打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
知乎链接:【CN-Tools03】CNServing 的使用
https://zhuanlan.zhihu.com/p/609226027
若是初学者,建议先看前面的。
CNServing 是一款可部署 MagicMind 序列化模型的高性能服务系统,专为生产环境而设计。任意框架模型通过 MagicMind生成序列化模型后,使用 CNServing可将其方便快捷地部署在 MLU 服务器上,为客户端提供高性能服务。

当我们完成将模型转换为 MagicMind 模型后,往往需要将模型在开发环境中部署,最常见的方式是在服务器上提供一个 API,即客户端向服务器的某个 API 发生特定格式的请求,服务器收到请求资料后通过模型进行计算,并返回结果。
支持使用 Docker 镜像部署 serving
支持 gRPC协议请求
支持 MagicMind序列化模型
支持模型热更新、自动加载新模型、卸载旧模型
支持 warmup
支持并发请求
支持多模型部署
支持多卡部署
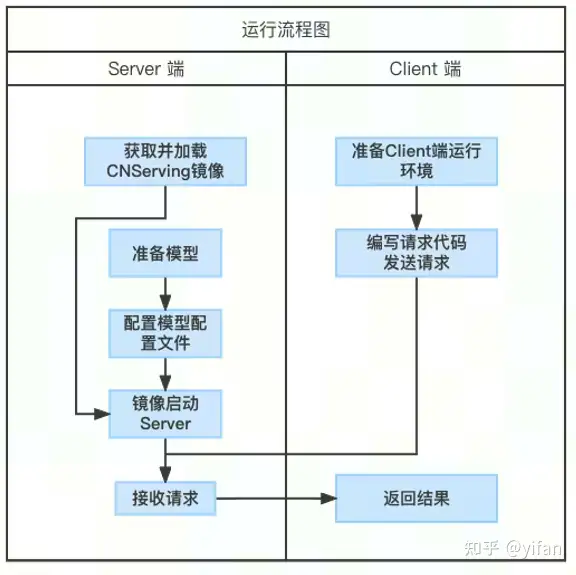
1)模型准备
获取 MagincMind 序列化模型,并按如下目录结构放置模型:
|-- /model_path/model_name/ |-- model_version |-- model_info |-- model_file_name
2)获取并加载镜像
从 CNServing 交付件中获取 CNServing 镜像包:cnserving-{version}.tar.gz。其中,{version} 为版本字符串。
docker load -i cnserving-${version}.tar.gz3)配置模型配置文件
创建配置文件 models.config,文件格式如下:
model_config_list:{
config:{
name:"model_name",
_path:"/model_path/model_name",
model_platform:"magicmind"
}
}4)运行 CNServing 镜像启动 server
使⽤如下命令启动 server:
docker run --name="cnserving_container" \
-t --rm \
-p 8500:8500 \
--device=/dev/cambricon_ctl \
--device=/dev/cambricon_dev0 \
-v ${PWD}:${PWD} \
cnserving:${version} \
--model_config_file=${PWD}/models.config &运行 Docker 时需要确保如下几点:
将 8500 端⼝映射到 Docker 外。
挂载 MLU 设备节点。
将模型⽂件映射到 Docker 内,models.config 中的 _path 为模型在 Docker 内的路径。
在同一个主机下:
virtualenv client_env --python=python3 source client_env/bin/activate pip install tensorflow_serving_api==2 # 如果在server服务器执⾏client脚本,可以使⽤127.0.0.1 # 如果使⽤其它服务器执⾏client脚本,请将127.0.0.1替换为server端服务器IP python run_client.py 127.0.0.1:8500 ##这个需要自己写
run_client.py 需要自己写,核心代码如下:
import grpcimport tensorflow as tffrom tensorflow_serving.apis import predict_pb2from tensorflow_serving.apis import prediction_service_pb2_grpcif __name__ == '__main__':
channel = grpc.insecure_channel('server_ip:port')
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
request = predict_pd2.PredictRequest()
request.model_spec.name = 'model_name'
# prepare inputs ...
request.inputs['input_name'].CopyFrom(tf.make_tensor_proto(input_data, shape=input_shape))
result = stub.Predict(request, timeout)
# get output: result.outputs['output_name'] ...使用中一个比较重要的文件是配置文件:model_file_name 和 model_info。注意不是最外层的 models.config。
当获取到 MagicMind 序列化模型后,按如下目录结构放置模型。
|-- models.config |-- /model_name/ | |-- version | |-- model_file_name | |-- model_info | |-- warm_up_file_name
第⼀级目录为模型名称 model_name,client 端发送请求时需要的模型名称参数必须与此处的 model_name 相同。
第⼆级目录为模型版本,用正整数表示,该目录包括 MagicMind 序列化模型文件、 model_info 文件和模型热启动文件等。
model_config_file 用于配置模型的名称、路径和运行时后端,在 server 启动时作为参数传递给 server 程序,这样 CNServing 启动时可获取要加载的模型信息和模型路径信息。 另外可以在这里设置多模型的部署和使用。
model_info 文件存放位置与模型序列化文件相同,属于该模型独有的配置文件,用于配置模型相关信息,例如,模型 input 或 output 节点名称、shape 等,还可以配置该模型部署的设备号、warmup 文件名称等信息。 每次启动 server 的同时,都会将当前模型使用配置项及其值全部写到 model_info_dump文件中,因此可根据该文件创建 model_info文件(使用 cp model_info_dump model_info),然后修改 model_info中的对应配置项的值并重启 server。
model_info 的配置项如下:

消除第⼀次⾼延迟的请求:模型加载后的第一个请求一般会进行形状推导等,这些操作耗时很⾼,比之后请求的 latency 可能会高出几个数量级。
需要执行以下操作:
1. 根据模型名称和输⼊节点 shape ⽣成⼀个 warmup ⽂件,并将其放在模型目录中,即 data 和 graph 的同级目录。
2. 在 model_info 文件中配置 warmup_file_name 的值为 warmup 文件名称,然后启动 server 即为该模型 warmup。
3 生成 warmup的核心代码
import tensorflow as tffrom tensorflow_serving.apis import model_pb2from tensorflow_serving.apis import predict_pb2from tensorflow_serving.apis import prediction_log_pb2request = predict_pb2.PredictRequest()request.model_spec.name = 'model_name'request.inputs['input_name'].CopyFrom(tf.make_tensor_proto(input_data, shape=input_shape))with tf.io.TFRecordWriter('./warmup_requests_data') as writer:
log = prediction_log_pb2.PredictionLog(predict_log=prediction_log_pb2.PredictLog(request=request))
writer.write(log.SerializeToString())通过构造对应模型的 request 信息并将其保存到文件中,完成 warmup 文件的生成。
运行后的目录结构
├── client_env ├── sample_add │ ├── generate_warmup_file.py │ ├── models.config │ ├── monitoring.config │ ├── run_client.py │ ├── sample_add │ │ └── 123 │ │ ├── model_info │ │ ├── model_info_dump │ │ ├── sample_add_model │ │ └── warmup_requests_data
模型配置放置:
├── sample_add │ └── 123 │ ├── model_info │ ├── model_info_dump │ ├── sample_add_model │ └── warmup_requests_data
准备好镜像,这里准备的是: http://yellow.hub.cambricon.com/cnserving/cnserving:0.8.0;
模型配置文件在对应代码下:cambricon_mlu_learning/22_Tools/CNServing/cnserving_sample_code/sample_add下的models.config 。
启动服务:
cd cambricon_mlu_learning/22_Tools/CNServing/cnserving_sample_code/sample_add ./start_server.sh yellow.hub.cambricon.com/cnserving/cnserving:0.8.0
cd cambricon_mlu_learning/22_Tools/CNServing/cnserving_sample_code virtualenv client_env --python=python3 source client_env/bin/activate pip install tensorflow_serving_api==2 # 如果在server服务器执⾏client脚本,可以使⽤127.0.0.1 # 如果使⽤其它服务器执⾏client脚本,请将127.0.0.1替换为server端服务器IP cd sample_add python run_client.py 127.0.0.1:8500
运行结果:
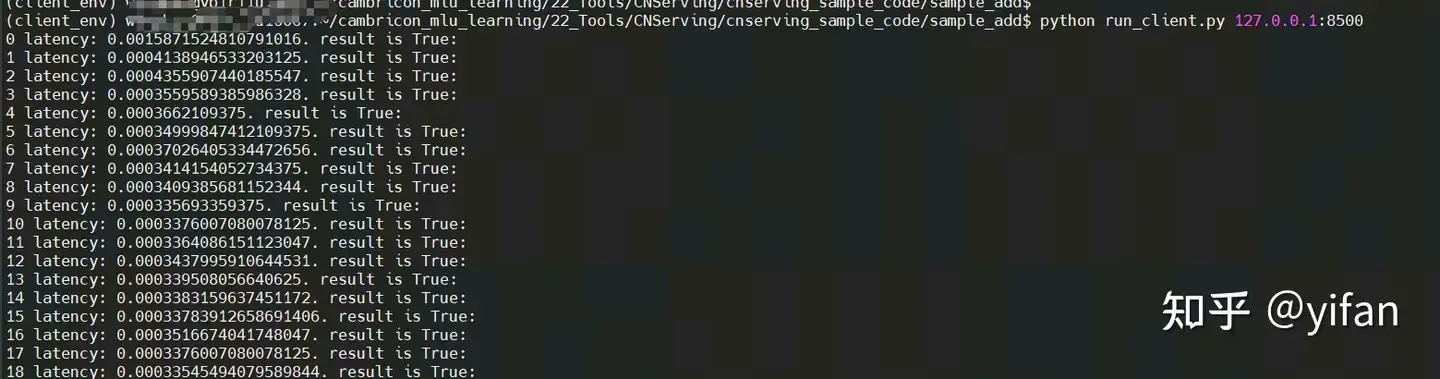
生成 warmup 文件吗,当前实例已经生成。
# 生成 warmup_file文件 python generate_warmup_file.py
这里热启动不能看到效果。因为本身计算时间就很短
这里使用一个计算量大的resnet来比对:
修改是否加载,启动服务测试:
cd cambricon_mlu_learning/22_Tools/CNServing/cnserving_sample_codesource client_env/bin/activatecd cambricon_mlu_learning/22_Tools/CNServing/cnserving_sample_code/resnet50_v1./start_server.sh yellow.hub.cambricon.com/cnserving/cnserving:0.8.0
客户端测试:
cambricon_mlu_learning/22_Tools/CNServing/cnserving_sample_codesource client_env/bin/activate cd resnet50_v1/ python run_client.py --ip_port=127.0.0.1:8500 --network=resnet50_v1 --batch_size=4
启用了与否修改 model_info
cd cambricon_mlu_learning/22_Tools/CNServing/cnserving_sample_code/resnet50_v1vi resnet50_v1/123/model_info
不启用为空,启用则增加:warmup_requests_data
... ...model_type: MAGICMIND_SERIALIZATIONmodel_file_name: "resnet50_v1_offline_model"warmup_file_name: "" #不启用#warmup_file_name: "warmup_requests_data" #启用
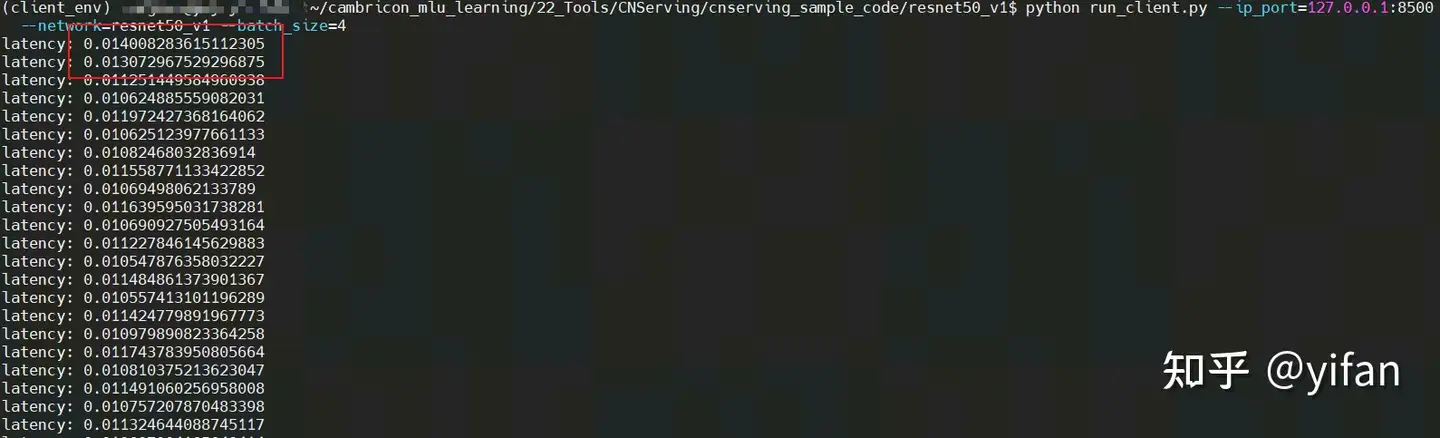
效果
1)启用时的情况
2)不启用的情况
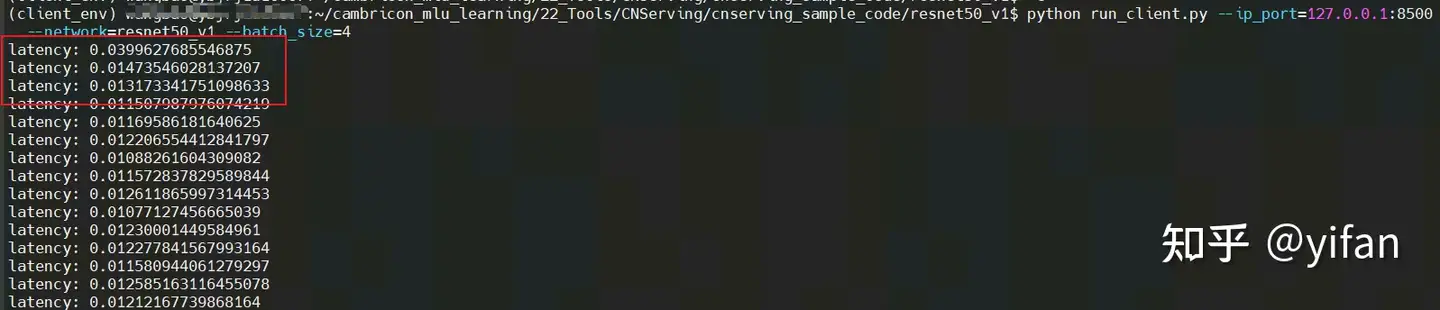
可以看出不启用时,第一个延迟较长。另外解释在启用时,第一个时间也长的可能原因:第一次与server连接花销的时间
相关链接
1. 在线课程:在线课程 – 寒武纪开发者社区 (cambricon.com)
2. 文档资料:文档中心 – 寒武纪开发者社区 (cambricon.com)
3. 代码库:https://gitee.com/yifanrensheng/cambricon_mlu_learningc
热门帖子
精华帖子





 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读