打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
知乎链接:https://zhuanlan.zhihu.com/p/592960031
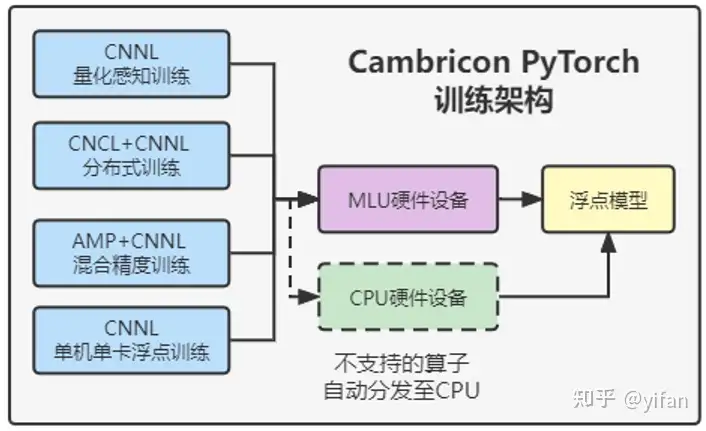
Cambricon PyTorch 支持四种训练模式:
单机单卡浮点训练:Cambricon PyTorch 支持的基础训练模式。
量化感知训练:Cambricon PyTorch 支持 QAT(Quantization Aware Training,量化感知训练),以提高推理时的量化精度。
分布式训练:Cambricon PyTorch (CATCH)支持对 Tensor 进行单机多卡和多机多卡的卡间集合通信,对网络进行单机多卡和多机多卡的分布式训练。
混合精度训练:Cambricon PyTorch 支持调用原生接口 torch.cuda.amp 实现混合精度训练,能够实现部分算子以 float 类型计算,部分算子以 half 类型计算。
和上一篇内容完全相同:
单机单卡浮点训练模式:使用 CNNL 作为后端,无需进行量化设置和分布式设置,灵活简单易用,可快速逐层调试,并且可以在单卡上发挥良好的训练性能和得到高训练精度,并且mlu不支持的算子可以自动分发到cpu执行。
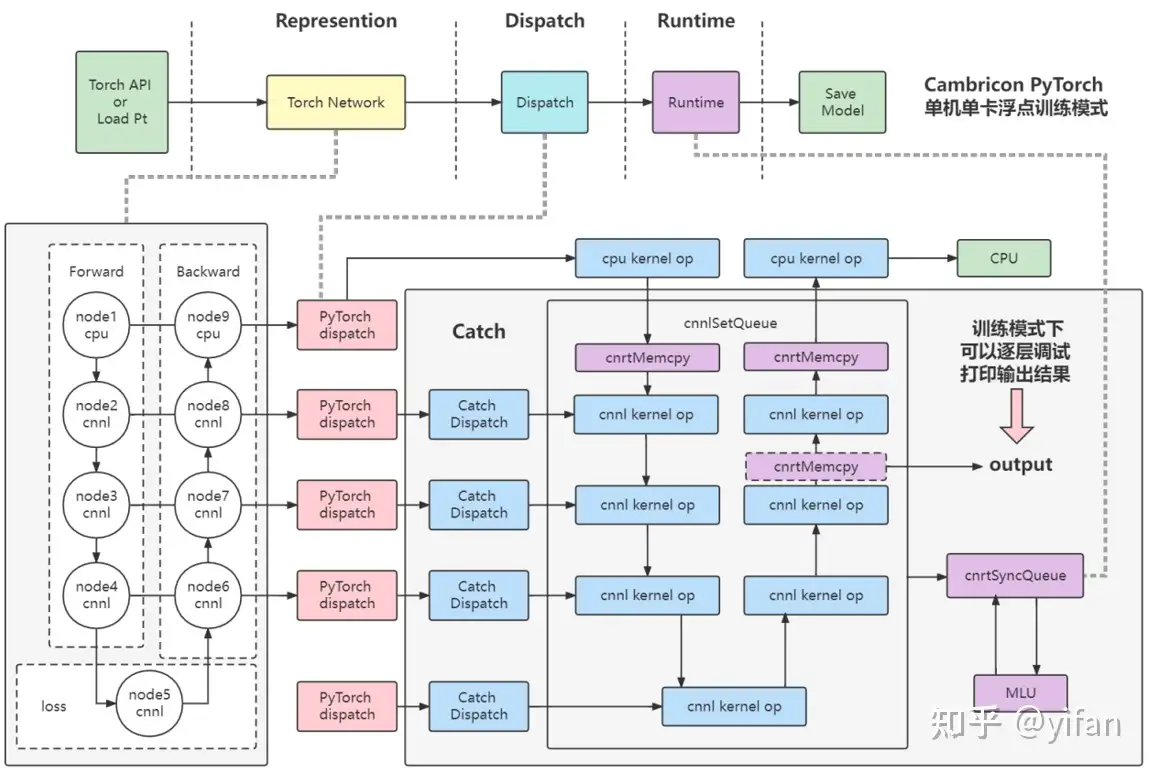
1、首先 torch api或者pt加载模型
2、模型中的算子逐层经过pytorch的 dispatch 模块进行 cpu/mlu算子分发,即mlu支持的算子优先使用mlu,mlu不支持的算子使用cpu进行运算,分发到mlu上的算子会进入到catch库中,先使用catch库中的catch dispatch 模块进行 cnnl 算子分发
3、分发完毕后会进入到runtime阶段,其中runtime阶段的流程如图所示,得到一个cnnlqueue,最后进行cnrtsyncqueue将cnnlqueue下发至驱动进行运算并返回结果
4、如果mlu算子后面还接着cpu算子,将继续使用cpu进行运算
其中:
PyTorch Dispatch:该模块为PyTorch 包中的分发模块,根据算子注册列表,将PyTorch Python层算子接口分发至后端,指定每一个算子的后端设备(cpu/mlu)。
Catch Dispatch:该模块为Cambricon Catch 包中的分发模块,根据MLU的算子注册列表,对每一个进入Catch的算子进行分发和 CNNL 接口指定。
Runtime:调用cnrtSyncQueue,将CNNL 的计算队列进行下发至驱动,并执行队列内的 kernel 函数计算并返回结果。
逐层调试:该训练模式下,支持逐层调试,打印某一层输出时会将输出结果通过 cnrtMemcpy 将数据从 Device 端拷贝到 Host 端。
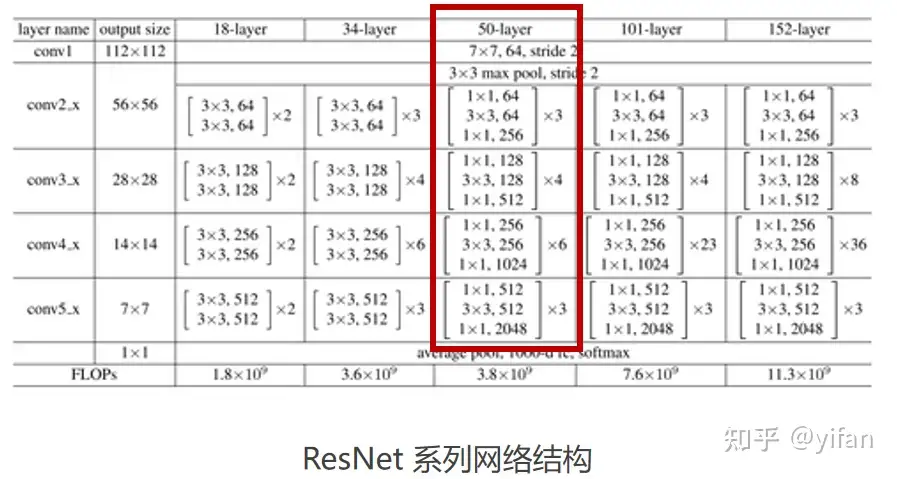
ResNet:由何恺明、张祥雨、任少卿、孙剑 等人于2015年提出,引入残差模块,极大的消除了深度过大的神经网络退化问题,为人工智能日后发展做出了巨大的贡献,这里选用 ResNet50 作为 Cambricon PyTorch 的入门训练示例。
实践示例相关参数设置
应用场景:图像分类检测
数据集:输入规模:(N,3,224,224)(NCHW)
输入精度:Float32
是否量化:不使用量化
是否可变输入:固定输入
Loss 指标:相同epoch下loss和top1 5
优化器:SGD
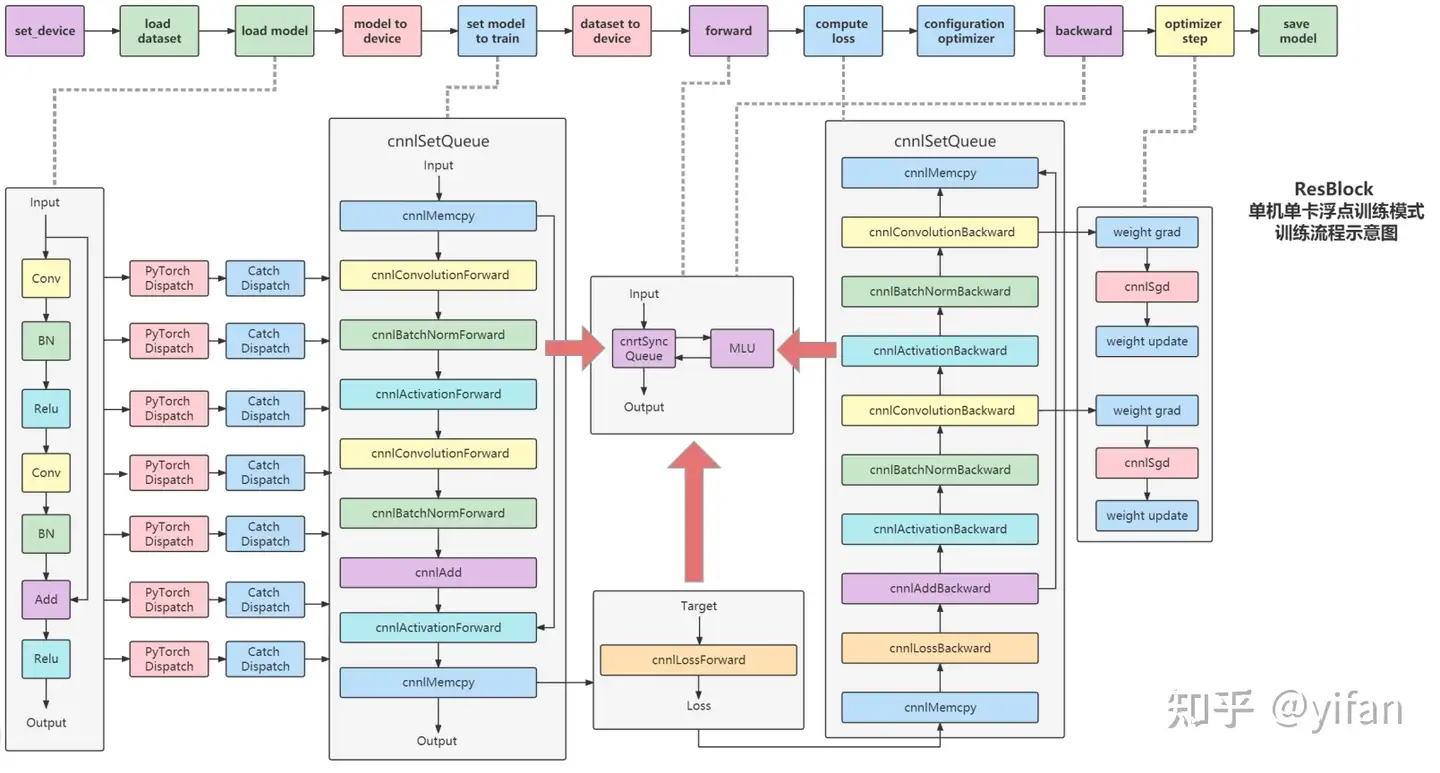
1) 运行流程

Set_device:指定 MLU 硬件设备ID
Load Dataset:加载推理数据集至Host 端内存
Load Model:加载网络模型和权重至 Host 端内存
Model To Device:将模型权重 copy 至 Device 端
Set Model To Train:将模型转换为 training 模式,调用 PyTorch Dispatch 和 Catch DisPatch 模块,完成算子分发
Dataset To Device:为网络模型输入创建 CnnlTensor 和对应的 Device 端内存空间,并完成 Host 至 Device 拷贝
Configuration optimizer:配置人工智能训练优化器,如 SGD、Adam 等
Forward:逐 cnnl 前向算子启动 CNNL Runtime 执行前向推理
Compute Loss:将 forward 的输出与 target 一同输入 cnnl loss 算子,计算 loss
Backward:根据 loss 结果进行反向推理,逐 cnnl 反向算子启动 CNNL Runtime
Optimizer Step:将反向推理得到的权重梯度乘以学习率,并进行权重更新,得到新的权重,完成一次训练
Save Model:保存训练好的模型
后端流程:
在进行load model 的时候,pytorch会通过 parser 解析加载的模型
通过pytorch 分发和 catch分发,得到了前向cnnl算子和后向cnnl算子,其中,前向cnnl算子的runtim对应着前端的forward接口,cnnlloss计算对应着前端的nn.loss接口,反向cnnl算子的计算对应着backward接口
最后cnnl梯度更新的部分对应着前端的optimize step,在完成上图的计算流程的多个循环后,将最新的weight权重保存
2)核心代码
# 设置硬件设备torch_mlu.core.set_device(0)#加载模型model = models.resnet50(pretrained=True)# 模型加载MLU并设置训练模式model.to(ct.mlu_device()).train()# 设置损失函数criterion = nn.CrossEntropyLoss()# 设置优化器optimizer = torch.optim.SGD(model.parameters(), lr,
momentum=momentum, weight_decay=weight_decay)# 加载损失函数至MLUcriterion.mlu()for (images, target) in enumerate(train_loader):
# 加载训练数据至MLU
images = images.to('mlu', non_blocking=True)
target = target.to('mlu', non_blocking=True)
# 前向推理
output = model(images)
# 损失计算
loss = criterion(output, target)
optimizer.zero_grad()
# 反向推理
loss.backward()
# 梯度更新
optimizer.step()3)具体代码运行
可见文末相关连接3 代码库。
运行
python resnet50_imagenet.py --gpu 2 --arch resnet50 --epoch 8 --workers 10 /data/datasets/imagenet/
参数说明:
--gpu 使用第几张卡训练
--arch 选用架构
--epoch 迭代次数
--workers 线程数量,用于加速数据加载
数据路径为/data/datasets/imagenet/ 下载和格式如下(使用前注意准备和替换):
imagenet ├── train │ ├── n01440764 │ ├── n01443537 │ ├── ... ├── train.txt ├── val │ ├── n01440764 │ ├── n01443537 │ ├── ... └── val.txt #其中一条:val/n03623198/ILSVRC2012_val_00030341.JPEG 997
说明:代码见 代码库的:cambricon_mlu_learning/13_PyTorch/pytorch_train
1. 在线课程:在线课程 – 寒武纪开发者社区 (cambricon.com)
2. 文档资料:文档中心 – 寒武纪开发者社区 (cambricon.com)
3. 代码库:hpytorch_modelzoo: cambriocn pytorch训练和推理模型集合 (gitee.com)
热门帖子
精华帖子





 Ashelly
14 回复
Ashelly
14 回复
 三叶虫
7 回复
三叶虫
7 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读