打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
随着社会层面对深度学习处理问题的需求量增大,专精于深度学习的深度学习处理器架构也提上了议程。当下,该架构设计需要解决的两个主要问题是提高处理器的能效比、提高处理器的可编程性。公认条件下,该类处理器被大致分为单核深度学习处理器(DLP-S)以及多核深度学习处理器(DLP-M)。
以单核深度学习处理器为例,大致分为三大模块--控制模块、运算模块、存储模块
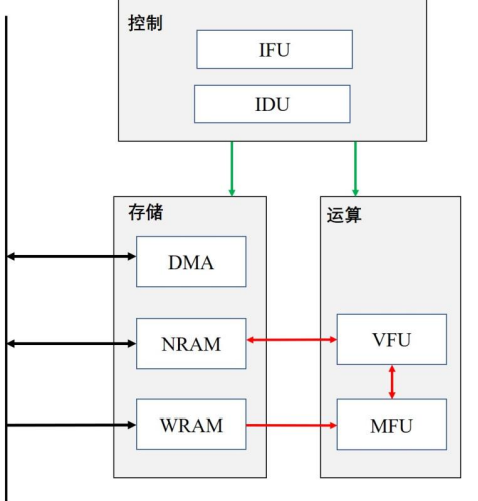
详细执行流程:
1.取指单元(IFU)通过直接内存存取单元(DMA)从DRAM读取程序,然后送入指令译码单元(IDU)进行译码,译码完成后分发到向量运算单元(VFU),矩阵运算单元(MFU)以及DMA中。
2.DMA在接收到访存指令后将会从DRAM读取神经元tensor到神经元存储单元NRAM,读取权值tensor到权重存储单元(WRAM)。
3.VFU接收来自NRAM中的神经元tensor,并对神经元tensor进行预处理,处理完成后发送给MFU
4.MFU接收来自VFU中经过预处理的神经元tensor,并从WRAM读取权重tensor,完成矩阵运算后将结果发送给VFU
5.VFU对神经元tensor进行后处理
6.处理完成后,VFU将运算结果tensor写回NRAM
7.DMA输出神经元tensor,并从NRAM写回DRAM
热门帖子
精华帖子





 Ashelly
14 回复
Ashelly
14 回复
 三叶虫
6 回复
三叶虫
6 回复
 fengyunkai
1 回复
fengyunkai
1 回复



 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读