打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
背景介绍
机器学习任务在广泛的领域和各种系统(从嵌入式系统到数据中心)中变得越来越普遍。同时,基于神经网络的机器学习算法(特别是卷积和深度神经网络,即CNN和DNN)被证明是许多应用最有效的新技术。随着架构向由核心和加速器组合构成的异构多核方向发展,机器学习加速器可以实现效率的罕见组合(由于目标算法数量少)和广泛的应用范围。Cambricon科技公司设计的芯片高效地将CNN和DNN网络成功地映射为硬件芯片,极大地提高了CNN与RNN算法的执行效率(在CNN和DNN10个最大层中,Cambricon加速器比主频为2GHz的128位SIMD内核平均速度快117.87倍,能耗效率高21.08倍),加速器在小面积,低能耗前提下实现高吞吐量,极大推动了人工智能的发展。本文参考陈云霁老师团队的DianNao系列论文,总结了Cambricon加速器芯片的设计特点,总的来说文章主要包括了以下几个方面:
1、CNN与RNN
2、对存储结构进行划分
3、三级流水的核心计算单元
4、为芯片设计专用的指令集
5、针对大数据高性能应用的改进
1、CNN与DNN
深度神经网络(DNN)和卷积神经网络(CNN)在今天的人工智能领域得到了广泛的应用。 DNN和CNN密切相关,它们的区别主要在卷积层的存在和/或性质方面。Cambricon芯片设计主要是这两种网络的加速器,因此了解它们的结构特点是十分有意义的事情。
一般结构 虽然深度和卷积神经网络有各种形式,但是它们也具有足够的通性来定义通用的公式。通常,这些算法由不同的层组成;这些层按顺序执行,因此可以独立地考虑(和优化)它们。每层通常包含几个称为特征图的子层;然后,我们使用术语输入要素图和输出要素图。 总的来说,网络有三种主要的层:卷积层、池化层、网络顶部分类层。
卷积层 卷积层的作用是将一个或多个局部过滤器应用于来自输入(前一个)层的数据。因此,输入和输出要素图之间的连通性是局部的而不是完整的。 考虑输入是图像的情况,卷积是输入层的Kx×Ky子集(窗口)和相同维度的内核之间的2D变换。可以参见图1。内核值是输入层和输出(卷积)层之间的突触权重。 由于输入层通常包含多个输入要素图,并且由于通常通过将卷积应用于所有输入要素图的同一窗口来获得输出要素图点,因此参见图1,内核为3D,即Kx×Ky× Ni,其中Ni是输入要素图的数量。 注意,在某些情况下,连接是稀疏的,即并非所有输入特征映射都用于每个输出特征映射。
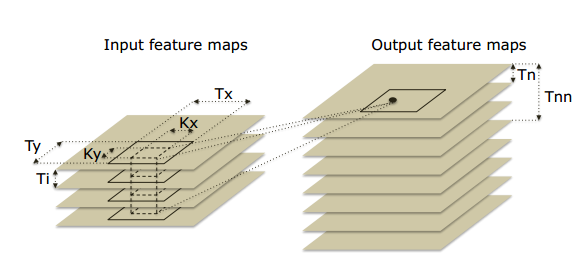
图1 卷积层
池化层 池化层的作用是在一组邻居输入数据之间聚合信息。在图像的情况下,它仅用于保留给定窗口内图像的显着特征和/或以不同比例保留图像,参见图2.池化图层的一个重要副作用是减少特征图尺寸。每个要素图分别汇集在一起,即2D池,而不是3D池。 池化可以以各种方式完成,一些优选技术是平均和最大操作; 汇集可能会或可能不会跟随非线性函数。
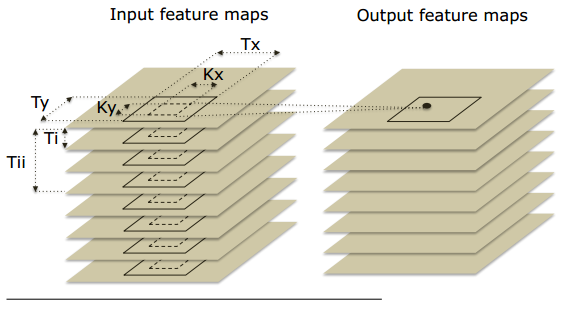
图2 池化层
分类层 该分类器可以是线性的或多层(通常是2层)感知器,参见图3。与卷积层一样,非线性函数应用于神经元输出,通常是S形,与卷积层或池化层不同,分类器通常聚合(展平)所有要素图,因此分类器层中没有要素图的概念。
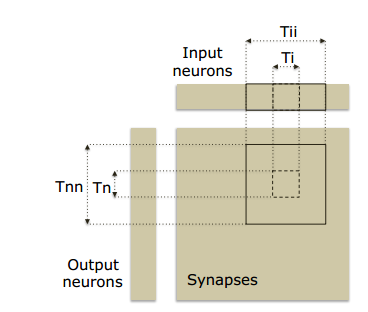
图3 分类器
2、对存储结构进行划分
Cambricon加速器芯片的设计里包含三块片上存储,分别是用于存储input neurons的NBin、存储output neurons的NBout以及用于存储神经网络模型权重参数的SB。这三块存储均基于SRAM实现,以获取低延时和低功耗的收益。片上存储与片外存储的数据交互方式通过DMA来完成,以尽可能节省通讯延时。可以参见图4。
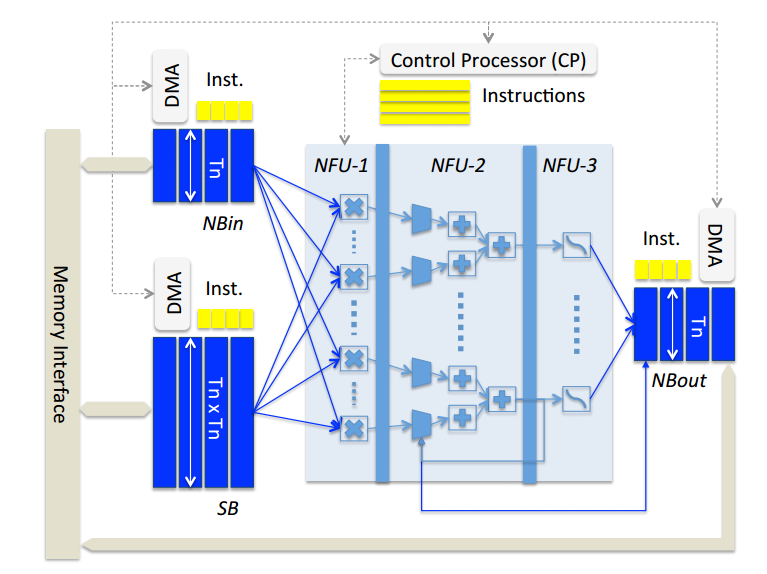
图4 Cambricon加速器结构
设计之初,之所以将片上SRAM存储划分为NBin/NBout/SB这三个分离的模块,是考虑到SRAM的不同访存宽度(NBin/NBout与SB的访存宽度存在明显差异,形象来说,NBin/NBout的访存宽度是向量,而SB则会是矩阵)在功耗上存在比较明显的差异。把它们拆分成不同的模块,可以在功耗/性能上找到更佳的设计平衡点。而将访存宽度相同的NBin/NBout也拆分开来的原因则是为了减少data conflict,因为NBin/NBout扮演的还是类似于cache的角色,而这两类数据的访存pattern并不尽相同,如果统一放在一块SRAM里,cache conflict的概率会增大,所以通过将访存pattern相近的数据对应于不同的SRAM块,“专款专用”,可以进一步减少cache conflict,而cache conflict的减少,无论是对于性能的提升,还是功耗的减少都会有着正面的意义。
NFU的精神是将层的分解反映到Ti输入/突触和Tn输出神经元的计算块中。 这对应于分类器和卷积层的循环i和n。每个层类型的计算可以在2或3个阶段中分解。分类器层的运算:数据输入与突触的乘法运算,所有乘法的累加运算,sigmoid运算。卷积层与分类器几乎是相同的;最后阶段(S形或其他非线性函数)的性质可以变化;对于池化层,没有乘法(没有突触),池化操作可以是平均值或最大值。注意,加法器有多个输入,它们实际上是加法树; 第二阶段还包含用于池化层的移位器和最大运算符。
如图4所示,NFU计算单元利用了三级流水线的设计,极大地提高了计算的效率。对于一个大的神经网络,它的模型参数会依次被加载到SB里,每层神经 的输入数据也会被依次加载到NBin, 计算结果写入到NBout。NFU里提供的是基础计算building block(乘法、加法操作以及非线性函数变换),不会与具体的神经元或权重参数绑定,通过这种设计,Cambricon芯片在支持模型灵活性和模型尺寸上相比以前的人工智能芯片有了极大地提升。
在NFU的设计过程中,用到了许多设计细节:
采用16位浮点操作代替32位浮点 文献中有充分的证据表明,甚至更小的算子(例如8位甚至更小)对神经网络的准确性几乎没有影响,可以参看图5。但是这个选择可以大大降低芯片面积和功耗可以参看图6。这是由于神经网络运算中呈现出小数据和稀疏性特点,因此低位宽的数据处理方式能够有效提高效率,降低功耗,同时在芯片实现过程中,乘加运算的功能部件均支持不同位宽(如float16/float32)的数据运算的复用,以同时保证性能和正确性

图5 UCI数据集上16位和32位数据运算精确度比较

图6 16位和32位数据芯片面积和功耗对比
对input neurons数据以及SB数据局部性的挖掘 用通俗一些的说法,其实就是把输入数据的加载与计算过程给overlap起来。在针对当前一组input neurons进行计算的同时,可以通过DMA启动下一组input neurons/SB参数的加载。当然,这要求精细的co-ordination逻辑保证。另外,这也会要求NBin/SB的SRAM存储需要支持双端口访问,这对功耗和面积会带来一定的影响。
对output neurons数据局部性的挖掘 在设计上,为NFU引入了专用寄存器,用于存储output neurons对应的partial计算结果(想象一下对应于全连接层的一个output neuron,input neurons太多,NBin放不下,需要进行多次加载计算才能完成一个output neuron的完整结果的输出)。并且会在设计上将NBout用作专用寄存器的扩展,存放partial计算结果,以减少将partial计算结果写入片外存储的性能开销。
目前Cambricon使用控制指令来探索层的不同实现(例如,分区和调度),并为机器学习研究人员提供尝试不同层的灵活性实现。指令集的格式如图7。

图7 Cambricon芯片指令集格式
层执行被分解为一组指令。粗略地说,一条指令对应于相应的循环;n对于分类器和卷积层,以及环。机器学习的工程师可以通过相应的指令来完成相应神经网络的配置。
在神经网络运算中,进行的运算多为矢量化运算,如矩阵/向量运算,因此支持标量运算的指令在神经网络芯片上效率低下,针对此,Cambricon团队设计一套专门的指令集——DianNaoYu。其具体指令项目如图8。
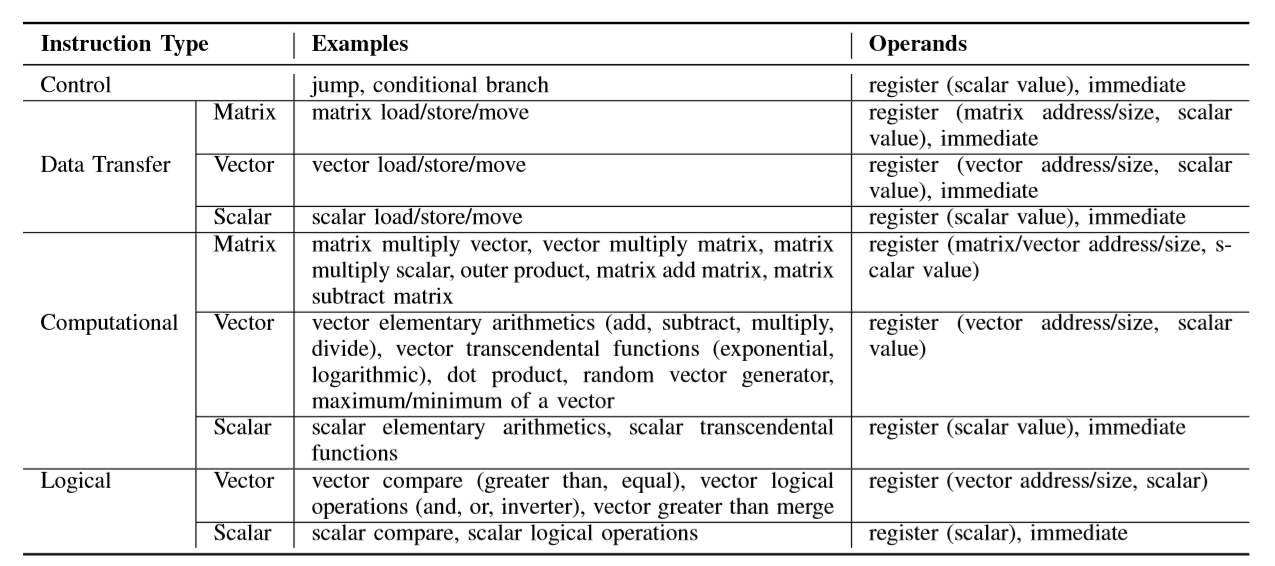
图8 DianNaoYu指令集的指令类型
其中,以矩阵乘向量指令作为示例,具体指令格式如图9。
为Cambricon芯片设计的专用指令集DianNaoYu指令直接面对大规模神经元和突触的处理,一条指令即可完成一组神经元的处理,并对神经元和突触数据在芯片上的传输提供了一系列专门的支持。模拟实验表明,采用DianNaoYu指令集的深度学习处理器相对于x86指令集的CPU有两个数量级的性能提升。

图9 矩阵乘向量(MMV)指令格式
5、针对大数据高性能应用的改进
在DaDianNao一文中Cambricon针对主流神经网络模型尺寸较大的应用场景,提出了一种具备伸缩性,并通过这种伸缩性可以承载较大尺寸模型的加速器设计架构。整体的逻辑结构上文的介绍相差不多,但是在某些方面进行了改进。
使用eDRAM代替SRAM/DRAM 层大小可以从小于1MB到大约1GB,其中大多数在几十MB范围内。虽然SRAM适合于高速缓存,但它们不够密集以用于这种大规模存储。而已知eDRAM具有更高的存储密度。 例如,10MB SRAM存储器在28nm处需要20.73mm2 ,而相同尺寸和相同技术节点的eDRAM存储器需要7.27mm2 ,即存储密度高2.85倍。
在体系结构设计中以模型参数为中心 模型参数(对应于神经网络中的突触连接)存放在固定的eDRAM存储区域中,需要通过访存操作完成加载的是网络神经元(即对应于神经层 的input/outout neurons)。这样设计考虑的原因是,无论是神经网络的training还是inference环节,对于于DaDianNao的问题场景,模型的尺寸要远远大于数据尺寸以及网络神经层的神经元数据尺寸,所以将尺寸更大的神经网络模型参数固定,而将尺寸较小的神经元通过访存操作进行加载、通信,可以减少消耗在访存上的开销。此外,模型参数会布署在距离计算部件很近的布局区域里,以减少计算部件工作过程中的访存延时。模型参数在整体计算过程中会不断地被复用,而神经元被复用的频率则并不高,所以将模型参数存放在固定的存储区域里,可以充分挖掘模型参数的data locality,减少片外访存带宽,同时提升整体加速器的性能。
充分利用CNN与RNN的可分性进行多片设计 神经网络模型具备良好的模型可分特性。以常用的CNN/DNN这两类神经层为例。当单层CNN/DNN 对应的模型参数较大,超过了单片存储极限时,可以利用这种模型可分性,将这个 划分到多个芯片上,从而通过多片连接来支持大尺寸模型。想更具体的把握这个问题,不妨这样思考,对于CNN 来说,每个feature map的计算(以及计算这个feature map所需的模型参数)实际上都是可以分配在不同的芯片上的,而DNN 来说,每个output neuron的计算(以及计算这个output neuron所需的模型参数)也都是可以分配在不同的芯片上的。
NBin/NBout以及SB的组织方式更适合大数据 针对存储神经层输入输出数据的NBin/NBout,存储神经连接参数的SB的组织方式,以及其与核心计算单元NFU的数据交互方式进行了大模型的专门考量,结构可以参见图10
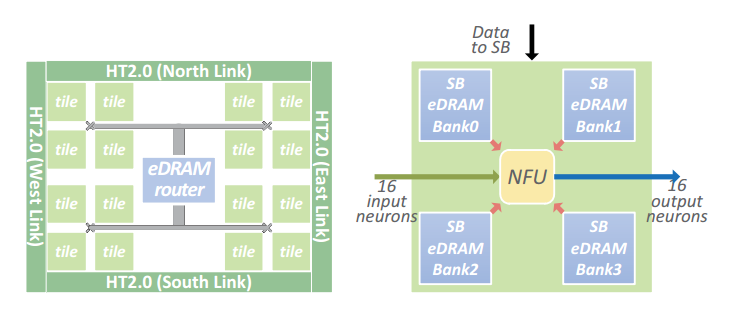
图10 左边为芯片高层结构;右边为tile底层结构图
单个芯片由16个Tile组成,每个tile内部会由一个NFU配上4个用于存储SB的eDRAM rank组成。而NBin/NBout则对应于左图eDRAM router所连接的两条棕色的eDRAM rank。将SB拆分开,放置在每个NFU的周围,可以让每个计算部分在计算过程中,访问其所需的模型参数时,访存延迟更小,从而获得计算性能上的收益。
NFU针对性设计 参见图11能够看到NFU的每个Pipeline Stage与NBin/NBout/SB的交互连接通路,图12则展示了针对不同的神经层,NFU的流水线工作模式。
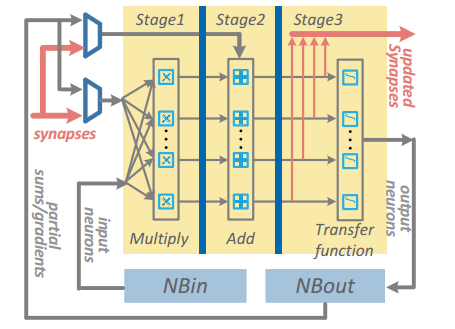
图11 NFU结构
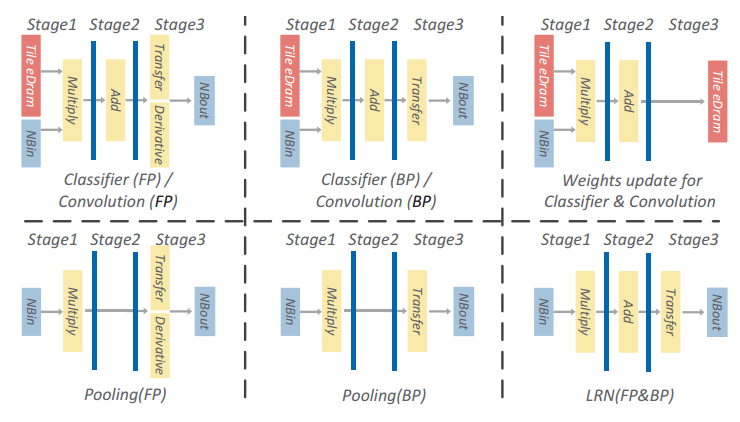
图12 不同神经层NFU流水线的工作模式
热门帖子
精华帖子





 Ashelly
13 回复
Ashelly
13 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读