打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
若是初学者,建议先看前面的,尤其是其中 PyTorch 相关的模块。
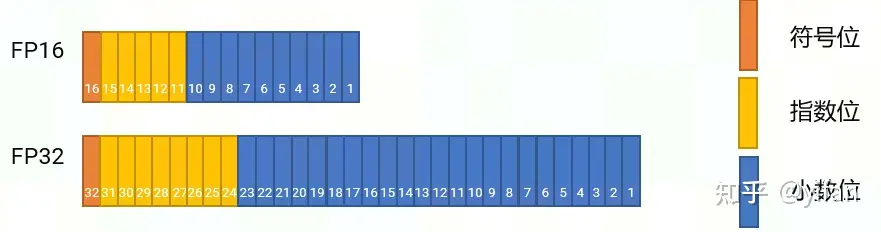
FP16 数据存储一共占用两个字节,表示的范围是 -65504 ~ 65504,其中最小间隔是 2^(-24) (浮点数表示的数据范围里面具体数字不是均匀分布的,不同区间的间隔不一样);FP32 占用 4 个字节,表示的范围大约是 -3.4 * e38 ~ 3.4 * e38,其中最小间隔是 2^(-149)
混合精度的训练方法是指在训练中前向推理、反向求梯度的过程,部分算子使用 FP16 的数据表示,而在卷积核更新的过程中使用 FP32 的数据表示
优势
减少内存占用:FP16 的位宽是 FP32 的一半,因此内存占用也是 FP32 一半
加快通讯效率:占用的位宽少了意味着通讯数据量减小,加快数据的流通
计算效率更高:FP16 占用位宽少,运算比 FP32 快
缺陷:
数据溢出:FP16 表示的数据范围比 FP32 窄很多,计算时超出数据范围,就会出现上溢和下溢
舍入误差:FP16 能表示的数据精度有限,对于 FP32 转 FP16 的场景,小数点后过小的数会自动舍入,造成误差。比如0.11111111在FP32可以正常表示,转换成 FP16 就变成了0.1111
针对上述两个问题,这里对应提出了解决方案:
1)解决数据溢出问题
①给前向计算的 Loss 乘以一个系数 S,使得反向计算的梯度能够在 FP16 的表示范围内。
②反向计算得到梯度
③在更新权值之前,将梯度再除以 S。
2)解决舍入误差问题
①输入 FP16 的数据,部分运算继续使用 FP16 计算,得到 FP16 结果
②将部分运算转成 FP32 类型进行计算,得到 FP32 中间结果
③输出时将所有的 FP32 数据转换为 FP16
需要转成FP32 涉及算子:向量点乘,batch norm,softmax,sigmoid等
1)总体框架
主要根据 autocast和GradScaler实现。
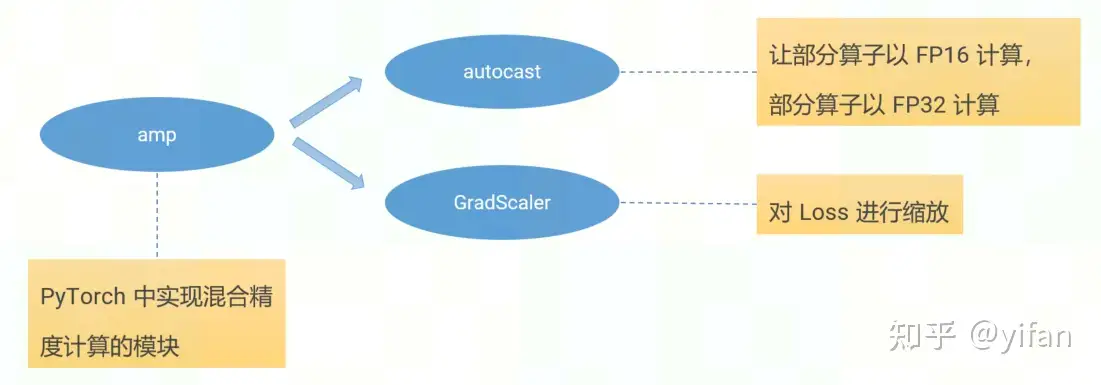
2)autocast

3) GradScaler
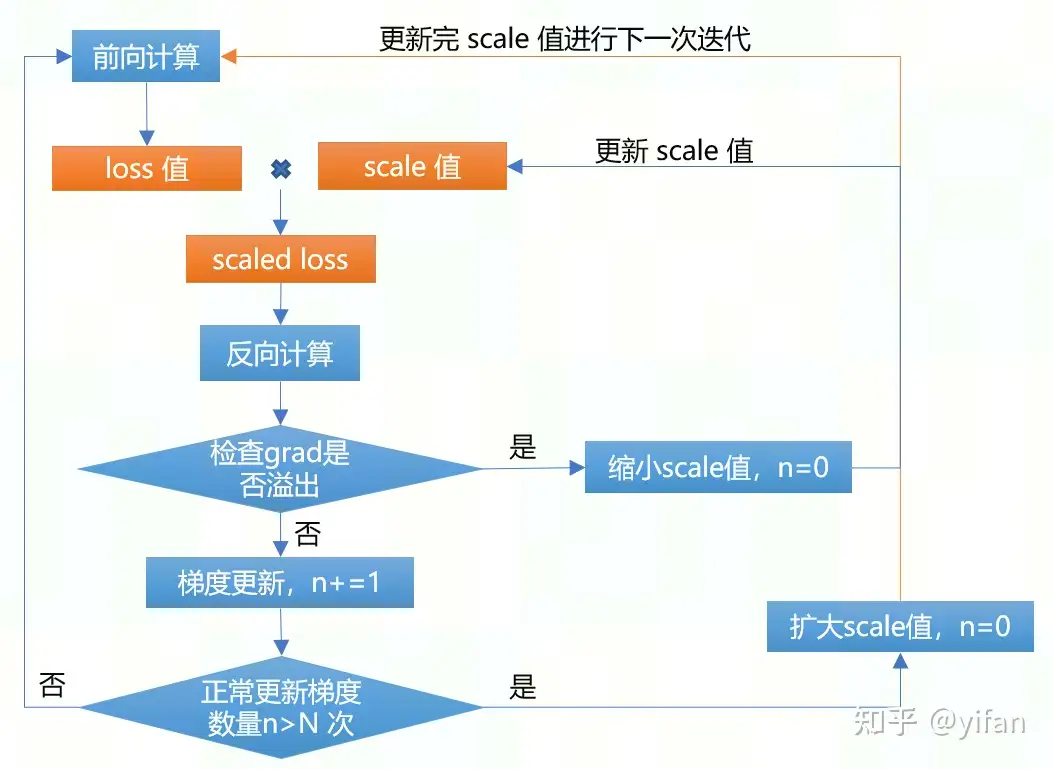
GradScaler主要是解决部分算子采用 FP16 计算时梯度下溢问题。
主要的方式是将 loss 乘上 scale 值,然后反向传播,再判断梯度是否出现溢出,如果出现,则不更新梯度,并缩小 scale 值大小;如果连续 N 次正常梯度更新,则扩大 scale 值。
1) 适配 autocast
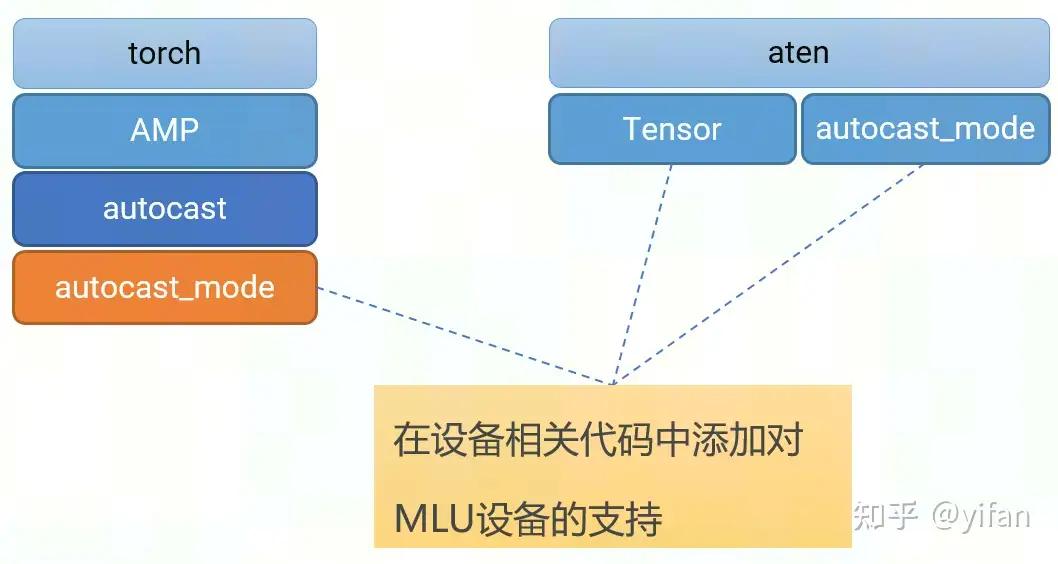
主要是通过修改 PyTorch 框架原生的代码,在 autocast 涉及的代码中,添加对 MLU 设备的支持,让整体代码逻辑可以在MLU平台正常运行。
2) 适配 GradScaler
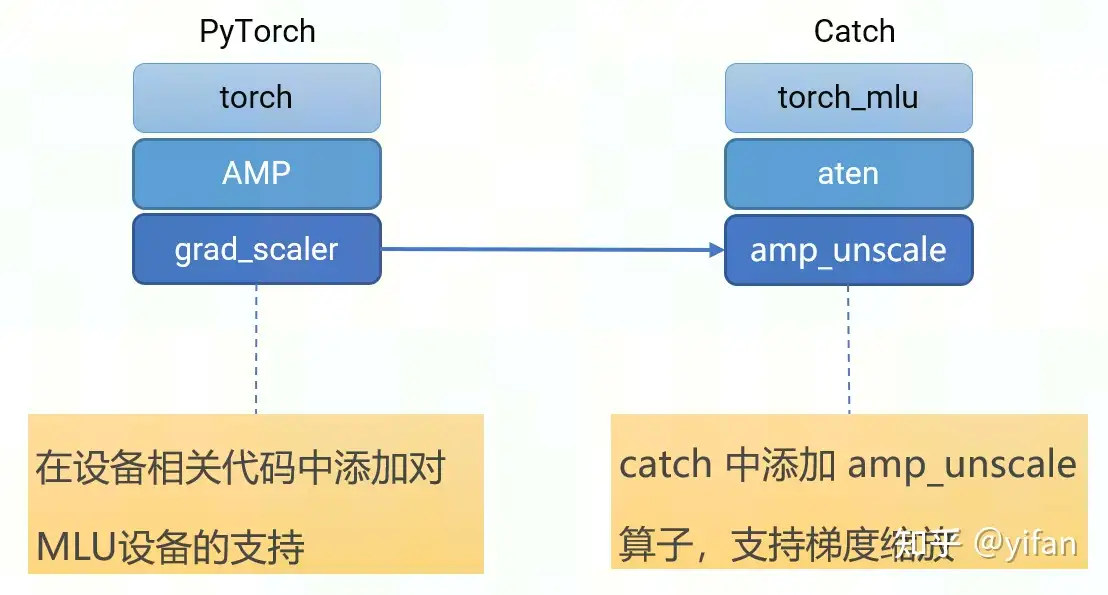
Grad scaler的适配主要有两部分:
一部分和前面 autocast 类似,就是在 gradscaler 内部添加支持 MLU 设备的代码。
另一部分是在 catch 里面添加一个 unscale 算子,用来进行梯度的缩放,这个算子会在 PyTorch 的 gradscaler内部调用。
# 初始化 GradScalerscaler = torch.mlu.amp.GradScaler(enabled=amp)# autocast 实例通过上下文管理器进行混合精度训练with torch.mlu.amp.autocast(amp): pred = model(imgs) loss, loss_items = compute_loss(pred, targets.to(device))# 通过比例因子来缩放 loss,随后进行反向传播scaler.scale(loss).backward()# 梯度除以比例因子。如果没有梯度溢出,则更新梯度scaler.step(optimizer)# 更新比例因子scaler.update()
和上一个课程的代码完全相同。(借用课程代码:拉取寒武纪docker pytorch1.9的镜像包)根据实验准备好环境
git clone cd cambricon_mlu_learning/23_PyTorch/pytorch_yolov5_trainmkdir -p ./datasets/coco/ln -s /data/datasets/COCO2017/* ./datasets/coco/cd yolov5python -m torch.distributed.launch \ --nproc_per_node 2 \ train.py --data coco.yaml \ --cfg yolov5n.yaml --weights '' \ --epochs 2 \ --batch-size 64 --device mlu --pyamp
torch.distributed.lauch可以实现创建多个训练进程,每个进程绑定一张加速卡
--nproc_per_node指定需要创建的进程数量
train.py 是对应的包含 DDP 分布式训练的代码
--pyamp 表示使用混合精度
结果如下:
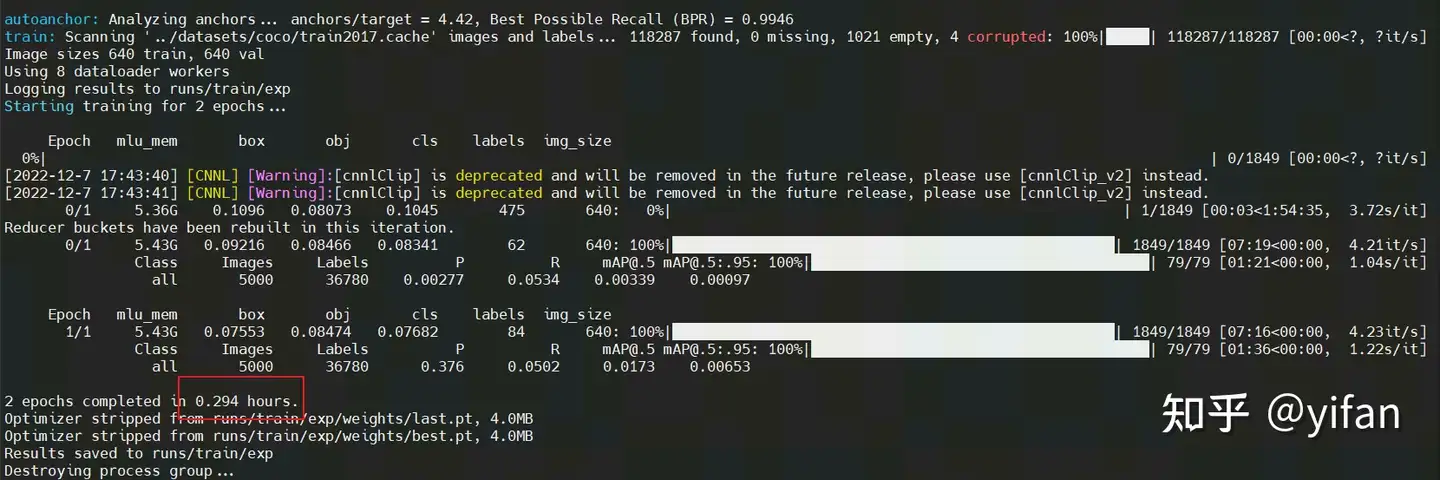
对比上次课用测试的 0.384 小时,这里用时 0.294小时,训练效率有较大提升。
注意:代码在相关链接的:22_pytorch
相关链接
1. 在线课程:在线课程 – 寒武纪开发者社区 (cambricon.com)
2. 文档资料:文档中心 – 寒武纪开发者社区 (cambricon.com)
3. 代码库:https://gitee.com/yifanrensheng/cambricon_mlu_learningc
热门帖子
精华帖子





 Ashelly
14 回复
Ashelly
14 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读