打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
【CN-Tools01】CNPerf 的使用
https://zhuanlan.zhihu.com/p/608616546
若是初学者,建议先看以上相关部分。
CNPerf( Cambricon Performance )是一款面向 BANG 异构并行编程模型的性能剖析工具,可以用于主机侧与设备侧的并行度调优,也可以用于单kernel的调优。
主机侧与设备侧并行度调优,即端到端调优:
主机侧与设备侧的并行性分析:利用 CNPerf获取主机侧与设备侧的执行流
设备侧单算子并行性分析:利用 CNPerf获取设备的 PMU 性能数据,进而分析算子的性能瓶颈。
硬件要求:
CPU: Intel i5-4570 或 AMD 同等配置以上
Memory: 8GB 或以上
安装方法:
CNPerf的安装依赖于寒武纪 CNDev和 CNPAPI。
用户安装 CNToolkit软件包即可完成 CNDev、 CNPerf和 CNPAPI 的安装: apt-get install cntoolkit-cloud
CNPerf命令行支持以下命令:$ cnperf-cli –h
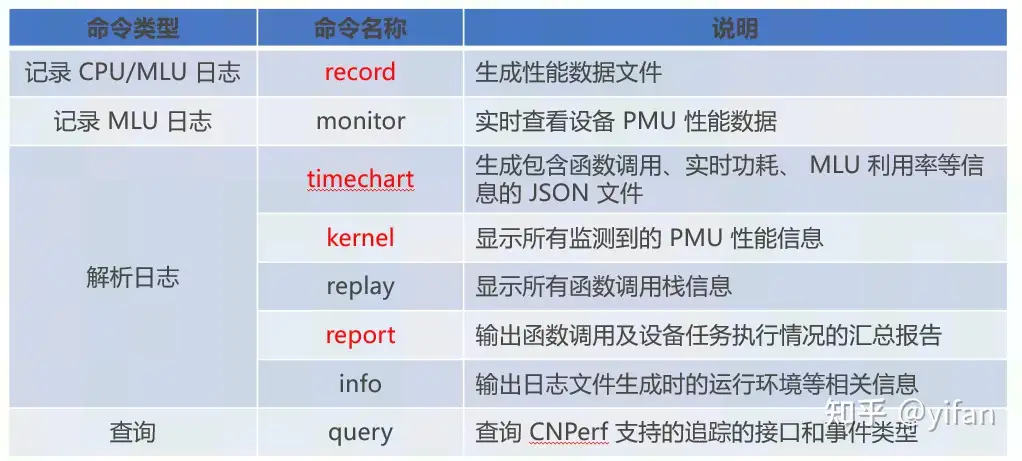
CNPerf常用命令参数介绍:$ cnperf-cli [命令名称] –h
使用方法:cnperf-cli record [options] <program> [program-options]
参数说明:
-c <card id>:设置要获取信息的设备号[-1~ device_num -1]
-o <path>:设置日志文件存储路径,默认是当前目录
--pmu:设置追踪 Kernel 执行时设备侧 PMU 性能数据
--config <file path>: 指定描述追踪事件的配置文件
使用方法:cnperf-cli timechart [options]
参数说明:
-i <path>: 指定跟踪日志的路径
--duration:指定一段时间范围内的数据写入输出文件
-t <time:ms>: 设置时间间隔,将输出文件分割成多个
生成日志文件:$ cnperf-cli record ./xxx.bin [arg1 arg2]
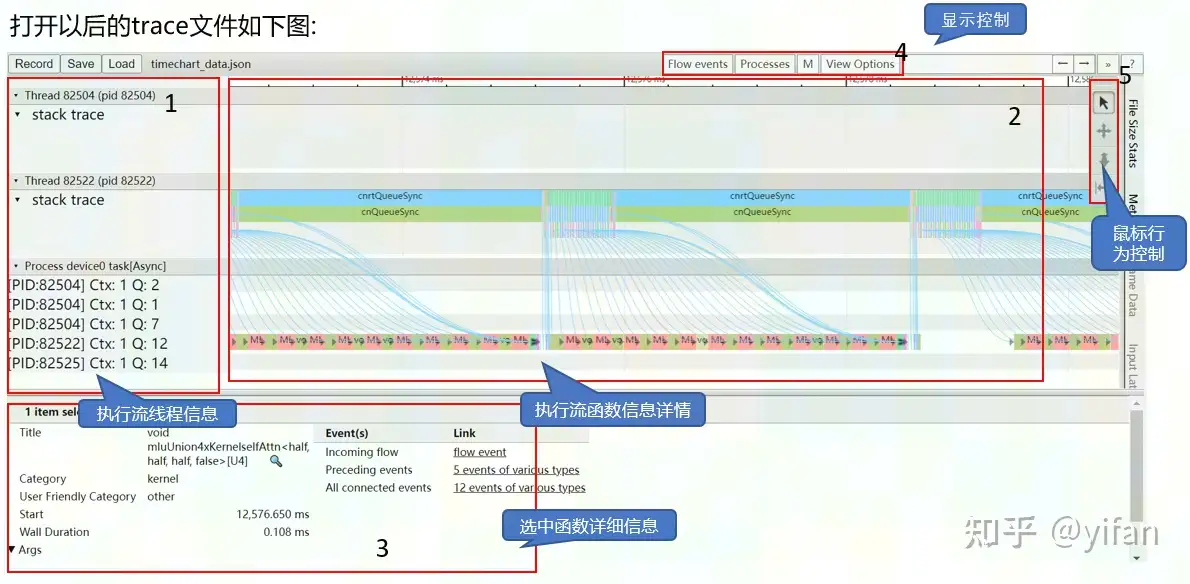
生成 json文件:$ cnperf-cli timechart
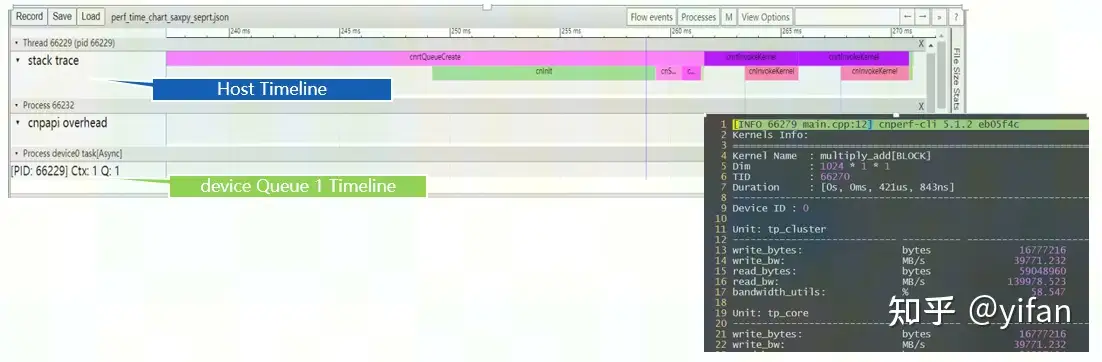
使用 chrome://tracing 打开 timechart生成的 json文件
根据BANG性能分析的add执行如下:
cnperf-cli record addcnperf-cli timechart
根据上面步骤3,可以看看执行情况。具体可见文档。
1)Kernel Queue 中的热点算子
寻找kernel queue中的热点算子的方法:
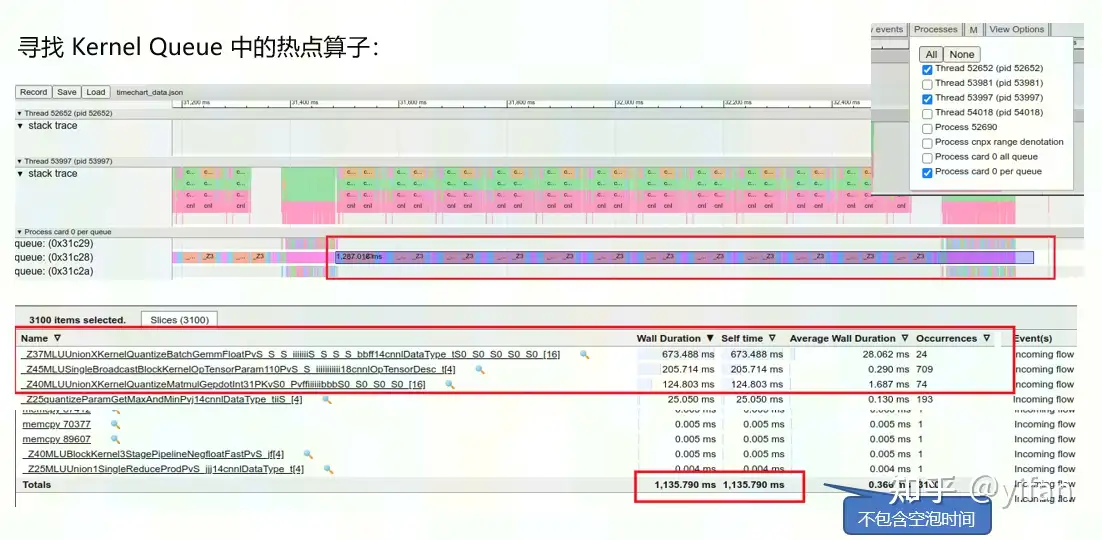
通过右上角的process反选掉跟我们调试没关系的几个线程,让图形更加简洁直观。
通过缩放调整到第二次迭代附近。在选择模式下,在空白处按住鼠标左键可以拉出一个选择框,我们将设备侧执行流中的所有kernel都框进去(queue 0x31c28那一行)。注意框的时候不要包含无关的queue里的事件。
选定后下面的对话框会给出这一段的汇总信息,从汇总信息中可以看到所有算子的总时间(Wall duration)、平均时间(average wall duration)以及出现次数(occurences)。
点击“Wall Duration”, 按照总时间排序。可以很明显的看到, TOP3的3个kernel 的总执行时间占比已经占到了总体硬件时间的88.4%。 属于明显的热点算子。针对热点算子去做优化,可以获得显著的性能收益
注意,这里的total time是所有算子的硬件时间,不包含空泡的时间。
2)Kernel Queue 中的空泡,即算子与算子之间的空白
设备侧空泡产生的原因:
Device 侧 Kernel 较小,执行时间小于 Host 侧下发 Kernel 所需的时间
Host 侧由于执行上有依赖,造成下发 Kernel 有延迟,导致 Device 侧执行延迟
原因1的应对方案:
尝试调整单个 Kernel 的运算规模,例如调整 Batch Size
尝试融合多个小Kernel 为一个大 Kernel
原因2的应对方案:
应当具体分析 Host 线程空泡处的程序行为,尽可能优化影响任务下发的操作
同样更具上面的add的例子。
cnperf-cli --pmu addcnperf-cli kernel
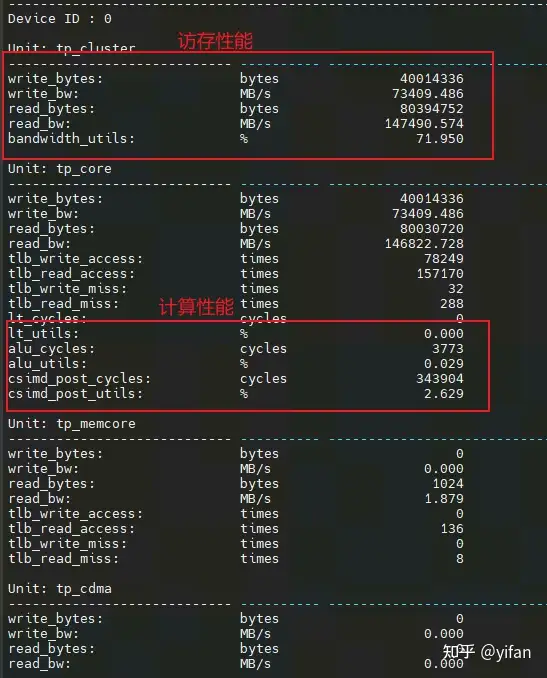
通过record --pmu命令启动程序,获取程序运行中的数据并记录到日志文件。然后通过kernel命令解析生成的文件,获取kernel性能数据。将获取的性能数据与算子的理论计算量和读写数据对比,确定调优空间,定位调优点。如图中可以看到,此时的算子执行带宽利用率是71.95%,向量运算单元的利用率是2.629%。接下来就是针对访存单元或者计算单元的优化,具体的优化方法,可以参见之前的《BANG性能优化》课程相关内容。
以上参数的计算公式:

上述测试代码见 下面代码库: cambricon_mlu_learning/22_Tools/CNPerf
1. 在线课程:在线课程 – 寒武纪开发者社区 (cambricon.com)
2. 文档资料:文档中心 – 寒武纪开发者社区 (cambricon.com)
3. 代码库:https://gitee.com/yifanrensheng/cambricon_mlu_learningc
热门帖子
精华帖子





 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读