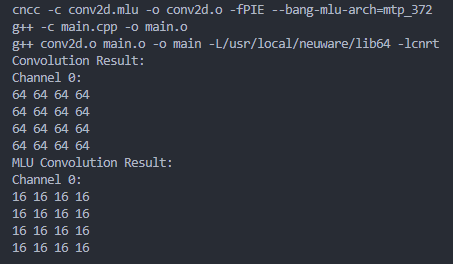
代码:
// conv2d.mlu
#include <bang.h>
#include <iostream>
#include <assert.h>
#define EPS 1e-7
#define MAX_KERNEL 1024
#define MAX_LEN 1024
// __BANG_ARCH__ = 372
__mlu_entry__ static void Kernel(int16_t *dst, const int8_t *src, const int8_t *kernel, unsigned int channel_input, unsigned int height, unsigned int width, unsigned int kernel_height, unsigned int kernel_width, unsigned int stride_width, unsigned int stride_height, unsigned int channel_output) {
__nram__ int16_t nram_dst_h[MAX_LEN];
__nram__ int8_t nram_src_h[MAX_LEN];
__wram__ int8_t wram_kernel_h[MAX_KERNEL];
__memcpy(nram_src_h, src, channel_input * height * width * sizeof(int8_t), GDRAM2NRAM);
__memcpy(wram_kernel_h, kernel, MAX_LEN, GDRAM2WRAM);
unsigned int output_height = (height - kernel_height) / stride_height + 1;
unsigned int output_width = (width - kernel_width) / stride_width + 1;
__bang_conv(nram_dst_h, nram_src_h, wram_kernel_h, channel_input, height, width, kernel_height, kernel_width, stride_width, stride_height, channel_output, 0);
__memcpy(dst, nram_dst_h, channel_output * output_height * output_width * sizeof(int16_t), NRAM2GDRAM);
}
void mlu_conv(int16_t *dst, int8_t *src, int8_t *kernel, unsigned int channel_input, unsigned int height, unsigned int width, unsigned int kernel_height, unsigned int kernel_width, unsigned int stride_width, unsigned int stride_height, unsigned int channel_output)
{
cnrtQueue_t queue;
CNRT_CHECK(cnrtSetDevice(0));
CNRT_CHECK(cnrtQueueCreate(&queue));
cnrtDim3_t dim = {1, 1, 1};
cnrtFunctionType_t ktype = CNRT_FUNC_TYPE_BLOCK;
cnrtNotifier_t start, end;
CNRT_CHECK(cnrtNotifierCreate(&start));
CNRT_CHECK(cnrtNotifierCreate(&end));
int8_t *mlu_src, *mlu_ker;
int16_t *mlu_dst;
unsigned int output_height = (height - kernel_height) / stride_height + 1;
unsigned int output_width = (width - kernel_width) / stride_width + 1;
CNRT_CHECK(cnrtMalloc((void **)&mlu_dst, channel_output * output_height * output_width * sizeof(int16_t)));
CNRT_CHECK(cnrtMalloc((void **)&mlu_src, channel_input * height * width * sizeof(int8_t)));
CNRT_CHECK(cnrtMalloc((void **)&mlu_ker, channel_input * channel_output * kernel_height * kernel_width * sizeof(int8_t)));
CNRT_CHECK(cnrtMemcpy(mlu_src, src, channel_input * height * width * sizeof(int8_t), cnrtMemcpyHostToDev));
CNRT_CHECK(cnrtMemcpy(mlu_ker, kernel, channel_input * channel_output * kernel_height * kernel_width * sizeof(int8_t), cnrtMemcpyHostToDev));
CNRT_CHECK(cnrtPlaceNotifier(start, queue));
Kernel<<<dim, ktype, queue>>>(mlu_dst, mlu_src, mlu_ker, channel_input, height, width, kernel_height, kernel_width, stride_width, stride_height, channel_output);
CNRT_CHECK(cnrtPlaceNotifier(end, queue));
cnrtQueueSync(queue);
CNRT_CHECK(cnrtMemcpy(dst, mlu_dst, channel_output * output_height * output_width * sizeof(int16_t), cnrtMemcpyDevToHost));
CNRT_CHECK(cnrtQueueDestroy(queue));
cnrtFree(mlu_dst);
cnrtFree(mlu_src);
cnrtFree(mlu_ker);
}// main.cpp
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
#include <cmath>
void conv(int16_t *dst, int8_t *src, int8_t *kernel, unsigned int channel_input, unsigned int height, unsigned int width, unsigned int kernel_height, unsigned int kernel_width, unsigned int stride_width, unsigned int stride_height, unsigned int channel_output) {
// 计算输出特征图的尺寸
unsigned int output_height = (height - kernel_height) / stride_height + 1;
unsigned int output_width = (width - kernel_width) / stride_width + 1;
// 对每个输出通道进行循环
for (unsigned int output_channel = 0; output_channel < channel_output; ++output_channel) {
// 对输出特征图的每个像素进行循环
for (unsigned int output_y = 0; output_y < output_height; ++output_y) {
for (unsigned int output_x = 0; output_x < output_width; ++output_x) {
// 初始化输出像素值
int8_t output_pixel = 0.0f;
// 对输入通道进行循环
for (unsigned int input_channel = 0; input_channel < channel_input; ++input_channel) {
// 对卷积核的每个元素进行循环
for (unsigned int ky = 0; ky < kernel_height; ++ky) {
for (unsigned int kx = 0; kx < kernel_width; ++kx) {
// 计算输入像素坐标
unsigned int input_x = output_x * stride_width + kx;
unsigned int input_y = output_y * stride_height + ky;
// 计算卷积操作
output_pixel += src[input_channel * (height * width) + input_y * width + input_x] * kernel[output_channel * (channel_input * kernel_height * kernel_width) + input_channel * (kernel_height * kernel_width) + ky * kernel_width + kx];
}
}
}
// 将结果存储在目标数组中
dst[output_channel * (output_height * output_width) + output_y * output_width + output_x] = output_pixel;
}
}
}
}
void mlu_conv(int16_t *dst, int8_t *src, int8_t *kernel, unsigned int channel_input, unsigned int height, unsigned int width, unsigned int kernel_height, unsigned int kernel_width, unsigned int stride_width, unsigned int stride_height, unsigned int channel_output);
int main() {
// 定义输入数据和卷积核
unsigned int channel_input = 16; // 输入通道数
unsigned int height = 5; // 输入高度
unsigned int width = 5; // 输入宽度
unsigned int kernel_height = 2; // 卷积核高度
unsigned int kernel_width = 2; // 卷积核宽度
unsigned int stride_width = 1; // 横向步长
unsigned int stride_height = 1; // 纵向步长
unsigned int channel_output = 1; // 输出通道数
// 创建输入数据和卷积核数组(这里只是示例数据)
int8_t src[5][5][16];
for (int h = 0; h < height; h++) {
for (int w = 0; w < width; w++) {
for (int c = 0; c < channel_input; c++) {
src[h][w][c] = 1;
}
}
}
int8_t kernel[2][2][16];
for (int h = 0; h < height; h++) {
for (int w = 0; w < width; w++) {
for (int c = 0; c < channel_input; c++) {
kernel[h][w][c] = 1;
}
}
}
unsigned int output_height = (height - kernel_height) / stride_height + 1;
unsigned int output_width = (width - kernel_width) / stride_width + 1;
int16_t dst[channel_output * output_height * output_width];
conv((int16_t *)dst, (int8_t *)src, (int8_t *)kernel, channel_input, height, width, kernel_height, kernel_width, stride_width, stride_height, channel_output);
// 打印卷积结果(这里只是示例,实际应用中需要根据结果进行后续处理)
std::cout << "Convolution Result:" << std::endl;
for (unsigned int output_channel = 0; output_channel < channel_output; ++output_channel) {
std::cout << "Channel " << output_channel << ":" << std::endl;
for (unsigned int output_y = 0; output_y < output_height; ++output_y) {
for (unsigned int output_x = 0; output_x < output_width; ++output_x) {
std::cout << dst[output_channel * (output_height * output_width) + output_y * output_width + output_x] << " ";
}
std::cout << std::endl;
}
}
printf("begin mlu_conv");
mlu_conv((int16_t *)dst, (int8_t *)src, (int8_t *)kernel, channel_input, height, width, kernel_height, kernel_width, stride_width, stride_height, channel_output);
std::cout << "MLU Convolution Result:" << std::endl;
for (unsigned int output_channel = 0; output_channel < channel_output; ++output_channel) {
std::cout << "Channel " << output_channel << ":" << std::endl;
for (unsigned int output_y = 0; output_y < output_height; ++output_y) {
for (unsigned int output_x = 0; output_x < output_width; ++output_x) {
std::cout << dst[output_channel * (output_height * output_width) + output_y * output_width + output_x] << " ";
}
std::cout << std::endl;
}
}
return 0;
}热门帖子
精华帖子





 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读