打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
知乎链接:【CN-PT4】Cambricon PyTorch 的多卡分布式训练(DDP)
https://zhuanlan.zhihu.com/p/609701095
若是初学者,建议先看前面的,尤其是其中 PyTorch 相关的模块。
定义:分布式训练,是指基于分布式相关技术,将一个完整的人工智能网络模型数据切分成多份,利用多个加速卡分别完成计算任务,并通过多卡之间通信进行数据同步和汇总,共同完成整个网络模型的训练任务。
好处:分布式训练大大缩短了整个模型训练时间,同时可以解决单卡无法单次加载大模型数据的问题。
常见的分布式形式:
Pytorch DDP:一个广泛采用的单程序多数据训练方法。使用 DDP,模型会被复制到每个进程,然后每个模型副本会被输入数据样本的不同子集。DDP 负责梯度通信以保持模型副本的同步,并将其与梯度计算重叠以加快训练速度。后面会详细介绍。
Horovod: 一种开源的分布式人工智能训练框架,支持多种前端训练框架(TensorFlow、 PyTorch等)和底层通信库。 Horovod通过对前端训练框架进行封装,并基于各个平台的底层通信库来实现分布式调度、通信、梯度计算等功能,从而在各类集群平台支持模型的分布式训练。
1)数据并行
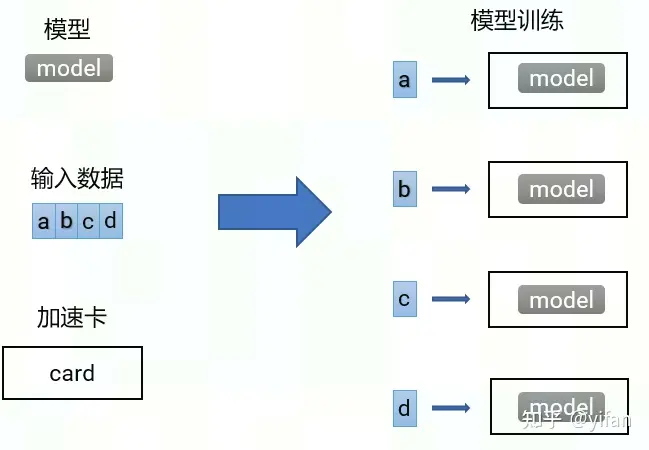
加速比: ![]()
p 指计算设备数量,比如CPU或GPU个数
T_1 指一个任务在单个计算设备顺序执行的时间
T_p 指一个任务在 p 个计算设备并行执行的时间
2)模型并行
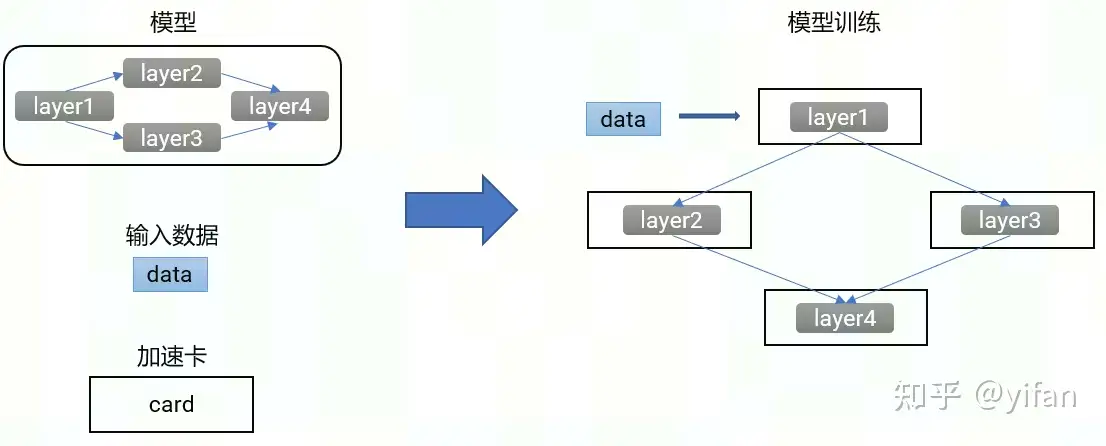
各个加速卡之间的输入输出会有依赖关系,一次计算任务需要各个加速卡串行执行才能完成。这里并行是指模型的不同部分,在多次迭代过程中可以并行计算。例如图中的 2在执行当前的计算任务时, 1可以并行执行下一次计算任务。

广播:是指服务器S1将自己拥有的数据a分别传输给其他服务器
散射:是指服务器S1将自己拥有的数据先切分成a、b、c、d不同部分,再分别发送给不同的服务器
聚集:是指服务器S1将其他服务器的数据都收集过来,组成一份完整的数据
规约:规约会涉及到对数据进行一些计算,我们这里可以假设需要对图中的a1到a4求平均值,那么S1执行的规约操作就会先把其他服务器的数据收集过来,然后执行一次求平均值计算,并将结果保存在S1
全聚集 AllGather:每个服务器都做 Gather 操作,最终是每个服务器都获得了全部完整的数据
全规约 AllReduce:每个服务器都对各自分片数据做 Reduce 操作,再将结果 Broadcast 至其他服务器,最终是每个服务器都获得全部数据的 Reduce 结果
规约散射 ReduceScatter:先在一台服务器做 Reduce 操作,再将结果 Scatter 至其他服务器
1) Parameter Server
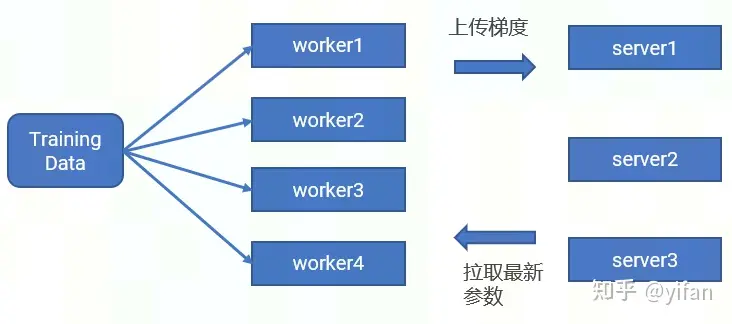
worker 节点,主要功能是保存部分训练数据、从 server 节点拉取最新的模型参数、根据训练数据计算局部梯度
server 节点主要功能是保存模型参数、接受worker节点上传的梯度并汇总计算、更新模型参数
2)RingAllReduce
work和server的节点的带宽存在限制,因此这里介绍下RingAllReduce的算法:
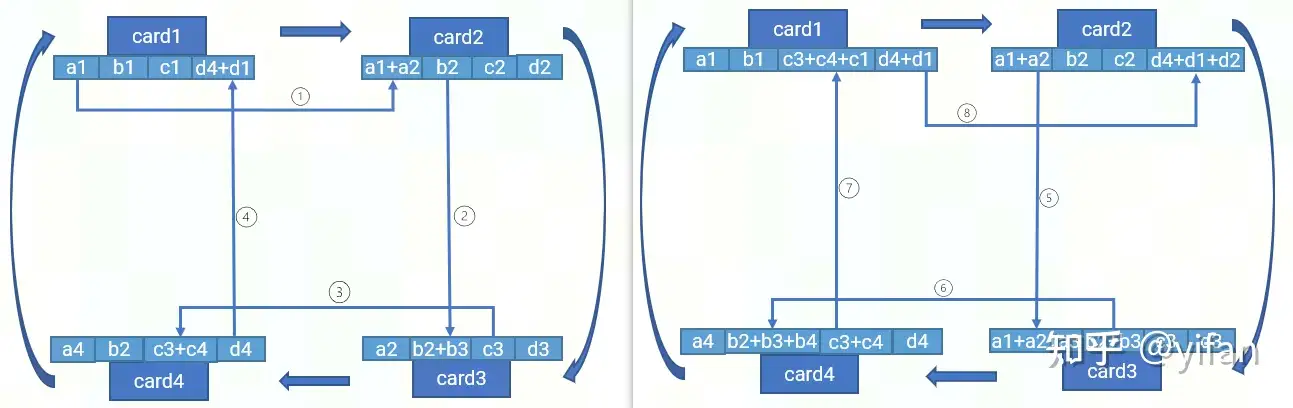
card1 将 a1 传给 card2,card2完成 a1 + a2 规约计算并存储
card2 将 b2 传给 card3,card3完成 b2 + b3 规约计算并存储
card3 将 c3 传给 card4,card4完成 c3 + c4 规约计算并存储
card4 将 d4 传给 card1,card1完成 d4 + d1 规约计算并存储
card2 将 a1+ a2 传给 card3,card3 完成 a1 + a2 + a3 规约计算并存储
card3 将 b2 + b3 传给 card4,card4 完成 b2 + b3 + b4 规约计算并存储
依次类推
依次类推
然后还有一次类似上面步骤的循环,最后再执行 allgather操作,最终实现所有的卡上都有完整的数据。
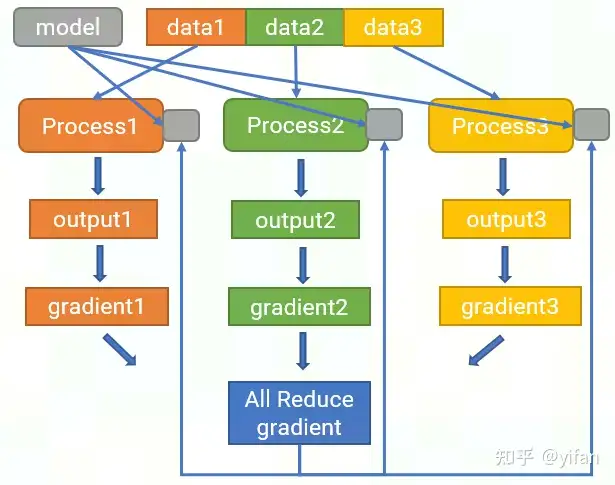
为每个加速卡生成一个进程,切分数据集并传给各个进程,各个进程复制一份完整的模型
各个进程独立完成前向计算、loss 计算以及反向计算,获得梯度
对各个进程的梯度进行规约,将结果广播给每个加速卡
每个加速卡收到规约梯度后再更新各自的模型参数
CNCL
CNCL(CambriconCommunicationsLibrary,寒武纪通信库)中文含义是寒武纪通信库,它提供了一套完备的接口来支持常用的集合式通信原语,包括前面提到的broadcast、all reduce等。CNCL内部支持多种芯片互联技术,包括通用的PCIe、Infiniband、Sockets等,另外还支持寒武纪公司提供的MLU- 互联技术。CNCL 能够根据芯片实际的互联拓扑关系,自动选择最优的通信算法和数据传输路径,从而最大化利用传输带宽完成不同的通信操作。
CNTOPO
CNTOPO是一款拓扑检测工具,主要功能是展示芯片通过MLU- 互联形成的拓扑结构,支持浏览器展示。cntopo show和cntopo find命令执行后打印的一些信息。这两个命令还支持很多其他参数,可以获取更丰富的信息,具体使用方法可以参考cntopo的用户手册。
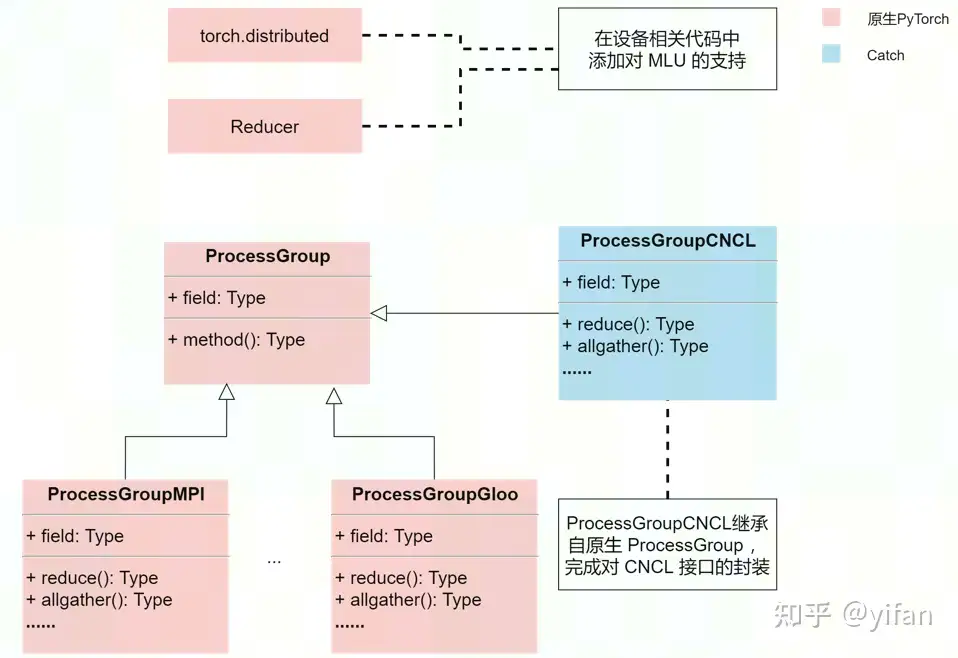
在原生pytorch的distributed和reducer模块,需要在相关设备代码中添加对MLU设备的支持。
通过继承原生DDP中的ProcessGroup模块,在Cambricon PyTorch 的Catch部分,添加一个对应的ProcessGroupCNCL模块,用于封装CNCL相关接口,目的是让DDP支持CNCL作为通信后端来使用。
具体执行流程如下图所示:
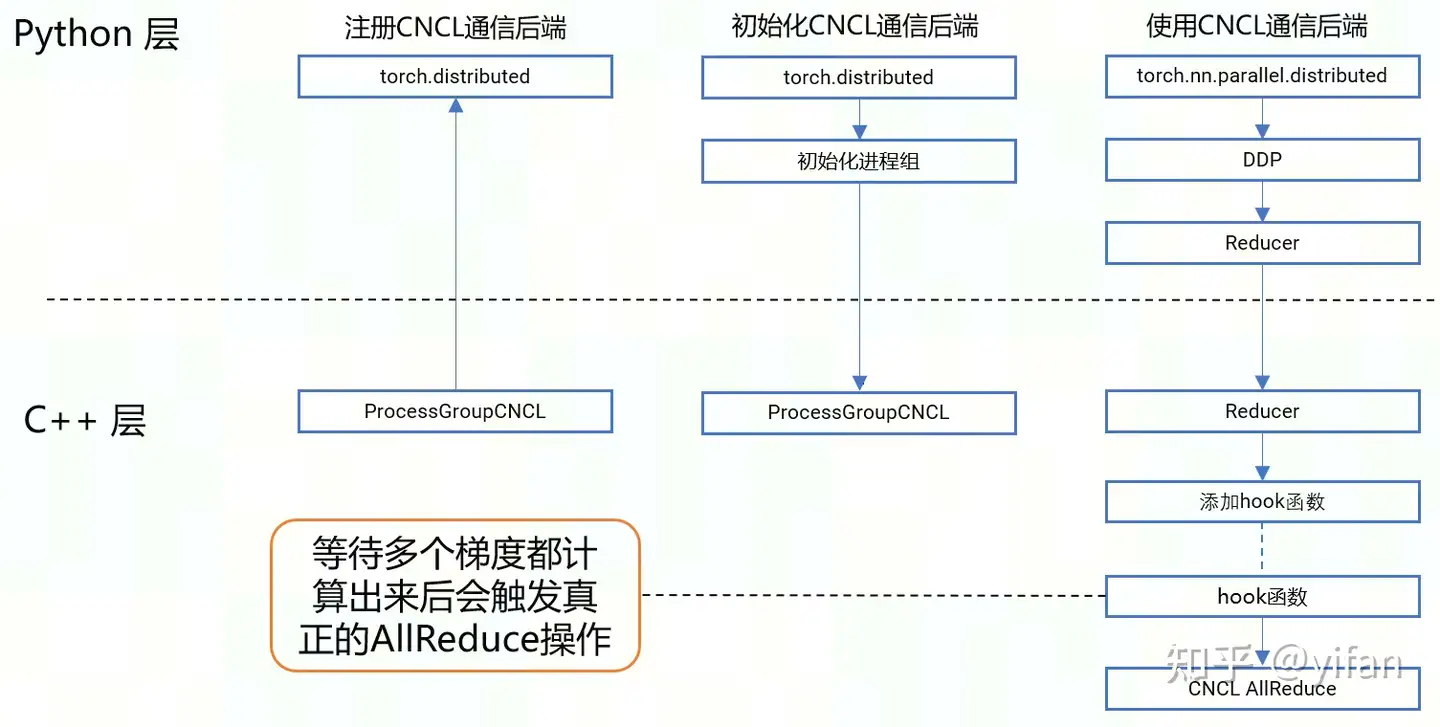
注册CNCL通信后端。在pytorch初始化时,触发catch的初始化代码,这部分C++代码会反向调用pytorch的distributed模块接口,注册CNCL到pytorch框架中
初始化CNCL通信后端。在使用DDP时,调用初始化进程组的接口来指定CNCL作为通信后端,这会触发底层C++代码创建ProcessGroupCNCL类的实例
调用CNCL完成分布式通信操作。具体是通过DDP初始化接口来让底层添加hook函数,这个函数会等待各个进程的梯度都计算出来后,再进行全规约计算,这就会通过前面提到的ProcessGroupCNCL,调用到CNCL的对应接口。
import torch# 导入分布式通信模块import torch.distributed as dist# 导入DDP 模块from torch.nn.parallel import DistributedDataParallel as DDP# 指定当前进程所属MLU设备torch.mlu.set_device(LOCAL_RANK)# 初始化进程组,指定通信后端为CNCLdist.init_process_group(backend="cncl")# 数据集分割采样sampler = dist.DistributedSampler(dataset, shuffle=shuffle)# 使用DDP加载模型model = DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK, broadcast_buffers=False)# 开始模型训练model.train()
借用课程代码:获取寒武纪docker pytorch1.9的镜像包,根据实验准备好环境
git clone https://gitee.com/yifanrensheng/cambricon_mlu_learning.gitcd cambricon_mlu_learning/23_PyTorch/pytorch_yolov5_trainmkdir -p ./datasets/coco/ln -s /data/datasets/COCO2017/* ./datasets/coco/cd yolov5python -m torch.distributed.launch \ --nproc_per_node 2 \ train.py --data coco.yaml \ --cfg yolov5n.yaml --weights '' \ --epochs 2 \ --batch-size 64 --device mlu
torch.distributed.lauch可以实现创建多个训练进程,每个进程绑定一张加速卡
--nproc_per_node指定需要创建的进程数量
train.py 是对应的包含 DDP 分布式训练的代码
结果如下:
节点A(主节点)
#节点A(主节点)python -m torch.distributed.launch \ --master_port 2289 \ --nproc_per_node 2 \ --nnodes=2 \ --node_rank=0 \ --master_addr="192.168.1.18" \ train.py --data coco.yaml --cfg yolov5n.yaml \ --weights '' --batch-size 64 --device 0,1# 节点Bpython -m torch.distributed.launch \ --master_port 2289 \ --nproc_per_node 2 \ --nnodes=2 \ --node_rank=1 \ --master_addr="192.168.1.18" \ train.py --data coco.yaml --cfg yolov5n.yaml \ --weights '' --batch-size 64 --device 0,1
--nproc_per_node指定需要创建的进程数量
--nnodes节点数,这里是两台机器,所以是2
--node_rank节点rank,对于第一台机器是0,第二台机器是1
--master_addr主节点的IP,就是图中节点A机器的IP
--master_port主节点的端口号
说明:因为没有机器原因,该部分未测试。
备注:代码在相关链接3的:22_pytorch内。
相关链接
1. 在线课程:在线课程 – 寒武纪开发者社区 (cambricon.com)
2. 文档资料:文档中心 – 寒武纪开发者社区 (cambricon.com)
3. 代码库:https://gitee.com/yifanrensheng/cambricon_mlu_learningc
热门帖子
精华帖子





 Ashelly
14 回复
Ashelly
14 回复
 三叶虫
7 回复
三叶虫
7 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读